
時間:2019-12-29 來源:互聯網 瀏覽量:
正如《麻省理工學院技術評論》12月26日所指出的那樣。中國公司百度建立的計算機模型領先於其它所有通用語言理解模型。本月初百度公司在一場持續的人工智能競爭中悄然擊敗了微軟和穀歌,但我們國內關於此次競賽的報道似乎並不多。

事實上百度公司不僅僅是一家搜索網站,它還是中國人工智能技術的領先者。這次百度參與的競爭是通用語言理解評估,英文簡稱為GLUE。百度公司利用Ernie模型成為在GLUE測試中首隻超過90分的團隊,在由美國科技公司和大學占主導的排行榜中名列榜首。
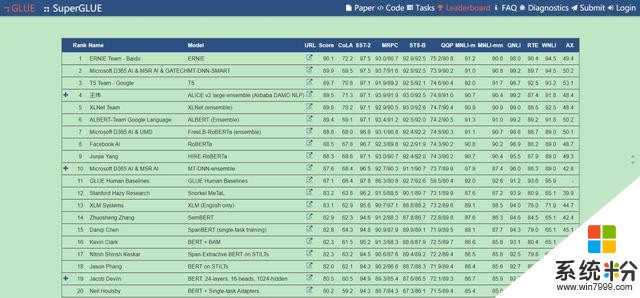
這一優異測試結果也使其成為GLUE基準測試中超過平均得分87.1的僅有的10個AI係統之一。微軟的D365 AI團隊和穀歌的T5團隊分列第二三名。百度公司的算法最初設計是用於學習理解中文的,現在它卻成為了理解英文語義最好的算法。
GLUE是一個被普遍接受的基準,用於評估人工智能係統理解人類語言。它由九種不同的測試組成,比如在句子中挑選人名和組織名,以及當有多個潛在先行詞時,找出像“It”這樣的代詞指的是什麼。因此一個在GLUE上得分很高的語言模型可以勝任處理不同的閱讀理解任務。滿分為100分,平均分是87分。ERNIE是百度創建的知識增強的語義表達模型,而對手穀歌則有一個名為BERT的預訓練模型。
GLUE在公開排行榜上的排名在不斷變化,雖然還有另外一支團隊很可能很快會超越百度。但是百度的成就讓人值得注意的是,它展示了AI研究如何從眾多貢獻者中受益。百度的研究人員不得不針對中文開發一種專門技術來構建ERNIE知識增強語義表達模型。然而讓研究人員欣喜的是,該技術也能使人工智能更好地理解英語。

在穀歌的BERT預訓練模型於2018年末創建之前,自然語言模型並不是那麼好。之前的自然語言模型擅長預測句子中的下一個單詞,因此非常適用於自動完成功能。隻是即使是一小段文字,它們也無法訓練具有任何思路。這是因為它們不理解含義,例如“它”一詞可能指的是什麼。先前的模型學會了預測和解釋單詞的含義,可以僅通過考慮單詞之前或之後出現的上下文來理解單詞含義,但是它不能同時考慮兩者。換句話說它是單向工作的。
相比之下BERT模型有所改進,BERT模型可以同時考慮單詞前後的上下文,使其雙向。它使用一種稱為“遮罩”的技術來執行此操作。在給定的文本段落中,BERT隨機隱藏15%的單詞,然後嚐試從其餘單詞中進行預測。這使得它可以做出更準確的預測,因為它可以有兩倍的線索可以利用。例如,在“男人去___購買牛奶”一句中,句子的開頭和結尾都提示了缺失的單詞。 ___是您可以去的地方,也是可以購買牛奶的地方。

使用遮罩技術是對自然語言任務進行重大改進背後的核心創新之一,並且是諸如OpenAI GPT-2之類的模型能夠在不偏離中心主題的情況下寫出極具說服力的散文的部分原因。
從英文到中文再回到英文。當百度研究人員開始開發自己的語言模型時,他們希望以遮罩技術為基礎,但是他們意識到他們需要進行調整以適應中文。
在英語中,單詞充當語義單位,這意味著完全脫離上下文的單詞仍然包含語義。然而中文漢字卻不一樣了。雖然某些漢字確實具有內在含義,例如火,水或木。但還有許多漢字隻有與其他漢字組合在一起才可以更明確意思。例如漢字靈可以既表示聰明也可以表示靈魂。專有名詞中的漢字,例如波士頓或美國,一旦分開講就不是同一件事了。

因此研究人員對ERNIE進行了一種新版本的遮罩技術訓練,這種遮罩技術可以隱藏多個字符串而不是單個字符串。他們還訓練它區分有意義的和隨機的字符串,這樣它就可以相應地做出正確的字符組合。因此ERNIE更好地掌握了漢字是如何編碼信息的,也更準確地預測了缺失的部分。事實證明,這對於翻譯和從文本文檔中檢索信息等應用非常有用。
研究人員很快發現這種方法實際上對英語也更好。盡管英語不如中文會出現頻繁的組合表達意義,但英語具有類似的單詞字符串,這些單個單詞表示的含義與它們組合在一起截然不同。像“哈利·波特”這樣的專有名詞和像“切下舊木塊”這樣的表達就不能通過將它們分離成單獨的單詞來進行有意義的解析。
最新版本的ERNIE還使用了其他一些培訓技術。比如它能考慮句子的順序和它們之間的間隔距離,來理解一個段落的邏輯發展。然而最重要的是,它使用了一種稱為持續訓練的方法,這種方法可以讓它在不忘記以前學到的東西的情況下,對新數據和新任務進行訓練。這使得它能夠越來越好地在盡可能少的人為幹擾下執行範圍廣泛的任務。

百度正積極利用ERNIE模型為用戶提供更多適用的搜索結果,刪除新聞源中的重複報道,提高人工智能助手小度準確響應請求的能力。
他們還將在在一篇論文中詳細描述ERNIE的最新架構,該論文將在明年的人工智能發展協會會議上發表。就像百度團隊的創新建立在穀歌的BERT模型上一樣,研究人員希望其他團隊也能從他們研發改進ERNIE的模型中受益。
百度搜索的首席架構師田浩說:“當我們最初開始這項工作時,就特別考慮了漢語的某些特點,但我們很快發現,它的適用範圍遠不止這些。”






















