時間:2017-05-14 來源:互聯網 瀏覽量:
選自arXiv
作者:Bhaskar Mitra、Nick Craswell
機器之心編譯
參與:晏奇、黃小天

近日,微軟研究人員 Bhaskar Mitra 和 Nick Craswell 在 arXiv 上提交了一篇名為《用於信息檢索的神經模型(Neural Models for Information Retrieval)》論文,論文概述了神經信息檢索模型背後的基本概念和直觀內容,並且將其置於傳統檢索模型的語境之中。論文的目的在於為神經模型與信息檢索之間架起橋梁,互通有無,加快神經信息檢索技術的發展。機器之心對該論文進行了編譯,論文鏈接見文末。
信息檢索(information retrieval,IR)的神經排序模型使用淺層或深層神經網絡來根據查詢(query)對搜索結果進行排序。傳統的學習排序的模型是在手工標注的信息檢索特征上使用機器學習技術,與之相反,神經模型可以從原始文本材料(這些材料可以彌合查詢與文檔詞彙之間的差距。)中學習語言的表征。不同於經典的信息檢索模型,在可被部署之前,這些新型機器學習係統需要大量的訓練數據。該教程介紹了神經信息檢索模型背後的基本概念和直觀內容,並且該教程也會把它們置於傳統檢索模型的語境之中。我們以信息檢索基本概念介紹和學習文本向量表征的不同神經、非神經進路開始。然後,我們回顧一下使用預訓練的沒有端到端學習信息檢索任務的神經項嵌入(term embedding)的淺層神經信息檢索方法。之後我們會介紹深度神經網絡,討論熱門的深度架構。最後,我們會回顧目前用於信息檢索的 DNN 模型,並以討論的形式對神經信息檢索未來可能的發展方向進行總結。

近十年來,計算機視覺、語音識別和機器翻譯的性能獲得了超乎想象的提升,研究領域和現實世界應用領域見證了這一切。這些突破大部分由近期在神經網絡模型方麵的進步所推動,這些神經網絡通常有多個隱藏層,我們稱之為深度架構。諸如會話代理(agent)和玩遊戲達到人類水平的代理這樣令人激動的全新應用也相繼出現。現在,信息檢索社區也開始應用這些神經方法,這將為提升最先進技術或者甚至在其它領域實現突破帶來可能。
信息檢索的方式有很多。使用者可以文本查詢的方式表達其信息需求,這裏所謂的文本查詢方式可指鍵盤鍵入、選擇一個查詢建議、聲音識別或者圖像形式查詢,甚至在有些情況下需求不太清楚也可以。檢索可以涉及對現存內容的部分進行排序,這些部分可以是文檔或簡短的文本答案,也可以是通過組合新的答案來具體化檢索信息。信息需求和檢索結果或許都使用了同樣的方式(比如,檢索文本文檔以響應關鍵詞查詢),亦或也有不同方式(比如,使用文本查詢進行圖像搜索)。檢索係統可能會考慮用戶曆史、物理定位、信息的時間變化或者排序結果時的其它語境因素。這些因素也可能幫助用戶形成其的意圖(比如,通過自動完成的查詢或者查詢建議)並且/或者可以幫助用戶提煉出更易於檢查的簡練的結果總結(summaries of result)。
神經信息檢索指的是將淺層或深層神經網絡應用於這些檢索任務之上。該教程目的在於介紹神經模型,其回應查詢以進行文檔排序,這是一項重要的信息檢索任務。一條搜索查詢通常可能會包含一些詞語,然而文檔的長度會根據特定的場景而改變,從幾個詞到成百上千個句子甚至更長。信息檢索的神經模型使用文本的向量表征,通常這包含了大量需要調整的參數。帶有大型參數集的機器學習模型通常需要大量的訓練數據。不同於傳統的學習排序的方法(這些方法在一個手工標注的特征集上訓練機器學習模型),信息檢索的神經模型通常可以將查詢(query)和文檔(document)的原始文本(raw text)作為輸入。學習文本的恰當表征也需要大量數據訓練。因此,不同於經典信息檢索模型,這些神經方法非常需要數據,數據越多,性能越好。
