
時間:2019-12-03 來源:互聯網 瀏覽量:
看圖,永遠比看字省事。
比如說,相比看文字版小說,看小說改編的漫畫更簡單輕鬆。
那麼,如何把一段故事自動變成漫畫呢?
AI已經可以做到了。給它一段故事,它就可以用圖片把故事講出來,稍加修改,就變成了一套連環畫。
像這樣的一段故事:
AI可以把它變成這樣的漫畫:

而且,這種漫畫形式還可以在電影工業中充當故事板,輔助電影人們進行藝術創作。
找到能講故事的圖那麼這個過程是怎樣實現的呢?
首先要說明一點,這些圖片並不是AI憑空畫的,而是采取了一種更簡單省事的方法:
從現成的圖庫裏找出一些構圖相似的,拿來改一改。
這裏的圖庫,叫做GraphMovie數據集,數據來源是一些影評網站。
但是數據集裏的圖很多,怎麼才能用AI自動的找出最符合你故事的圖片呢?
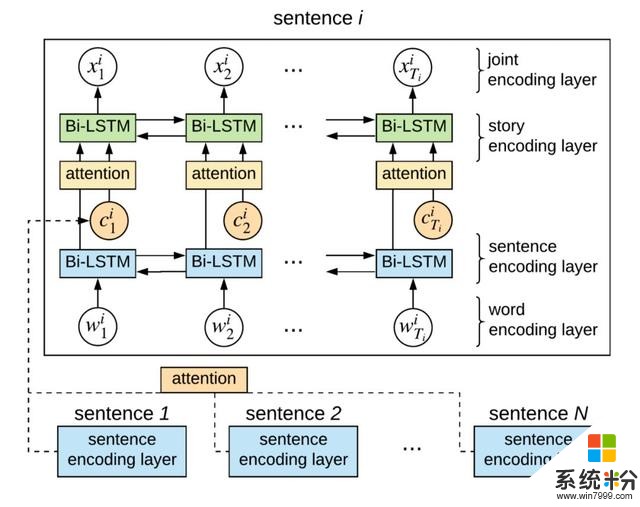
這裏用到了一個模型,叫做情景感知密集匹配模型(Contextual-Aware Dense Matching model,CADM)。
它長這樣:
根據故事的內容,CADM找到了這樣的一些圖像:



另外,還有一個模型叫做No Context,它是此前“看字找圖”這個領域中表現最好的AI。
No Context也找了一些圖像出來:



不過,圖還是有點少,人家好歹也是個完整的故事,你總不能拿這麼幾張圖就講完,這樣故事沒有細節,讀者的體驗也不好。
現在,請出第三個模型:貪婪解碼算法,它負責根據故事裏的細節,再找找能用上的圖。
讓它出馬來補一補之後,故事立馬就完整了:
 把圖片的畫風統一
把圖片的畫風統一不過,就這樣的效果,你會看得糊裏糊塗,好像並不能傳達出前麵文本裏的故事。
問題出在哪兒呢?
第一個問題是,圖片裏有許多背景、環境等相關元素,跟故事主線毫無關係,看到它還會影響你對故事的理解。
需要把這些冗餘元素刪掉,這裏用到了何愷明的成名作Mask R-CNN,進行區域分割,刪掉圖片中和故事不相關的部分。
現在,這些圖片長這樣:

第二個問題,這些圖片的畫風實在是差異太大了,把這樣的漫畫拿出去,會被讀者打的。
所以,需要把圖片的樣式統一起來,這裏用到了一個工具CartoonGAN,從字麵意思就可以理解,這是一個讓圖片變成卡通風格的GAN(生成對抗網絡)。
在卡通GAN處理之後,這組圖片變成了這樣:

似乎好了一些,但是還有一個大bug:這些人長得不一樣呀!你說他們是同一個故事的主角,打死我也不信。
於是,第三個問題來了,怎麼才能讓這些人都長成一個樣?
這裏,研究者們直接找了一個軟件,叫做Autodesk Maya,是一個在電影裏處理3D圖像的軟件,靠它製作出3D的場景、人物和道具,用半手動的方式把9張圖片裏的人全變成一個樣。
不過論文作者表示,未來這個製作3D圖像的過程有望全自動生成。
這一頓操作,是真的猛如虎,9張八竿子打不著邊的圖,現在畫風一致、故事流暢,甚至還補充了背景和美化。
 在電影工業中有大用途
在電影工業中有大用途其實,這樣生成的“漫畫”並不是最終結果。
它其實是用來拍電影的。
拍電影的準備過程中,需要一個Demo叫做“故事板(storyboard)”。

借助故事板,電影人在創作的過程中就可以先改Demo,定下來之後再完成成品,把撕逼的過程放在前麵,防止做完之後甲方爸爸再提修改意見,導致工作量急劇提升。
因此,像這篇論文裏這樣,自動生成故事板,就可以節約電影人的許多時間,提高創作者們的生產效率。
人大博士出品這篇論文的作者團隊非常龐大,一共9位作者,分別來自中國人民大學、微軟和北京電影學院。

一作陳師哲目前在人大讀到了博士五年級,也是曾在微軟小冰團隊實習,還曾經赴CMU和阿德萊德大學訪學。
她也是一位學術達人,僅僅今年一年,包括這篇論文在內就已經發了三篇頂會一作。

另外,微軟小冰團隊首席科學家宋睿華也參與到了這項研究中。

宋睿華博士畢業於清華大學,長期研究短文本對話與生成、信息檢索與提取等領域,曾擔任SIGIR、SIGKDD、CIKM、WWW、WSDM等會議的程序主席或高級程序主席。
傳送門Neural Storyboard Artist: Visualizing Stories with Coherent Image Sequences
作者:Shizhe Chen, Bei Liu, Jianlong Fu, Ruihua Song, Qin Jin, Pingping Lin, Xiaoyu Qi, Chunting Wang, Jin Zhou
https://arxiv.org/abs/1911.10460v1
— 完 —
量子位 QbitAI · 頭條號簽約
關注我們,第一時間獲知前沿科技動態




















