
時間:2017-06-22 來源:互聯網 瀏覽量:

今年微軟開發者大會Build 2017上展示了一款Invoke智能音箱,受到了媒體和大眾的廣泛關注。近兩年,不少大公司紛紛涉足該領域,使得智能音箱逐漸成為一款熱門的人工智能家用電器。智能音箱的興起也改變了人們和家用電器之間的“溝通方式”:從動手到動嘴。“播放一些周傑倫的歌”,“明天北京的天氣怎麼樣”… 對著智能音箱說出自己想讓它做的事情,這些之前在科幻電影裏才會出現的橋段逐漸變成了現實。那麼,智能音箱是如何聽懂人類指令的呢?
智能音箱聽懂人類指令的過程,其實就是語義理解的過程,可以被分解成為兩個子任務:意圖識別(intention classification)和實體抽取(entity extraction)。意圖識別的目標是甄別用戶的對話意圖,也就是用戶希望完成一件什麼工作?而實體抽取的目標則是理解用戶對話中所提供的和具體工作相關的參數(實體),例如時間、地點等。比如:“播放一些周傑倫的歌”所對應的意圖是“播放音樂”,其中包含一個藝人實體,實體的值是“周傑倫“。然後根據語義理解的結果,智能音箱就可以做出正確的操作來滿足用戶的需求。

智能音箱的智能程度取決於其能夠理解的意圖以及實體的數量和複雜度,因此如何高效地開發語義理解模塊成為這場智能音箱競賽中的最關鍵一環。然而,開發語義理解模塊需要自然語言處理(NLP)的專業知識和經驗,而這些知識和經驗又需要長年累月的積累,所以可以勝任的開發者鳳毛麟角,廣大非NLP專業的開發者則有心無力。那麼如何幫助非NLP專業的開發者解決自然語言理解這一開發瓶頸呢?
微軟自然語言理解平台 - LUIS
LUIS (Language Understanding Intelligent Service,https://www.luis.ai) 是微軟發布的麵向開發者的自然語言語義理解模塊開發服務。微軟亞洲研究院大數據挖掘組負責研發了LUIS的新一代算法。LUIS的使命是讓非NLP專業的開發者能夠輕鬆地創建和維護高質量的自然語言理解模型,並無縫對接到相關的智能應用當中。
通過LUIS平台,非NLP專業的開發者可以輕鬆創建一個LUIS App,並通過標注所期望的輸入(自然語言指令)和輸出(意圖和實體)來進一步“培養” 它。在整個開發過程中,開發者並不需要了解背後算法的細節,隻需要清晰地定義自己需要讓機器理解的用戶意圖和實體即可。下麵我們就來介紹一下LUIS的開發流程和其背後的技術細節。
LUIS的開發流程
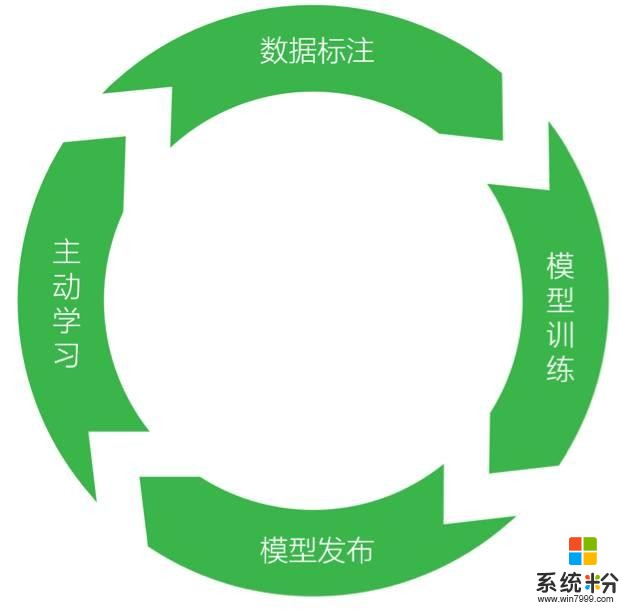
LUIS的開發流程更像是一個教學過程:開發者是老師,LUIS App是學生。老師通過不停地告知學生正確的語義解析結果來完成教學。一個好的教學過程是一個“訓練+實踐”的閉環:標注一定量的起始數據;訓練得到語義理解模型;對模型進行必要的測試;發布模型並應用到真實用戶場景;甄選應用日誌中的語句;繼續標注並更新模型。這個過程周而複始,通過不停地迭代開發,不停地改善理解模型,使其越來越接近人類的理解能力。
