
時間:2020-02-11 來源:互聯網 瀏覽量:
今天(2月11日),微軟發布史上最大語言模型,名為Turing-NLG。
170億參數量,是此前最大的語言模型英偉達“威震天”(Megatron)的兩倍,是OpenAI模型GPT-2的10多倍。
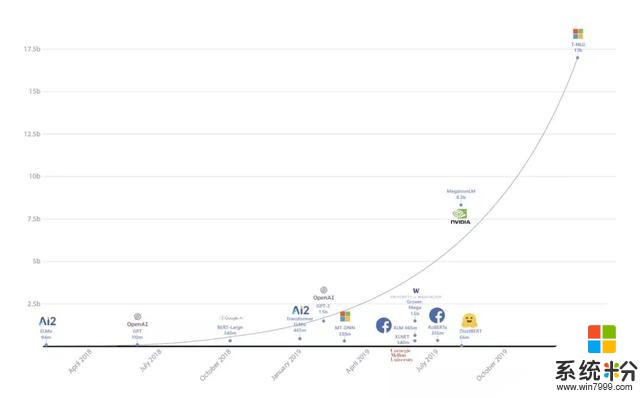
“隨著更大的自然語言模型導致更好結果的趨勢,微軟引入了Turing-NLG,”微軟在研究博客中寫道。“它在各種語言建模基準方麵的表現超過了最先進的水平,並且在許多實際任務的應用上,比如回答問題和摘要生成方麵表現都十分優異。”
與此同時,微軟研究也發布了另一篇博客文章,介紹了用於分布式訓練大型模型的DeepSpeed深度學習庫和ZeRO優化技術,並表示如果沒有這些突破,Turing-NLG不可能完成。
史上最大語言模型Turing-NLG,簡稱T-NLG,是一個基於Transformer的生成語言模型,可以生成單詞來完成開放式的文本任務,比如回答問題,提取文檔摘要等等。
微軟認為,想要在任何情況下,都能使機器像人類一樣直接、準確、流暢地做出反應,開發像T-NLG這樣的生成模型對解決NLP任務非常重要。
以前,回答問題和提取摘要的係統,主要依賴於從文檔中提取現有的內容。雖然可以作為替代答案或摘要,但常常顯得不自然或不連貫。
“有了T-NLG,我們可以自然地總結或回答有關個人文件或電子郵件線程的問題,”微軟表示。

這背後的邏輯在於:即使訓練樣本較少,但模型越大,預訓練的數據越多樣化和全麵,它就越能更好地推廣到多個下遊任務。
所以,微軟也認為訓練一個大型的集中式多任務模型,並在眾多任務之間共享它的能力,比為每個任務單獨訓練一個新模型更有效。
T-NLG是怎麼訓練出來的?訓練大型模型的一個常識是:任何超過13億參數的模型,單靠一個GPU(即使是一個有32GB內存的 GPU)也是不可能訓練出來的,因此必須在多個GPU之間並行訓練模型,或者將模型分解成多個部分。
微軟介紹稱,能夠訓練T-NLG,得益於硬件和軟件的突破,一共體現在三個方麵:
第一,他們利用NVIDIA DGX-2硬件設置,使用InfiniBand連接,以便GPU之間實現比以前更快的通信。第二,使用四個英偉達V100 GPU,在英偉達 Megatron-LM框架中應用張量切片分割模型。第三,使用Deepspeed和ZeRO降低了模型的並行度(從16降低到4) ,將每個節點的批處理大小增加4倍,並且減少了三倍的訓練時間。Deepspeed使得使用更少的GPU訓練非常大的模型更有效率,並且它訓練的批量大小為512,使用256個 NVIDIA GPU。如果用Megatron-LM 需要1024個 NVIDIA GPU。此外,Deepspeed還與PyTorch兼容。

