
時間:2019-11-25 來源:互聯網 瀏覽量:
作者:Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee 等

論文鏈接:https://arxiv.org/abs/1910.04940
背景介紹
隨著機器學習模型,和數據量的不斷增長,模型訓練逐漸由單機訓練,轉變為分布式的多機訓練。在分布式深度學習中,數據並行是最為常用的模型訓練方式。然而數據並行的模型訓練過程中,需要頻繁的做數據聚合/模型同步。參與運算的 GPU 數量越多,其對應的數據聚合的開銷也會越大。當下單個 GPU 的算力不斷增加,GPU 間的數據聚合成成了新的分布式機器學習的瓶頸。
各大公司也發現了數據聚合這個重大瓶頸,因此在軟硬件上都提出了自己的解決方案。硬件層麵上,GPU 廠商 Nvidia 發布了 GPU 之間直接相連的高速通信通道 NVLink,以及多 GPU 之間的路由器 NVSwitch。軟件層麵上,各大公司都相繼發布了自己的 GPU 通信庫(例如:Nvidia 的 NCCL,Baidu 的 Ring-AllReduce),或者針對 GPU 通信進行優化的分布式機器學習平台(最流行的 Uber 的 Horovod)。
然而,這些軟件層麵上的通信庫或者機器學習平台,並沒有充分利用所有的,同構和異構的網絡通信線路。因此,由 UC Berkeley,Microsoft Research 以及 University of Wisconsin-Madison 組成的研究團隊發布,能夠充分利用所有同構及異構的網絡傳輸線路,從而實現最優 GPU 間數據聚合的 Blink 項目。
文章簡介
當下流行的分布式機器學習平台(Horovod)或 GPU 間數據聚合的通信庫(NCCL),其最大問題在於無法很好的解決網絡異構性。網絡異構性主要表現為如下三點:
1. 同構的 GPU 間鏈接線路,例如 NVLink,用於不同型號的 GPU 的對應 NVLink 的版本和帶寬不同,其組成的網絡的拓撲結構也不相同。具體區別如圖一所示。
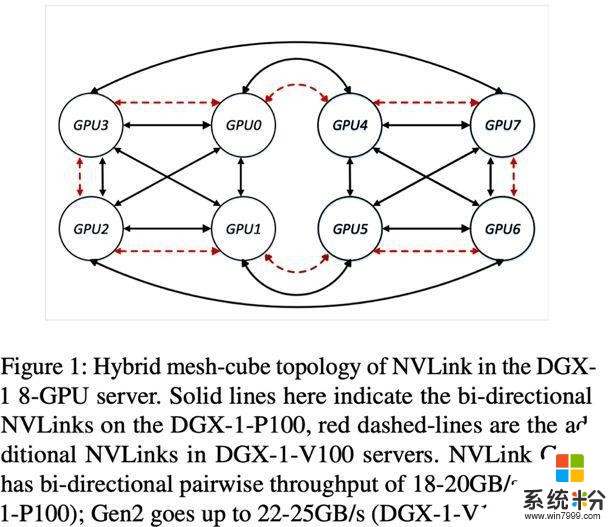
在一個 8 卡的 DGX-1 機器上:如果 GPU 是 P100,其對應的 NVLink 是第一代,帶寬為 18-20GB/s,其拓撲結構如圖 1 黑線所示。如果 DGX-1 用的 GPU 是 V100,其 NVLink 通信線路為第二代,帶寬為 22-25GB/s。於此同時,相比 P100 的 DGX-1,V100 的 DGX-1 的網絡拓撲結構也不同,其在 P100 的基礎上,新增了一圈紅色虛線的 NVLink 線路。
