
時間:2017-05-31 來源:互聯網 瀏覽量:

毫不誇張地說,成為機器智能研究員真的是一件令人激動的事情。最近,機器學習(ML)和人工智能(AI)取得的一係列成功——從實現人機平等的語音識別到打敗世界冠軍的棋盤遊戲,都表明了這些領域的發展前景。
然而,這些成功大多數僅限於在封閉的虛擬世界中,這種“封閉”世界的操作為AI agents提供了兩個顯著的優勢。首先,這些AI agent隻需要針對具體任務來設計操作——一個玩棋盤遊戲的智能agent隻需要理解下一步最好的走向策略是什麼,而不需要其他的。其次,這些係統中的大多數AI程序都享受到豐富的資源——通過收集得到的經過注釋的、接近無限的訓練數據。無論是從繁瑣的過去經驗積累中,還是通過自我學習的技術都可以得到這些“大數據”。
那麼,現在我們來考慮一下機器人、物聯網(IoT)設備以及在現實世界中運行和執行任務的自主車輛設備,這超出了封閉式範式的狹義環境的假設。這些設備不僅要完成首要任務,還必須生活在一個開放世界中,接受著各種未建模的外部現象的挑戰。除此之外,這些係統還需要通過最少量的訓練來適應和學習。鑒於需要大量的技術的訓練數據來獲得成功的範例,例如利用強化學習、示範學習和遷移學習的設備來說,開放環境尤其具有挑戰性。
雖然已經有了綜合AI的例子,通過幾個單獨的組件可以搭建人工智能係統,但是我們仍然需要探索一些基本原理,從而使核心架構可以構建一個可以在現實世界中具有可適應性和智能性的係統。

AirSim的快照顯示了在城市環境中飛行的飛機。插圖顯示實時生成的深度,對象分割和前置攝像頭流。
在微軟的研究部門,就正將機器人和網絡物理係統相關領域的提上議程,其目標是探索和揭示統一的算法和技術結構,從而實現這種現實世界的人工智能。微軟的信念是,在基礎層麵解決三個關鍵方麵,以便實現在現實世界中建立AI agents的下一次重大飛躍。這三個方麵分別是結構,模擬和安全,正如下述:
結構
結構:解決數據稀缺問題的一個方法是使用真實世界的統計和邏輯結構。比如環境中的秩序(如交通規則,自然規律以及我們的社交圈)可以非常有助於消除現實世界中所麵臨的不確定性。例如,我們最近在非確定性無悔重規劃(No-Regret Replanning Under Uncertainty)的工作,顯示了現有的機器人路徑規劃算法是如何利用風的統計結構,在數據不足的情況下來確定如何接近最優路徑的。
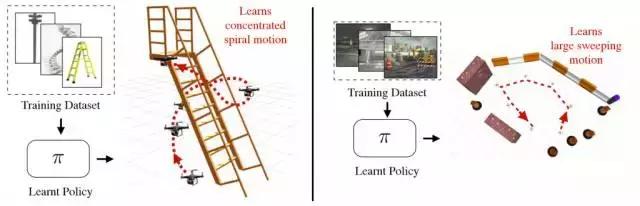
該圖顯示了將其推廣到不同結構化環境的能力。使用相同潛在機製的飛行四旋翼機構,通過學習學習來避免在不同環境下的自主障礙。
雖然傳統方法已經將這種關係編碼為統計學或邏輯模型,但在現實世界中真正運作的能力,卻需要有機會才能有效地推斷出來。而我們最近在學習用模仿進行探索(Learning to Explore with Imitation)方麵的工作則朝著這個方向邁出的重大一步——隱含地了解世界結構的同時還在學習政策。這種方法的一個關鍵好處是在不需要關於結構知識的明確編碼的情況下,允許用算法在多個問題域中進行泛化。我們在即將發表的RSS論文(RSS paper)中,會進一步分析了用模仿學習來解決馬爾可夫決策過程(MDPs)的理論基礎。
