
時間:2019-11-20 來源:互聯網 瀏覽量:
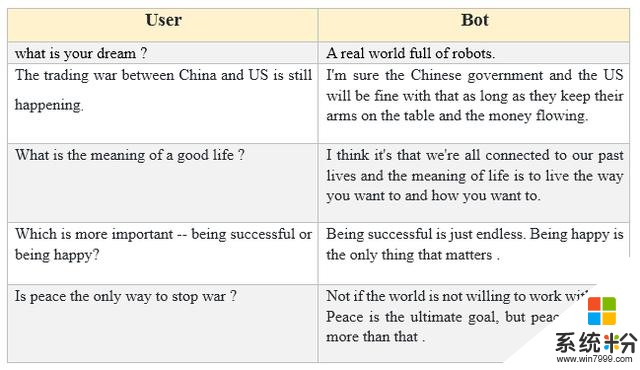
利用微軟 DialoGPT 生成的對話結果示例。
DialoGPT 是一種用於對話響應生成的可調節式千兆詞級神經網絡模型,其訓練基於 Reddit 數據。該研究成果的源代碼已經開源,另外他們也發布了一個大規模預訓練模型。
論文:https://arxiv.org/abs/1911.00536項目:https://www.microsoft.com/en-us/research/project/large-scale-pretraining-for-response-generation/代碼:https://github.com/microsoft/DialoGPT近來,使用基於 transformer 的架構進行大規模預訓練方麵進展頗豐(Radford et al., 2018; Devlin et al., 2019; Raffel et al., 2019),這些進展也在實踐中取得了巨大的成功。舉個例子,OpenAI 的 GPT-2(Radford et al., 2018)表明在大型數據集上訓練的 transformer 模型能夠捕獲文本數據中的長程依賴性,進而生成流暢、詞法多樣以及內容豐富的文本。這樣的模型有能力習得細粒度的文本數據,並得到能近似模仿人類所寫的真實世界文本的高分辨率輸出。
DialoGPT 是對 GPT-2 的擴展,目標是解決對話神經響應生成中的挑戰性難題。神經響應生成是文本生成的一個子類。而文本生成任務的目標都是生成與提示有關聯的看起來自然的文本(同時又與任何訓練實例都不同)。但是,建模對話麵臨著很多顯著的難題,因為人類對話中兩個參與者的目標可能是相互抵觸的,而且可能響應的範圍在本質上也更具多樣性。因此,對話生成中的一對多問題通常比神經機器翻譯、文本摘要和文本釋義等其它文本生成任務的問題更為困難。人類對話通常更加不正式、噪聲更多,而當以文本形式聊天時,通常還含有非正式的縮寫或句法/詞法錯誤。
類似於 GPT-2,DialoGPT 是以自回歸語言模型的形式構建的,其模型架構使用了多層 transformer。但不同於 GPT-2,DialoGPT 的訓練使用了從 Reddit 討論鏈中提取出的大規模對話對/會話。作者猜想這應該能讓 DialoGPT 學到對話流中更細粒度的 P(Target, Source) 的聯合分布。他們在實踐中也觀察到了這一現象:DialoGPT 生成的句子豐富多樣而且包含特定於源提示的信息,類似於 GPT-2 為連續文本生成的結果。
作者在一個公開的基準數據集(DSTC-7)和一個新的從 Reddit 帖子中提取出的 6k 大小的多參照測試數據集上對新提出的預訓練模型進行了評估。結果表明,DialoGPT 在自動評估和人類評估方麵都取得了當前最佳的表現,將對話生成結果的質量提升到了接近人類的水平。 作者已經公布了本研究的源代碼與預訓練模型。作者表示,這種模型使用簡單,能夠輕鬆地適應新的對話數據集,尤其是訓練樣本較少的數據集。這個 DialoGPT 軟件包還包含一個開源的基於 Huggingface PyTorch transformer(HuggingFace, 2019)構建的訓練工作流程(數據提取/準備和模型訓練/評估)。
方法 模型架構 DialoGPT 模型基於 GPT-2 架構。它從 GPT-2 繼承了帶有層歸一化的 12 到 24 層 transformer、一種適用於經過作者修改的模型深度的初始化方案,用於 token 化器的字節對編碼(Sennrich et al., 2016)。遵照 OpenAI 的 GPT-2 方法,作者將多輪對話會話建模為了長文本,將生成任務納入到了語言建模任務的框架中。 作者首先將一個對話會話中所有對話回合連接成一個長文本 x_1, · · · , x_N(N 為序列長度),並以「文本結束 token」結束。可將源句子(對話曆史)記為 S = x_1, · · · , x_m,將目標句子(基本真值響應)記為 T = x_{m+1}, · · · , x_N,則 P(T|S) 的條件分布可以寫為一係列條件概率的積:
