
時間:2017-06-14 來源:互聯網 瀏覽量:

周明 微軟亞洲研究院副院長
近日,微軟亞洲研究院副院長周明在「自然語言處理前沿技術分享會」上,與大家講解了自然語言處理(NLP)的最新進展,以及未來的研究方向,以下內容由CSDN記者根據周明博士的演講內容編寫,略有刪減。
周明博士於1999年加入微軟亞洲研究院,不久開始負責自然語言研究組。近年來,周明博士領導研究團隊與微軟產品組合作開發了微軟小冰(中國)、Rinna(日本)、Zo(美國)等聊天機器人係統。周明博士發表了120餘篇重要會議和期刊論文(包括50篇以上的ACL文章),擁有國際發明專利40餘項。
微軟亞洲研究院在機器翻譯、中國文化、聊天機器人和閱讀理解的最新進展
機器翻譯
今年微軟首先在語音翻譯上全麵采用了神經網絡機器翻譯,並拓展了新的翻譯功能,我們叫做Microsoft Translator Live Feature(現場翻譯功能),在演講和開會時,實時自動在手機端或桌麵端,把演講者的話翻譯成多種語言。
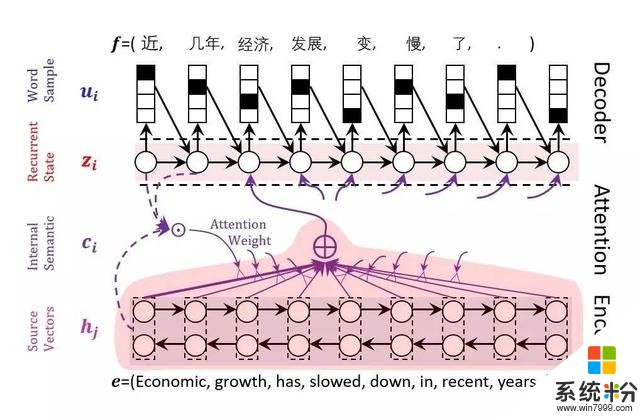
圖1 神經網絡機器翻譯
圖1概括了神經網絡機器翻譯,簡要的說,就是對源語言的句子進行編碼,一般都是用長短時記憶(LSTM)進行編碼。編碼的結果就是有很多隱節點,每個隱節點代表從句首到當前詞彙為止,與句子的語義信息。基於這些隱節點,通過一個注意力的模型來體現不同隱節點對於翻譯目標詞的作用。通過這樣的一個模式對目標語言可以逐詞進行生成,直到生成句尾。中間在某一階段可能會有多個翻譯,我們會保留最佳的翻譯,從左到右持續。
這裏最重要的技術是對於源語言的編碼,還有體現不同詞彙翻譯的,不同作用的注意力模型。我們又持續做了一些工作,引入了語言知識。因為在編碼的時候是僅把源語言和目標語言看成字符串,沒有體會內在的詞彙和詞彙之間的修飾關係。我們把句法知識引入到神經網絡編碼、解碼之中,這是傳統的長短時記憶LSTM,這是模型,我們引入了句法,得到了更佳的翻譯,這使大家看到的指標有了很大程度的提升。
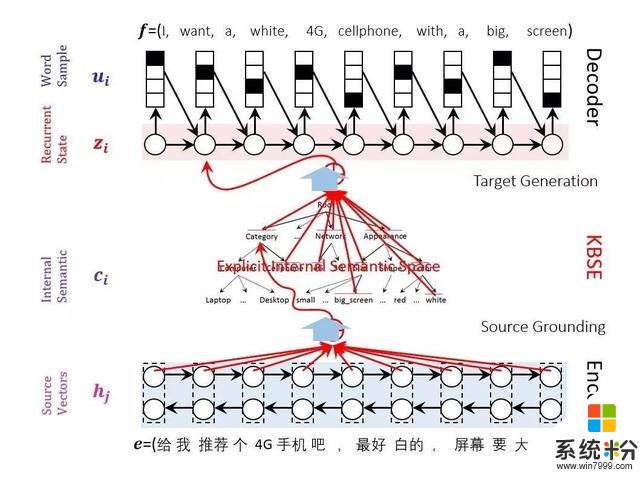
圖2 將知識圖譜納入傳統的神經網絡機器翻譯中
此外,我們還考慮到在很多領域是有知識圖譜的,我們想把知識圖譜納入到傳統的神經網絡機器翻譯當中,來規劃語言理解的過程。我們的一個假設就是雖然大家的語言可能不一樣,但是體現在知識圖譜的領域上可能是一致的,就用知識圖譜增強編碼、解碼。具體來講,就是對於輸入句子,先映射到知識圖譜,然後再基於知識圖譜增強解碼過程,使得譯文得到進一步改善。
以上兩個工作都發表在本領域最重要的會議ACL上,得到很多學者的好評。
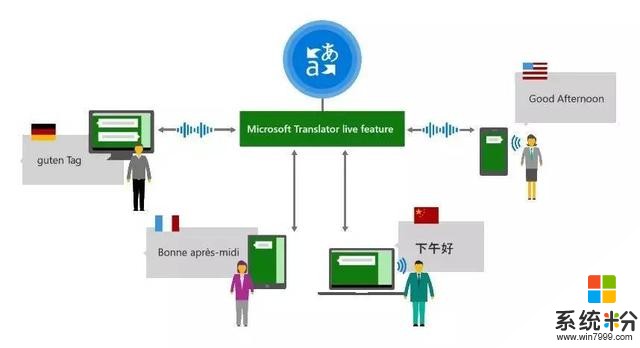
圖3 Microsoft Translator Live Feature工作場景
中國文化
大家會說,中國文化和人工智能有什麼關係?中國文化最有代表性的是對聯、詩歌、猜謎語等等,它怎麼能夠用人工智能體現呢?好多人一想這件事就覺得不靠譜,沒法做。但是我們微軟亞洲研究院就利用然語言處理的技術,尤其是機器翻譯的經驗,果斷進軍到中國文化裏,這個在全世界獨樹一幟。