模擬
模擬:模擬現實世界本身就是一個完整的AI任務,但即使是對現實的近似也將成為這個龐大追求中的基本組成部分。我們公布的開源模擬項目就是旨在彌合這種模擬到現實的差距。不僅使用模擬來生成有意義的訓練數據,而且我們還認為它是AI agent的一個組成部分,作為端口,來執行和驗證他們計劃在不確定世界中采取的所有行動。而這類似於在某些困難情況下,人類在行動之前是進行思考和模擬其行為的後果的。AI agents需要自我反省的能力,並可以從虛擬思維過程中學習。這些計劃或政策的執行軌跡有助於驗證軌跡軌跡的有效性和正確性。在這個根本問題上成功的關鍵,是將所有發生在模擬中的學習和推論轉移到現實世界中的能力。我們還在繼續投資和探索這個激動人心的模擬到真實(sim-to-real )AI的領域。
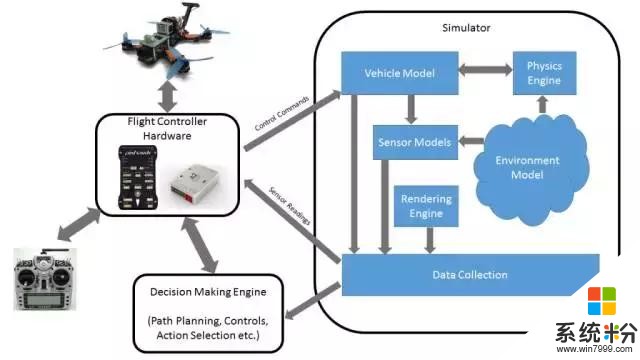
描述核心組件及其相互作用的仿真係統架構。
安全
安全:當AI agent決定執行行動時,從AI agent的角度以及生活環境的角度來考慮安全性是至關重要的。導致不安全行為的一個可能是機器學習和感知係統不能在環境中完全“理解”不確定性。眾所周知,機器學習係統並不傻,因此我們最近進行的工作——安全任務規劃的快速二階錐編程(Fast Second-order Cone Programming for Safe Mission Planning)旨在實時實現可能采取的安全行動。其核心思想是利用機器學習方法產生了不確定性的幾何結構,然後通過沃爾夫算法(Wolfe’s algorithm)優化安全幅度,這是快速且高效的。同樣,這些想法也被進一步擴展,從而獲得安全的,基於bandit的算法。我們正在與各位同事合作,探索安全的多方麵事宜,諸如網絡安全,驗證和測試等。
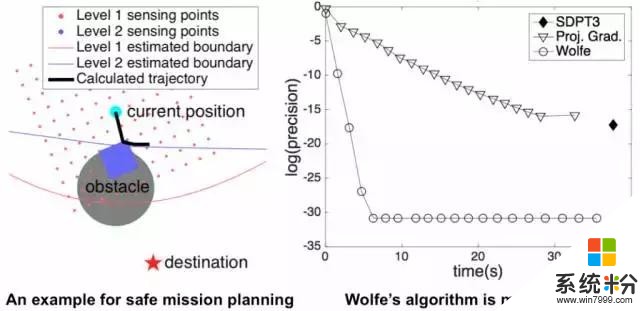
我們展示了機器人需要避免障礙的假想場景。這種不完善的傳感器提供了一個係統,此係統對傳感的安全區域具有堅定的信念(藍色和紅線)。機器人決定考慮推論中的所有不確定性,並以非常高的概率確定安全的軌跡(黑色)。左圖顯示了所提出的方法(Wolfe的算法)非常有效,從而實現了實時決策。
最後,我們想以第一人稱視角(FPV)的無人賽車事件為例子來總結,這些賽車事件越來越受歡迎。一般,比賽需要一名無人機操作員坐在椅子上,戴上顯示器眼鏡,將所有從攝像機拍攝的圖像投射在極其敏捷的無人駕駛賽車上。令人難以置信的是,無人車操作員能夠通過看似不可能的室內環境來操縱機器,同時還能保持非常高的速度。坐落在操作者耳朵之間的重達三磅的物塊能夠將高維視頻反饋轉換成四維遙控信號,從而以驚人的效率和極高的安全性來引導車輛。在這樣的任務中,有可能擊敗人類大腦的真實環境下的AI agent將體現結構,模擬和安全這三個方麵。
作者:AshishKapoor
來源:Microsoft Research Blog




















