
時間:2017-05-12 來源:互聯網 瀏覽量:

在幾十年的曆程中,有非常多優秀的公司在語音和語言領域進行了不懈地探索,終於在今天,達到了和人一樣精準的語音識別,這是非常了不起的曆史性突破。語言是人類特有的交流工具。今天,計算機可以在假定有足夠計算資源的情況下,非常準確地識別你和我講的每一個字,這是一個非常大的曆史性突破,也是人工智能在感知上的一個重大裏程碑。
Switchboard是整個工業界常用的一個測試數據集。很多新的領域或新的方法錯誤率基本都在20%左右徘徊。大規模標杆性的進展是IBM Watson,他們的錯誤率在5%到6%之間,而人的水平基本上也在5%到6%之間。過去20年,在這個標杆的數據集上,有很多公司都在不懈努力,如今的成果其實並不是一家公司所做的工作,而是整個業界一起努力的結果。
各種各樣的神經網絡學習方法其實都大同小異,基本上是通過梯度下降法(Gradient Descent)找到最佳的參數,通過深度學習表達出最優的模型,以及大量的GPU、足夠的計算資源來調整參數。所以神經網絡對計算機語音識別的貢獻不可低估。早在90年代初期就有很多語音識別的研究是利用神經網絡在做,但效果並不好。因為,第一,數據資源不夠多;第二,訓練層數少。而由於沒有計算資源、數據有限,所以神經網絡一直被隱馬爾可夫模型(Hidden Markov Model)壓製著,無法翻身。

深度學習翻身的最主要原因就是層數的增加,並且和隱馬爾可夫模型結合。在這方麵微軟研究院也走在業界的前端。深度學習還有一個特別好的方法,就是特別適合把不同的特征整合起來,就是特征融合(Feature Fusion)。
如果在噪音很高的情況下可以把特征參數增強,再加上與環境噪音有關的東西,通過深度學習就可以學出很好的結果。如果是遠長的語音識別,有很多不同的回音,那也沒關係,把回音作為特征可以增強特征。如果要訓練一個模型來識別所有人的語音,那也沒有關係,可以加上與說話人有關的特征。所以神經網絡厲害的地方在於,不需要懂具體是怎麼回事,隻要有足夠的計算資源、數據,都能學出來。
我們的神經網絡係統目前有好幾種不同的類型,最常見的是借用計算機視覺CNN(Convolution Neural Net,卷積神經網絡)可以把不同變化位置的東西變得更加魯棒。你可以把計算機視覺整套方法用到語音上,把語音看成圖像,頻譜從時間和頻率走,通過CNN你可以做得非常優秀。另外一個是RNN(Recurrent Neural Networks,遞歸神經網絡), 它可以為時間變化特征建模,也就是說你可以將隱藏層反饋回來做為輸入送回去。這兩種神經網絡的模型結合起來,造就了微軟曆史性的突破。
微軟語音識別的總結基本上可以用下圖來表示。
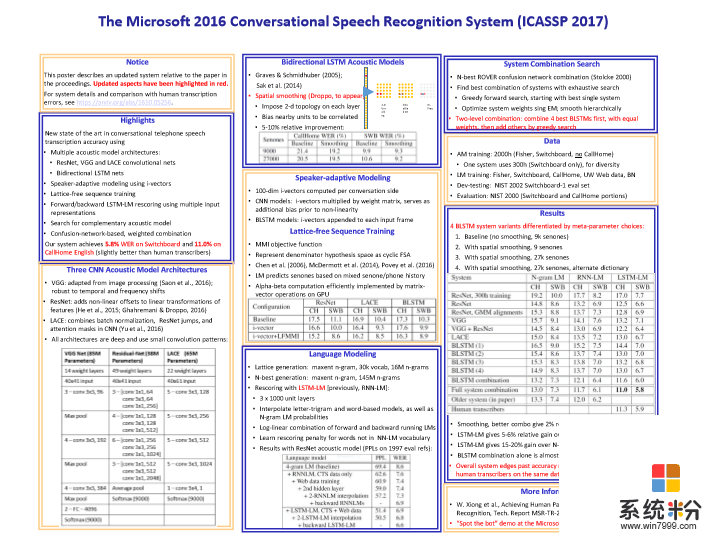
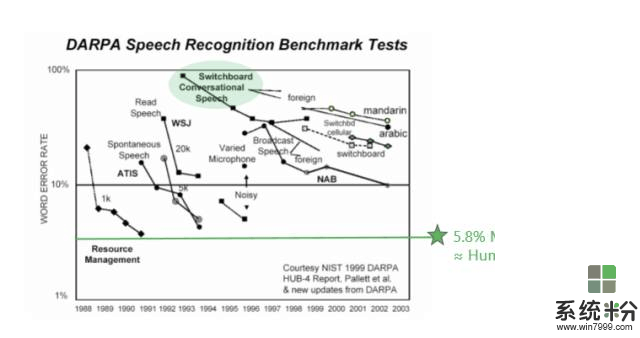
下圖是業界在過去幾十年裏麵錯誤率下降的指標,可以看到5.8%是微軟在去年達到的水平。Switchboard的錯誤率從80%左右一直到5.8%左右,是用了什麼方法呢?我們是怎麼達到這個目標呢?
大家知道語音識別有兩個主要的部分,一個是語音模型,一個是語言模型。

語音模型我們基本上用了6個不同的神經網絡,並行的同時識別。很有效的一個方法是微軟亞洲研究院在計算機視覺方麵發明的ResNet(殘差網絡),它是CNN的一個變種。當然,我們也用了RNN。可以看出,這6個不同的神經網絡在並行工作,隨後我們再把它們有機地結合起來。在此基礎之上再用4個神經網絡做語言模型,然後重新整合。所以基本上是10個神經網絡在同時工作,這就造就了我們曆史性的突破。




