在2004年的時候,當時我們的沈向洋院長領導我們做了一個微軟對聯:用戶輸入上聯,電腦自動對出下聯,語句非常工整,甚至更進一步把橫批對出來。這個係統在當時跟新浪進行了合作,做成了一個手機遊戲,用戶可以通過發短信的方式,將上聯發過去,然後通過短信接收下聯。當時大家都覺得很有意思。微軟對聯也是世界上第一次采用機器翻譯的技術來模擬對聯全過程。過去也有人做對聯遊戲,都是用規則的方法寫很多很多的語言學規則,確保什麼樣的詞跟什麼樣的詞對,並符合對仗、平仄一堆語言學的規則,但是實際效果不好,也沒有人使用。
我們把機器翻譯技術巧妙用在中國文化上,解決了這個問題。在微軟對聯的基礎上,我們繼續去嚐試其他的中國文化,其中有一個特色就是字謎。
我們小時候都愛猜字謎,領獎品。字謎是給你謎麵讓你猜謎底。當然也可以反過來,給定一個謎底,讓你出謎麵。現在,已經可以用電腦來模擬整個猜字謎和出字謎的過程了,我們也把這個功能放在了微軟對聯的網站上。
往後,更進一步,我們還會用人工智能技術來發展中國最經典的文化,包括絕句和律詩等。例如宋詞有長短句,我們也可以用同樣的技術來創作律詩、絕句和宋詞。
最近,微軟亞洲研究院的主管研究員宋睿華博士就在用這種神經網絡的技術來進行詩歌的創作。這件事非常有創意:用戶提交一個照片,讓係統進行,然後變成一首詩,自由體的詩。寫詩是很不容易的,因為要體現意境。你說這是山,這是水,這不叫詩;詩歌必須要升華、凝練,用詩的語言來體現此時的情或者景,由景入情,由情入景,這才是詩。
不久前,微軟小冰發布了微軟小冰寫詩的技能,引起了很多人的關注。我們也在此基礎上展示其他的中國文化,把人工智能和中國文化巧妙結合起來,弘揚中國文化。
對話即平台
“對話即平台”英文叫做“Conversation as a Platform (CaaP)”。2016年,微軟首席執行官薩提亞在大會上提出了CaaP這個概念,他認為繼圖形界麵的下一代就是對話,它會對整個人工智能、計算機設備帶來一場新的革命。

圖4 通用對話引擎架構
為什麼要提到CaaP這個概念呢?我個人認為,有兩個原因。
● 源於大家都已經習慣用社交手段,如微信、Facebook與他人聊天的過程。我們希望將這種通過自然的語言交流的過程呈現在當今的人機交互中,而語音交流的背後就是對話平台。
● 現在大家麵對的設備有的屏幕很小,有的甚至沒有屏幕,所以通過語音的交互,更為自然直觀的。因此,我們是需要對話式的自然語言交流的,通過語音助手來幫忙完成。
而語音助手又可以調用很多Bot,來完成一些具體的功能,比如說定杯咖啡,買一個車票等等。芸芸眾生,有很多很多需求,每個需求都有可能是一個小Bot,必須有人去做這個Bot。而於微軟而言,我們作為一個平台公司,希望把自己的能力釋放出來,讓全世界的開發者,甚至普通的學生就能開發出自己喜歡的Bot,形成一個生態的平台,生態的環境。
如何從人出發,通過智能助理,再通過Bot體現這一生態呢?微軟在做CaaP的時候,實際上有兩個主要的產品策略。
