
時間:2017-05-25 來源:互聯網 瀏覽量:
機器之心編譯
參與:黃玉勝
近日,微軟公布的一篇新論文提出了一種新架構,它的內部表征(在執行文本問答任務時通過端到端的優化來學習的表征)可以用語言學理論的基本概念來解釋。這篇論文的作者之一鄧力目前已經離開了微軟,加入了對衝基金巨頭 Citadel 任首席人工智能科學家。在機器之心將於 27-28 日舉辦的 GMIS 2017 大會上,鄧力將帶來主題為《無監督機器學習的最新進展》的演講。機器之心在本文中對這項研究進行了摘要介紹,論文原文請訪問:https://arxiv.org/abs/1705.08432
我們介紹了一種新架構,它的內部表征(在深度學習網絡中通過執行文本問答任務來端到端優化而學習到的表征)可以用語言學理論的基本概念來解釋。這種可解釋性相對於新的基於原模型的準確度隻有幾個點的降低(BiDAF[1])。被解釋的內部表征是張量積表示(Tensor Product Representation):對於每個輸入詞,模型選擇一個符號來對詞進行編碼,一個放置符號的角色(role),然後將它們綁定起來。這種選擇是通過軟注意(soft attention)模型實現的,總體的解釋是由符號的解釋所構建的,與訓練模型利用的一樣,模型也利用對角色的解釋。我們發現了對初始假設的支持,即符號可以被解釋為詞彙-語義詞義(lexical-semantic word meanings),而角色可被解釋為對語法角色(或類別)的近似,例如主語、問詞、限定詞等。通過非常詳細的、細粒度的分析,我們發現了在學習到的角色和又標準解析器 [2] 分配的詞性之間的特定對應關係,並且在模型的幫助下找到了幾個差異。在這個意義上,該模型可以在僅有無語言學相關注釋的文本、問題和答案的情況下學習到語法的重要方麵:模型沒有先驗的語言學知識。該模型僅有使用符號和角色來進行表征的方式和以一種大致離散的方式有利於這種使用的歸納偏置。
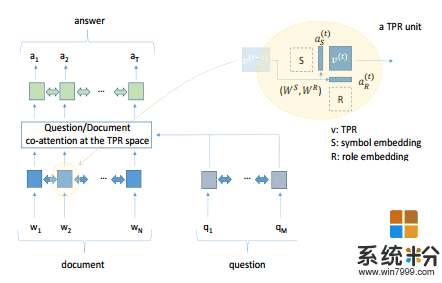
圖 1:該模型的係統框圖




