2. 當下主流的 GPU 間數據聚合,使用的是構建環狀(Ring)通信通道,其無法很好的利用異構的通信線路。原因很簡單,如果用異構的線路構建一個環狀網絡,整個環的最大帶寬被這個環狀通道中帶寬最小的一段線路所限製。例如用 PCIe 和 NVLink 一起構建一個環狀的網絡傳輸通道,則整個環狀通道的吞吐率會被 PCIe 的帶寬限製,因為 PCIe 的帶寬(8-12GB/s)遠小於 NVLink(18-25GB/s)。
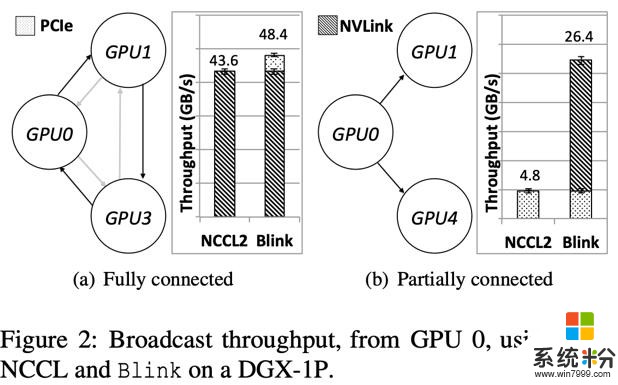
因此,如圖 2(a)所示(這裏的 GPU 的 ID 可以直接映射在圖 1 上),當 GPU 間存在能夠建立環狀網絡的 NVLink 線路時,NCCL/Horovod 就直接放棄 PCIe 這種異構線路,隻用 NVLink 構成環狀網絡進行 GPU 間數據聚合。
3. 在多租戶的雲計算環境下,計算資源的調度器通常完全不知道 GPU 之間的通信線路和拓撲結構的信息。因此,被調度器分配給同一個任務的多個 GPU,很有可能其間的網絡拓撲結構不規則,而且一個任務的多個 GPU 可能會被分配到不同機器上。
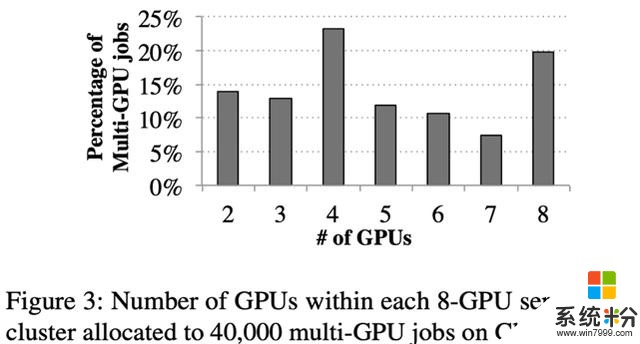
如圖 3 所示,我們分析了一個微軟內部機群的任務調度日誌。其所用的機器大多數是 8 卡的 DGX-1。我們發現,雖然用戶基本都在申請使用 2 的冪的數量的 GPU,但在每一台 DGX-1 機器上,分給同一個用戶任務的 GPU 數量會存在 3,5,6,7 這種數量。
如上三點的網絡異構性,導致很多 GPU 間的通信線路沒有被充分利用。例如圖 2(b)所示(GPU 的 ID 對應圖 1),當任務調度器在一台 DGX-1 機器上,分配給一個任務的 3 個 GPU 是 GPU0,1,4 時,由於 GPU1 和 GPU4 之間沒有直接相連的 NVLink,由於無法建立環狀通信通道,此時 NCCL/Horovod 會直接放棄 GPU0-GPU1 和 GPU0-GPU4 之間的兩條高速通信線路 NVLink,轉而完全使用低速的 PCIe 去做數據聚合。
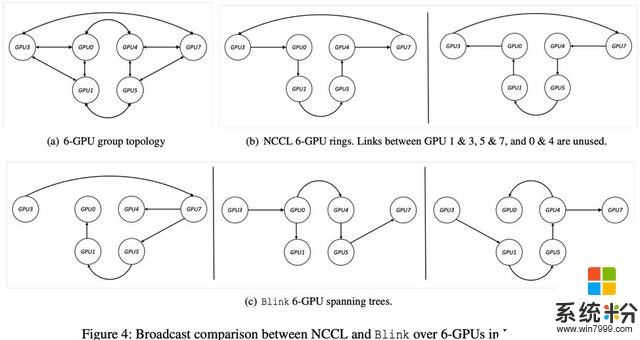
再者,即使分配給同一個任務的 GPU 間 NVLink 可以構成環狀通信通道,由於環狀通信通道本身的不靈活性(例如在一個環狀通信通道中,任意 GPU 隻能有一個輸入接口和一個輸出接口,而不能是多個輸入或輸出),導致 NCCL/Horovod 也無法利用所有的同構的高速線路 NVLink。如圖 4 所示,在一個廣播(Broadcast)的應用場景下,6GPU 的網絡拓撲結構如圖 4(a)所示,NCCL/Horovod 在這種情況下,可以構建兩個單向的環狀通道(圖 4(b)所示),這種做法使得 GPU1&3,GPU5&7,GPU0&4 之間的高速 NVLink 完全未被使用。