第一個是小娜,通過手機和智能設備介入,讓人與電腦進行交流:人發布命令,小娜理解並執行任務。同時,小娜作為你的貼身處理,也理解你的性格特點、喜好、習慣,然後主動給你一些貼心提示。比如,你過去經常路過某個地方買牛奶,在你下次路過的時候,她就會提醒你,問你要不要買。她從過去的被動到現在的主動,由原來的手機,到微軟所有的產品,比如Xbox和Windows,都得到了應用。現在,小娜已經擁有超過1.4億活躍用戶,在數以十億級計的設備上與人們進行交流。現在,小娜覆蓋的語言已經有十幾種語言,包括中文。小娜還在不斷發展,這背後有很多自然語言技術來自微軟研究院,包括微軟亞洲研究院。
第二個就是小冰。它是一種新的理念,很多人一開始不理解。人們跟小冰一起的這種閑聊有什麼意思?其實閑聊也是人工智能的一部分,我們人與人見麵的時候,寒喧、問候、甚至瞎扯,天南海北地聊,這個沒有智能是完成不了的,實際上除了語言方麵的智能,還得有知識智能,必須得懂某一個領域的知識才能聊起來。所以,小冰是試圖把各個語言的知識融彙貫通,實現一個開放語言自由的聊天過程。這件事,在全球都是比較創新的。現在,小冰已經覆蓋了三種語言:中文、日文、英文,累積了上億用戶。很多人跟它聊天樂此不疲,而平均聊天的回數多達23輪。這是在所有聊天機器人裏麵遙遙領先的。而平時聊天時長大概是25分鍾左右。小冰背後三種語言的聊天機器人也都來自於微軟亞洲研究院。
無論是小冰這種閑聊,還是小娜這種注重任務執行的技術,其實背後單元處理引擎無外乎就三層技術:
● 通用聊天,需要掌握溝通技巧、通用聊天數據、主題聊天數據,還要知道用戶畫像,投其所好。
● 信息服務和問答,需要搜索的能力,問答的能力,還需要對常見問題表進行收集、整理和搜索,從知識圖表、文檔和圖表中找出相應信息,並且回答問題,我們統稱為Info Bot。
● 麵向特定任務的對話能力,例如定咖啡、定花、買火車票,這個任務是固定的,狀態也是固定的,狀態轉移也是清晰的,那麼就可以用Bot一個一個實現。你有一個調度係統,你知道用戶的意圖就調用相應的Bot 執行相應的任務。它用到的技術就是對用戶意圖的理解,對話的管理,領域知識,對話圖譜等等。
實際上,人類擁有這全部三個智能,而且人知道什麼時候用什麼智能,就是因為最上頭,還有一個調度係統。你跟我閑聊的時候,我就會跟你閑聊;你跟我嚴肅地問問題,那麼我就會回答你的問題。通過一個調度係統,可以想象,我們在做人機對話的時候,其實是在根據用戶的提問調用不同的引擎,再根據不同的意圖調用不同的Bot。這樣整體來實現一個所謂的人機交互全過程。這背後的技術由不同的研究員分別去進行實施,然後再整體通過跟產品組合作體現一個完美的產品流程。
微軟想把有關的能力釋放給全世界,讓每個人都能夠體驗人工智能的好處,讓開發者開發自己的Bot。但是開發者的機器不懂自然語言,怎麼辦呢?我們就通過一個叫Bot Framework的工具、平台來實現。
任何一個開發者隻用幾行代碼就可以完成自己所需要的Bot。這裏有一個簡單的例子,這個人想做一個披薩的Bot,他用Bot的框架,這幾行語句填入相應的知識,相應的數據,就可以實現一個簡單的定披薩的Bot。你可以想象很多小業主,沒有這種開發能力,但是就是可以簡單操作幾下,就可以做一個小Bot吸引來很多客戶。