數據標注
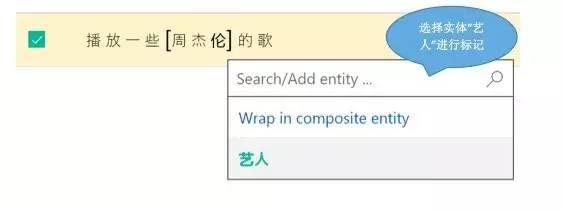
LUIS開發者可以在界麵上輕鬆地進行在線數據標注。首先,在對應的用戶意圖中輸入自然語言指令,例如:在“播放音樂” 中輸入一句“播放一些周傑倫的歌” ;然後,通過鼠標選取實體並指定類型,例如:選擇“周傑倫”,指定其為藝人實體。LUIS支持標注數據的導入和導出,因此如果開發者已經有標注過的數據,那麼就可以直接轉換為LUIS的標注數據JSON格式進行導入。
模型訓練
LUIS的模型訓練過程極其簡單,開發者隻需點擊一下 “訓練” 按鈕,LUIS便會提供一套全自動的機器學習解決方案:應用深度學習算法,預設絕大部分常用的文本特征,並加入從大數據語料中提取出的語義特征,從而為不同的語義理解場景提供通用的機器學習解決方案。訓練的時間會因為標注數據量的不同而各異,標注數據越多,訓練所需的時間越長。同時,訓練時間還與LUIS App所支持的意圖和實體個數相關,意圖和實體越多,訓練時間也越長。
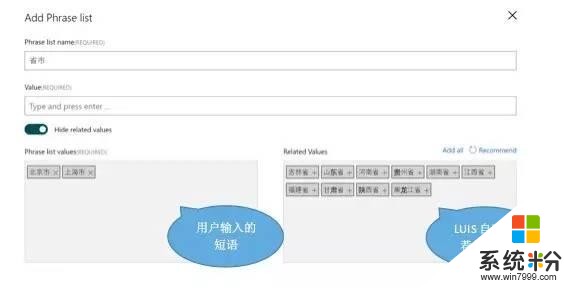
除了預設的特征之外,LUIS還允許用戶自定義新的語義特征,包括短語列表特征(phrase list)和正則表達式特征(regular expression)。前者主要用於定義若幹短語列表,且通常每一個列表中的短語均可相互替換,而後者主要用於定義若幹正則表達式。通過應用這些用戶自定義的短語列表特征和模式特征,再結合已有的標記數據,LUIS的深度學習模型就可以增強其自身的泛化能力,從而能夠以更少的標記數據訓練得到合適的模型,進而達到更好的預測效果。
在定義短語列表特征的過程中,LUIS通過其語義詞典(semantic dictionary)挖掘技術,能夠根據用戶輸入的若幹短語,自動從海量的網絡數據中智能地發現與其相似的短語,並推薦給用戶,有效地提升了用戶定義短語列表特征的效率。目前該推薦功能主要麵向英文語言,我們也正在致力於將其推廣到包括中文在內的其他語言。
模型發布
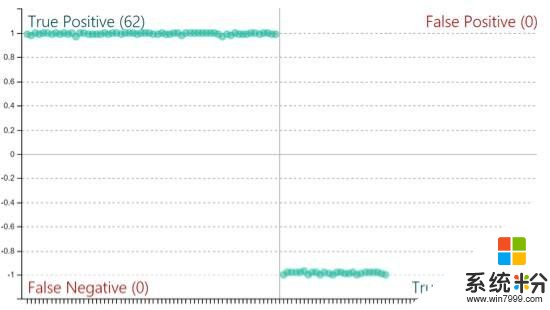
對於訓練完成的模型,開發者可以對其進行性能測試。LUIS為開發者提供了兩種在線測試方法:交互式測試和批量測試。使用交互式測試時,開發者可以直接輸入自然語言語句,然後目測模型輸出是否和預期一致。而使用批量測試時,開發者需要上傳一份測試數據,LUIS會通過比對模型輸出和測試數據的期望輸出來給出更為具體的精度和召回率等統計數據,並且LUIS還會對每一項意圖和實體的結果繪製出Confusion Matrix來幫助開發者找到有待提高的實例。通過測試的LUIS App隻需輕輕一點就可以發布到微軟的Azure雲平台上,變成一個立即可用的API。開發者通過Http的get方法,就可以將開發的LUIS App接入到其他應用中。
主動學習