為了解決如上問題,我們提出 Blink,一個最優的 GPU 間數據聚合的通信庫。
首先,為了解決拓撲結構的不規則性,在同構網絡中,Blink 可以自動生成最優的多個數據聚合通道。為了充分利用所有現有的 GPU 間數據通信線路,Blink 放棄了搭建環狀(Ring)的數據聚合通道,使用一種更靈活高效的生成樹(spanning tree)協議。相比於環,生成樹可以更好的適應任意網絡拓撲結構,使其更高效的利用所有通信線路。如圖 2(b)所示,Blink 可以使用不能構成環的兩條 NVLink 用來做 GPU 間數據擬合。如圖 4(c)所示,生成樹在同樣的同構網絡拓撲結構下,可以同時建立 3 個可並行的數據聚合通道,相比於 NCCL/Horovod 的 2 個環狀通道。我們把每個 GPU 上需要數據聚合的數據總量叫做 N,同構線路的帶寬叫做 B,則在這個環境下,Blink 的通信時間可以由 NCCL/Horovod 的 N/2B 縮減為 N/3B。
其次,根據不同帶寬的異構線路,我們可以根據其帶寬,分配和平衡在其上做數據聚合的數據量大小,從而實現多個異構通道並行完成數據聚合。如圖 2(b)所示,Blink 可以同時用 PCIe 和 NVLink 實現數據的並行傳輸。
最後,Blink 提供了和 NCCL 完全一致的函數接口(API),所以不需要修改任何用戶層麵的代碼,Blink 就可以無縫使用到當下流行的分布式機器學習平台,例如 PyTorch,TensorFlow 等。
實驗結果
1. Broadcast, AllReduce 基準測試
我們在三個多 GPU 的平台進行了 Broadcast 和 AllReduce 的數據聚合測試。三個平台分別為由 P100 GPU 組成的八卡機器 DGX-1-P00,由 V100 GPU 組成的 DGX-1-V100 和 DGX-2。基準測試的橫軸的數字序列均代表所使用的 GPU 的 ID,可以直接映射到圖 1。這些 GPU 的序列代表當下機器上所有可能出現的不同的拓撲結構。實驗的比較對象是 2019 年 7 月最新發布的 NCCL v2.4。
實驗結果如下:
1.1 基於 DGX-1-V100 的 Broadcast,AllReduce 測試
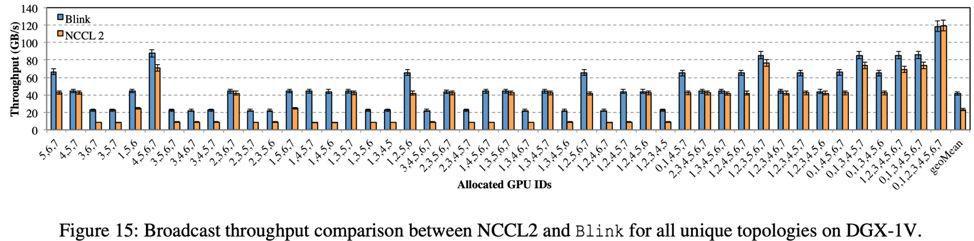
Broadcast 測試結果如圖 15 所示,在 DGX-1-V100 上,Blink 可以提速數據聚合效率高達 6 倍(平均 2 倍)。
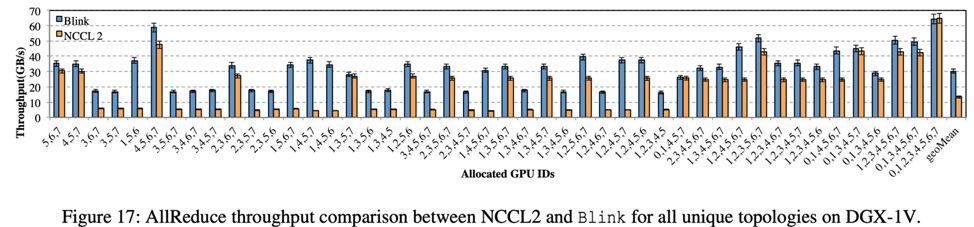