文本表征可通過非監督或監督方式習得。監督式方法使用諸如標注的查詢文檔對(query-document pairs)這樣的信息檢索數據來習得一個表征,其專為手頭任務進行端到端優化。如果沒有足夠的信息檢索標記,那麼非監督式方法可僅通過使用查詢和/或文檔來習得一個表征。在非監督學習方法中,不同的非監督式學習設置可能會導致不同的向量表征,這些表征不同於它們在被表征對象之間所捕獲的相似度概念。當應用這些表征時,應該仔細考察非監督學習設置的選擇,因此,我們可以產生一個適合於目標任務的文本相似度概念。傳統信息檢索模型比如潛在語義分析 (Latent Semantic Analysis,LSA)可以學習密集的詞和文檔的向量表征。神經表征學習模型和這些傳統方法享有一些共性。幾十年來,我們對這些傳統方法的大部分理解都可以被擴展成這些現代表征學習模型。
在其它領域,神經網絡的進步已經由特定的數據集和應用需求所推動。例如,數據集和成功的架構因視覺對象識別、語音識別和遊戲代理而迥然不同。盡管信息檢索與自然語言處理領域有一些共同特征,但是它也麵臨自己的一係列特殊挑戰。信息檢索係統必須處理可能包含未見過詞語的簡短查詢(short query),以此來和不同長度的文檔進行匹配,找到可能包含了大量不相關文本的相關文檔。信息檢索係統應該在查詢(query)和表明了相關性的文檔文本中學習模式,即便查詢和文檔使用了不同的詞彙,甚至即便模式是專用於任務(task-specific)或語境(context-specific)的。
該教程的目標是在傳統信息檢索研究的語境裏介紹神經信息檢索的基本內容,用可見的實例展示關鍵概念和描述關鍵模型的一致性數學標注(notation)。第二部分會給出一個信息檢索的任務、挑戰、量度和非神經模型的調查。第三部分會提供簡要神經信息檢索模型的概覽與信息檢索的不同神經方法的分類。第四部分介紹學習項嵌入(term embedding)的神經和非神經方法,這些方法不使用來自信息檢索標簽的監督,而是聚焦在相似度概念上。第五部分調查了合並這些信息檢索嵌入的一些特殊方法。第六部分介紹了目前在信息檢索中使用的深度模型的基本情況,包括了熱門架構和工具包。
第七部分調查了一些在信息檢索中實現深度神經網絡的特殊方法。第八部分是我們的討論,包括未來的工作與結論。
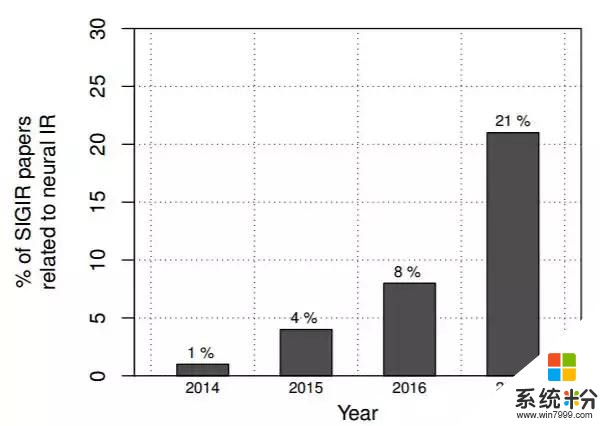
圖 1:ACM SIGIR 大會上神經信息檢索(IR)論文的百分比——該數據通過對論文題目進行手動篩查計算獲得——其清晰展示出該研究領域的熱門程度正在逐年上升。
由於神經信息檢索正在成為一個新興領域,所以我們撰寫了該教程。神經信息檢索領域的研究出版物正在逐漸增多(圖 1),與之同步增長的還有相關話題的研討會 [42–44]、教程 [97, 119, 140] 和大會 [41, 129]。由於這種興趣是最近不久才產生的,所以部分有信息檢索專長的研究人員可能對神經模型不太熟悉,而其它熟悉神經模型的研究人員又可能對信息檢索不太熟悉。所以該教程的目的即通過描述當下正在使用的相關信息檢索概念和神經方法來彌合這條縫隙。
以下為該概述論文目錄:
2 文本檢索基礎(Fundamentals of text retrieval)
3 剖析神經信息檢索模型(Anatomy of a neural IR model)
4 項表征(Term representations)
5 用於信息檢索的項嵌入(Term embeddings for IR)
6 深度神經網絡(Deep neural networks)
7 用於信息檢索的深度神經模型(Deep neural models for IR)
8 總結