LUIS App的開發是一個不停迭代的過程,通過不停地增加標注數據來讓其變得更加智能。同時,LUIS希望最大化開發者的標注收益,也就是說,通過更少的標注來獲得更大的模型性能提升。發布之後的App會逐漸積累真實用戶的請求日誌,然後通過主動學習(Active Learning)從這些日誌中尋找出對於模型更為有益的語句讓開發者標注。實驗表明,通過甄選數據的方式,模型的精度和召回率的提升都明顯高於隨機選擇標注數據的方式,這讓開發過程變得事半功倍。也正是通過主動學習,LUIS對於訓練數據的數量要求大大降低,可以在較少的訓練數據下獲得不錯的性能。
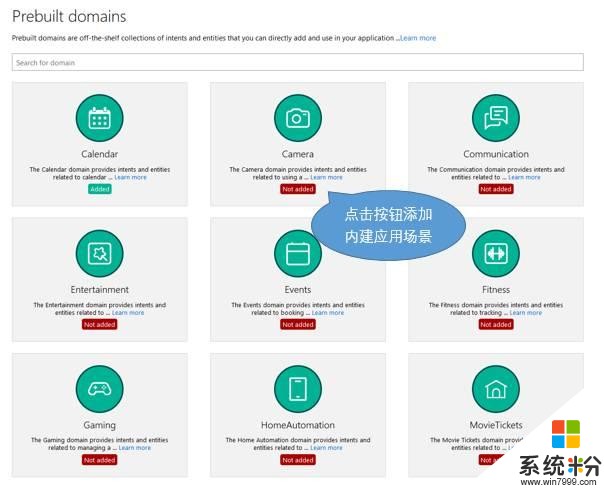
豐富的內建工具
為了幫助用戶快速構建其應用,LUIS提供了一係列的內建工具,包括內建應用場景(prebuilt domain)和內建實體(prebuilt entities)。
內建應用場景包括日曆(calendar)、天氣(weather)等多個較為通用的類別,每一個內建場景均包含了預定義好的意圖和實體,用戶可直接添加合適的內建場景到其應用中,並進行修改和擴展。
內建實體目前主要包括日期與時間(date time)、基數詞(number)、序數詞(ordinal)、百分數(percentage)、年齡(age)、溫度(temperature)等多種應用較為廣泛的類別,用戶可以通過勾選添加所需的內建實體到其應用中,無需從頭開始自行創建。事實上,大部分LUIS內建實體同時具有識別和解析的功能,能夠從輸入的語句中抽取出相應的實體內容,並將其解析為標準格式,例如,基數詞可以將識別出的3k解析為3000的標準數字形式,便於用戶後續的處理。
微軟自然語言理解平台LUIS讓廣大非NLP專業的開發者也可以加入到語義理解模型的開發隊伍中來,從而真正讓各種應用都實現智能化,創造出更多的用戶價值。我們也將不懈努力,將LUIS做的更加易用和高效,讓它成為開發者的一款利器。
你也來試試看?官方網站:https://www.luis.ai/(點擊【閱讀原文】或將網址複製至瀏覽器中打開)
歡迎大家在留言區與我們互動,分享你對LUIS平台的想法、反饋和建議~
大數據挖掘組
微軟亞洲研究院大數據挖掘組致力於從大數據中挖掘信息構建海量知識圖譜,以提高人工智能應用中的知識推理和自然語言理解能力。大數據挖掘組的研究方向包括數據挖掘、大數據、深度學習、自然語言處理、智能聊天機器人等。十多年來,該組成員的研究成果對微軟的許多重要產品及應用產生了深刻影響,包括人立方、微軟學術搜索、讀心機器人、微軟知識圖譜(Satori)、微軟自然語言理解平台LUIS等。
你也許還想看:
●企業大數據挖掘:為員工構建職場知識圖譜
,共建交流平台。來稿請寄:msraai@microsoft.com。 微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。
微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。




