AllReduce 是 GPU 間數據聚合最頻繁使用的方式。測試結果如圖 17 所示,相比 NCCL,Blink 可提升數據聚合的吞吐率高達 8 倍(平均 2 倍)
1.2 基於 DGX-1-P00 的 Broadcast 測試
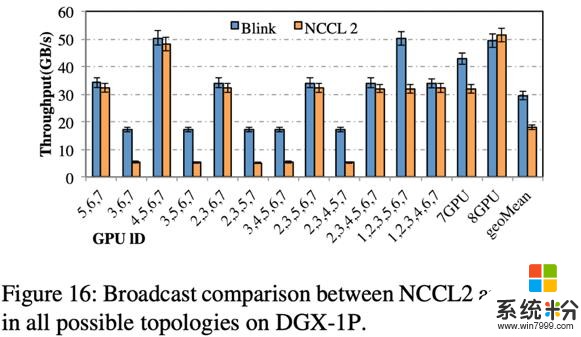
如圖 16 所示,相比 DGX-1-V100,DGX-1-P100 的不同拓撲結構數量少,原因在於其 NVLink 網絡的拓撲結構是更為規則的 hyper-cube(圖一黑線所示)。相比 NCCL,Blink 可以提升通信效率高達 3 倍(平均提高 1.6 倍)。
1.3 基於 DGX-2 的 AllReduce 測試
DGX-2 是集成了 16 個 GPU 的大型計算機器。相比與 DGX-1,DGX-2 裏麵新加入了多個 NVSwitch 芯片,可以更好的實現 GPU 間點對點的無衝突通信。
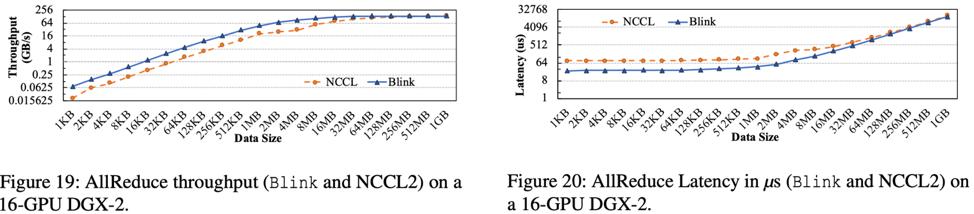
實驗結果如圖 19 和 20 所示,Blink 可以提升 AllReduce 吞吐率高達 3.5 倍,減小通信延遲高達 3.32 倍。
2. 異構線路吞吐率測試
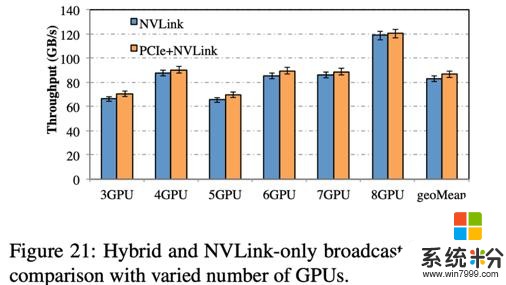
我們測試了在 DGX-1-V100 上的 PCIe 和 NVLink 通過 Blink 實現異構通信。結果如圖 21 所示,相比於隻利用 NVLink,加上 PCIe 實現異構通道並行數據聚合,可以提高整體通信吞吐率 2-5GB/s。
3. 機器學習模型訓練測試
我們使用圖像分類作為我們的實驗任務。我們在 ImageNet-1K 數據集上,分別對四種不同的 CNN(AlexNet, ResNet18, ResNet50, VGG16)進行了分布式模型訓練。單機和多機測試均用的 DGX-1-V100。
3.1 單機測試

單機測試結果如圖 18 所示,相比 NCCL,Blink 可以最多減少 87% 的 GPU 數據聚合時間(平均減少 31%),從而導致 Blink 可以縮短整個模型訓練時間高達 40%(平均 6.3%)。
3.2 多機測試
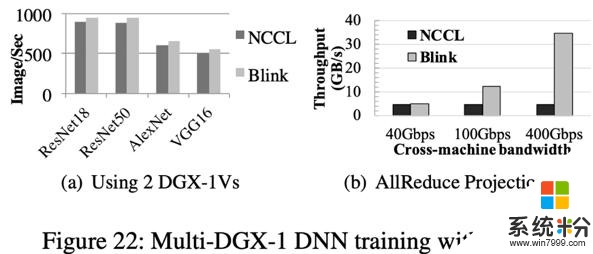
多機測試結果如圖 22(a)所示,相比 NCCL,Blink 在分布式 CNN 模型訓練中,圖片的吞吐率(Image/Sec)提高 11%。提升不顯著的根本原因是因為機器間的通信線路仍采用 40Gbps 的低速以太網,使其成為了數據聚合的瓶頸。我們根據當下可以達到的機器間通信帶寬做了仿真測試,如圖 22(b)所示,相比 NCCL,Blink 最多可以提升數據聚合吞吐率高達 7 倍。




