最終的T-NLG模型中,有78個Transformer層,隱藏大小為4256,有28個注意頭。
為了使模型的結果能與Megatron-LM媲美,他們使用了與其相同的超參數和學習時間表進行預訓練。與此同時,他們也使用與Megatron-LM相同類型的數據對模型進行訓練。
效果達到最先進水平,將用於Office套件模型預訓練完成後,他們也在WikiText-103(越低越好)和LAMBADA(越高越好)數據集上,與英偉達Megatron-LM和OpenAI的GPT-2完整版進行了比較,都達到了最新的水平。
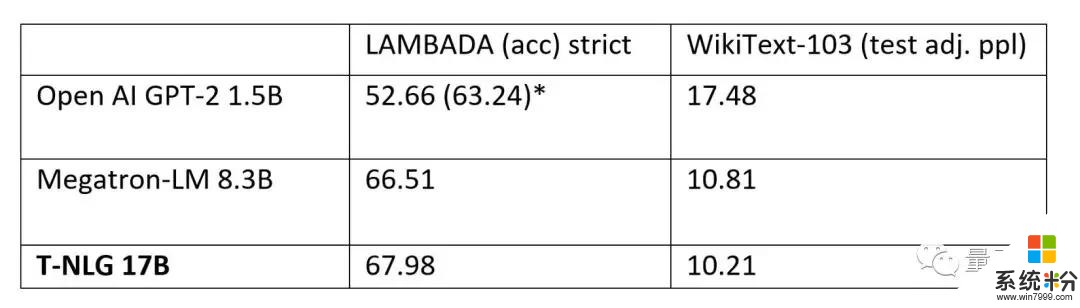
不僅僅是數據集上,微軟也公布了T-NLG在具體任務中的表現。
首先是回答問題。其不僅能夠使用一個完成的句子回答,還能夠在不需要上下文的情況下回答問題,比如下麵的這個問題並沒有給出更多的信息。在這些情況下,T-NLG能基於預訓練中獲得的知識來生成一個答案。

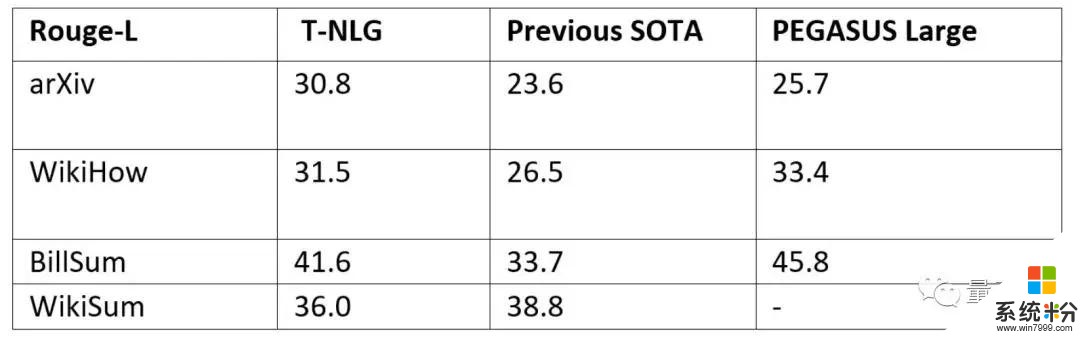
其次是生成摘要。微軟表示,為了使 T-NLG 盡可能多用於總結不同類型的文本,他們幾乎在所有公開可用的摘要數據集上以多任務的方式完善了T-NLG模型,總計約400萬個訓練實例。
他們與另一個最新的基於Transformer的語言模型PEGASUS,以及先前最先進的模型進行了比較,ROUGE評分結果如下,基本上實現了超越。
實際效果怎樣?
為了秀這個模型的能力,微軟用T-NLG模型,給介紹T-NLG的博客文章寫了一份摘要:
正如摘要中所說的,微軟的T-NLG目前並不對外公開。
對於T-NLG的應用潛力,微軟說它為其和客戶提供了新的機會。
除了通過總結文檔和電子郵件來節省用戶時間,還可以通過向作者提供寫作幫助和回答讀者可能提出的關於文檔的問題,來增強使用 Microsoft Office 套件的體驗,打造更強的聊天機器人等等。
微軟表示,他們對新的可能性感到興奮,將繼續提高語言模型的質量。
關於文章中提到的ZeRO & DeepSpeed,如果你有興趣,可以進一步閱讀下微軟的官方博客文章,其中DeepSpeed開源了, ZeRO的論文也已經發布:https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們,第一時間獲知前沿科技動態




















