
提問者:sopnba | 瀏覽 次 | 提問時間:2017-01-02 | 回答數量:1
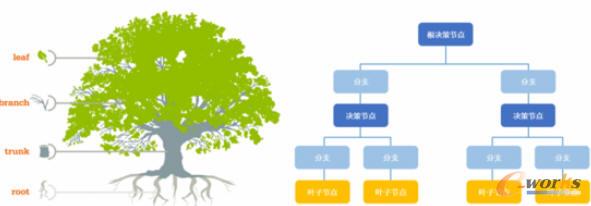 決策樹故名思意是用於基於條件來做決策的,而它運行的邏輯相比一些複雜的算法更容易理解,隻需按條件遍曆樹就可以了,需要花點心思的是理解如何建立決策樹。舉個例子,就好像女兒回家,做媽媽的...
決策樹故名思意是用於基於條件來做決策的,而它運行的邏輯相比一些複雜的算法更容易理解,隻需按條件遍曆樹就可以了,需要花點心思的是理解如何建立決策樹。舉個例子,就好像女兒回家,做媽媽的...

偽裝者crazy
回答數:191 | 被采納數:132

今天給大家帶來主板供電不足到底是什麼原因,主板供電不足用什麼方法有解決,讓您輕鬆解決問題。 在有些時候我們的主板供電不足了,這該怎麼辦呢?下麵就由學習啦小編來為你們簡單的介紹主...
雨林木風win7係統安裝要清理什麼東西 win7係統的清理方法是什麼
今天給大家帶來雨林木風win7係統安裝要清理什麼東西,win7係統的清理方法是什麼,,讓您輕鬆解決問題。 如今絕大多數的用戶都選擇使用Win7係統,它擁有很多新功能、新特...

Win7下Firefox崩潰的原因 Flash 11.3是主要緣由
不少用戶發現自己所用的Firefox瀏覽器有崩潰的狀況,但是又找不出原因,win 7係統看似也沒問題,因此很多人都一頭霧水,其實大家再想想,有可能是Flash 11.3的...
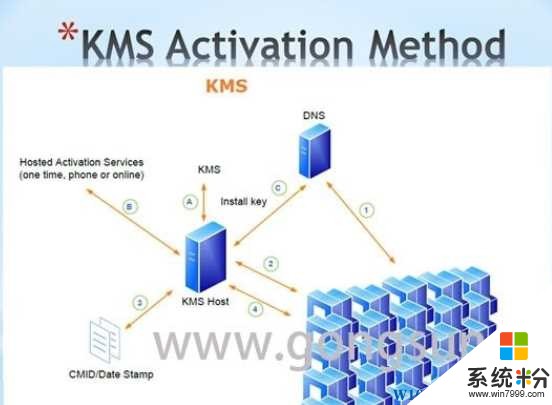
目前來說,除了使用已經激活的Win7/Win8.1升級Win10,或是你有正版的Win7/win8序列號,那麼你可以完美激活Win10,否則你就需要使用KMS激活(Win10激活工...