這裏麵有很多關鍵技術。微軟有一個叫做LUIS(Language Understanding Intelligent Service)的平台,提供了用戶的意圖理解能力、實體識別能力、對話的管理能力等等。比如說這句話“read me the headlines”,我們識別的結果是他想做朗讀,內容就是今天的頭條新聞。再比如說“Pause for 5 minutes”,我們理解它的意思是暫停,暫停多長時間?有一個參數:5分鍾。所以,通過LUIS,我們可以把意圖和重要的信息抽取出來,讓後麵Bot來讀取。
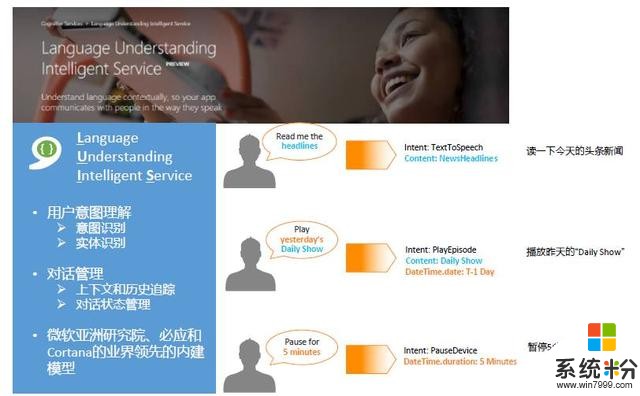
圖5 微軟語言理解服務
微軟的聊天對話技術也在與很多企業合作,賦能這些企業。比如,我們跟敦煌研究院合作。敦煌研究院提供出數據,我們則把我們的引擎加上去,很快就建立了一個敦煌研究院的客服係統,借助敦煌研究院公眾號,可以讓用戶和它聊與敦煌有關的事。用戶也可以問問題,例如敦煌研究院什麼時候開門、有什麼好吃的,他可以把聊天、對話都集成在一個平台上,發揮人工智能在公眾號上的作用。
圖6 敦煌公眾號客服係統
閱讀理解
閱讀理解顧名思義就是給你一篇文章,看你理解到什麼程度。人都有智能,而且是非常高的智能。除了累積知識,還要懂一些常識。具體測試你的閱讀能力、理解能力的手段,一般都是給一篇文章,再你一些問題。你能來就說明你理解了,答不上來就說明你不理解。對電腦的測試也是這樣。

圖7 萊茵河介紹
我給大家舉個例子,說明一下閱讀理解。圖7中,這一段話的大意是在介紹萊茵河,它流經哪些國家,最終在哪裏注入大海。萊茵河畔最大的城市是德國科隆。它是中歐和西歐區域的第二長河流,僅次於多瑙河之後,約1230公裏。然後,我們問的問題是,什麼河比萊茵河長?當你讀完了這段話,你就要推斷,“after”在這裏是什麼意思,從而才能得出正確答案是多瑙河。電腦要做這道題,實際上要仔細解析很多問題,最終才能作出回答。
未來5-10年,NLP將走向成熟
最後,再介紹一下我對自然語言處理目前存在的問題以及未來的研究方向的一些考慮,供大家參考。
● 隨著大數據、深度學習、雲計算這三大要素推動,所謂認知智能,尤其是語言智能跟感知智能一樣會有長足的發展。你也可以說,自然語言處理迎來了60餘年發展曆史上最好的一個時期,進步最快的一個時期,從初步的應用到搜索、聊天機器人上,到通過對上下文的理解,知識的把握,它的處理能力得到長足的進步。具體來講,我認為,口語機器翻譯肯定會完全普及,將來我認為它就是手機上的標配。任何人出國,無論到了哪個國家,拿起電話來你說你的母語,跟當地人交流不會有太大的問題,而且是非常自如的過程,就跟你打電話一樣。所以,我認為口語機器翻譯會完全普及。雖然這不意味著同聲翻譯能徹底顛覆,也不意味著這種專業領域的文獻的翻譯可以徹底解決;但我認為還是會有很大的進展。
● 自然語言的會話、聊天、問答、對話達到實用程度。這是什麼意思?這意味著在常見的場景下,通過人機對話的過程完成某項任務。這個是可以完全實現,或者跟某個智能設備進行交流,比如說關燈、打開電腦、打開紗窗這種一點問題都沒有,包括帶口音的說話都可以完全聽懂。但是同樣,這也不代表任何話題、任何任務、用任何變種的語言去說都可以達到。目前離那個目標還很遠,我們也在努力。
● 智能客服加上人工客服完美的結合,一定會大大提高客服的效率。我認為很多重複的客服工作,比如說問答,還有簡單的任務,基本上人工智能都可以解決。但是複雜的情況下仍然不能解決。所以,它實際上是人工智能跟人類智能完美結合來提高一個很好的生產力,這個是沒有問題的。
● 自動寫對聯、寫詩、寫新聞稿和歌曲等等,今天可能還是一個新鮮的事物,但是5到10年一定都會流行起來,甚至都會用起來。比如說寫新聞稿,給你一些數據,這個新聞稿草稿馬上就寫出來,你要做的就是糾正,供不同的媒體使用等。
● NLP將推動語音助手、物聯網、智能硬件、智能家居的普及。
● NLP與其他AI技術一起在金融、法律、教育、醫療等垂直領域將得到廣泛應用。
但是,我們也清醒地看到,雖然有一些很好的預期,但是自然語言處理還有很多很多沒有解決的問題。以下幾個我認為比較重要的。
1.通過用戶畫像實現個性化服務。現在自然語言處理基本上用戶畫像用得非常非常少。人與人的對話,其實是對不同的人說不同的話,因為我們知道對話的人的性格、特點、知識層次,我了解了這個用戶,知道用戶的畫像,那麼在對話的時候就會有所調整。目前來講,我們還遠遠不能做到這一點。
2.通過可解釋的學習洞察人工智能機理。現在自然語言處理跟其他的人工智能一樣,都是通過一個端對端的訓練,而其實裏麵是一個黑箱,你也不知道發生了什麼,哪個東西起作用,哪個東西沒有起作用。我們也在思考,有沒有一種可解釋的人工智能,幫助我們知道哪些地方發揮了作用,哪些地方是錯的,然後進行修正,快速調整我們的係統。目前還沒有針對這個問題很好的解決方案,盡管有一些視覺化的工作,但是都比較粗淺,還沒有達到最精準的判定和跟蹤。
3.通過知識與深度學習的結合提升效率。所謂知識和深度學習的結合,有可能很多情況下是需要有人類知識的。比如說客服,是有一些常見處理過程的。那麼出現問題我該怎麼解決?這些知識如何跟數據巧妙結合,從而加快學習的過程、提高學習的質量,這也是比較令人關注的。
4.通過遷移學習實現領域自適應。如果們想翻某一個專業領域,比如說計算機領域,可能現有的翻譯工具翻得不好。所以大家都在研究,有沒有一種辦法,能夠幫助機器進行遷移學習,能夠更好的運用到語音自適應上。
5.通過強化學習實現自我演化。這就是說我們自然語言係統上線之後有很多人用,得到了有很多人的反饋,包括顯示的反饋、隱式的反饋,然後通過強化學習不斷的提升係統。這就是係統的自我演化。
6.最後,我認為也是非常關鍵的,通過無監督學習充分利用未標注數據。現在都依賴於帶標注的數據,沒有帶標注的數據沒有辦法利用。但是很多場景下,標注數據不夠,你找人工標注代價又極大。那麼如何用這些沒有標注的數據呢?這就要通過一個所謂無監督的學習過程,或者半監督的學習過程增強整體的學習過程。這裏也是目前研究上非常令人關注的。
【本文由CSDN根據周明博士的演講內容編寫,已獲授權轉載】
你也許還想看:
,共建交流平台。來稿請寄:msraai@microsoft.com。 微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。
微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。



