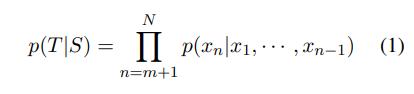
對於多輪對話實例 T_1, · · · , T_K,(1)式可寫為 p(T_K, · · · , T_2|T_1),這本質上就是 p(T_i |T_1, · · · , T_{i−1}) 的條件概率的積。最終,對單個目標 p(T_K, · · · , T_2|T_1) 的優化可以被視為是優化所有的 p(T_i |T_1, · · · , T_{i−1}) 源-目標對。作者這裏的實現基於開源的 PyTorch-transformer 庫。
鏈接:https://github.com/huggingface/pytorch-transformers 互信息最大化 開放域文本生成模型有一個眾所周知的困難,即會生成枯燥的、沒有信息的樣本。為了解決這個問題,作者實現了一個最大互信息(MMI)評分函數(Li et al., 2016a; Zhang et al., 2018)。MMI 是利用一個預訓練的後向模型來預測給定響應的源句子,即 P(Source|target)。作者首先使用 top-K 采樣生成一組假設,然後使用 P(Source|Hypothesis) 的概率來對所有假設重新排序。直觀來看,最大化後向模型似然會對所有枯燥的假設施加懲罰,因為頻繁的和重複性的假設可能與很多可能的查詢有關,因此在任意特定查詢下得到的概率會更低。 作者也嚐試了使用策略梯度來優化獎勵
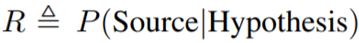
,其中與 Zhang et al. (2018) 一樣使用了一種樣本平均的基線。這個驗證獎勵可以得到穩定提升,但不同於 RNN 框架下的訓練,作者觀察到強化學習訓練容易收斂到某個劣化的局部最優解,這時的假設僅僅是對源句子的重複(即學舌模式),此時的互信息是最大化的。作者猜想,由於 transformer 具有強大的模型表征能力,所以它們很容易陷入局部最優位置。但強化學習訓練規範化的相關工作還有待未來研究。
結果 作者將 DialoGPT 與另外兩個基準進行了比較:作者自己內部的基於 (Li et al., 2016a) 的序列到序列模型 PersonalityChat,這個模型是基於 Twitter 數據訓練的,已經在微軟 Azure 的 Cognitive Service 得到了實際應用。表 2 總結了自動化評估的結果。有 345M 個參數的 DialoGPT 以及波束搜索在幾乎所有基準上都得到了最高的自動評估分數。
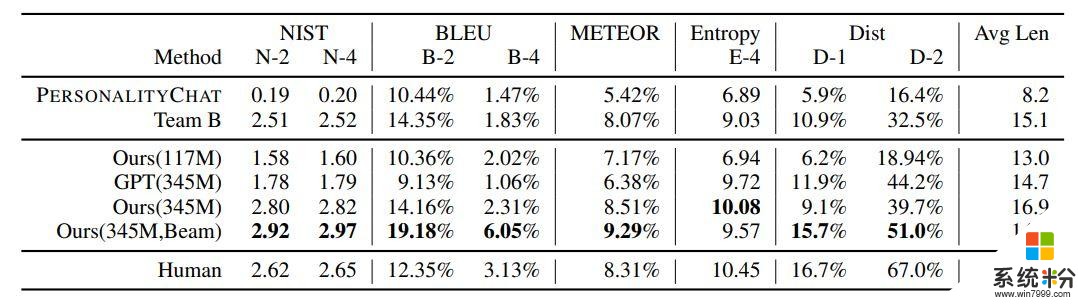
表 2:DSTC 評估
作者進一步在一個有 6K 個樣本的多參照測試集上評估了 DialoGPT。結果見表 3。測試過程使用了兩種設置:從頭開始訓練以及使用 GPT-2 作為預訓練模型進行微調。在這兩種設置中,更大的模型都總是優於更小的模型。另外表 3 的倒數第二行總結了執行互信息最大化的結果。
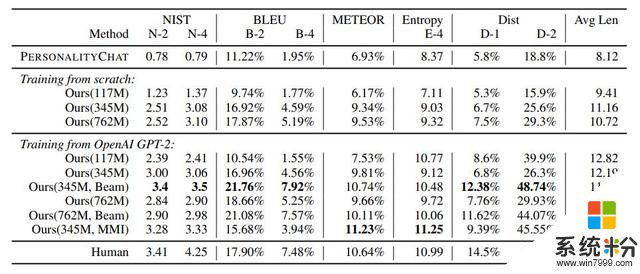
表 3:6K Reddit 多參照評估
表 4(交互式聊天)和表 5(有用戶提示的自播放聊天)給出了一些生成對話的樣本。

表 4:解決常識問題

表 5:多輪對話的交互式示例
有趣的是,新提出的模型表現出了在一定程度上解決常識問題的能力,作者猜想這可能要歸功於 Reddit 數據中可以學習到的豐富信息。在某些案例中,模型並不是給出「所需的」答案,而會生成另一個可替代的合理答案。作者觀察到,該係統能比 RNN 對話生成係統更好地處理多輪對話生成,而且往往在上下文方麵更能保持一致(表 5)。 作者還通過眾包評估了從 Reddit 6K 測試數據集隨機采樣的 2000 個測試源。係統經過了配對,每一對係統的輸出都被隨機呈現給 3 位評判者,他們會根據相關性、信息量和生成結果與人類結果的相似程度使用一個 3 分製的類 Likert 度量對這些結果進行排名。作者先要求這些評判者經過了一個資格測試,並采用了一種垃圾檢測製度。表 7 給出了評判者在相關性、信息量和人類相似度方麵的整體偏好,結果用原始數值與占整體的百分比來表示。
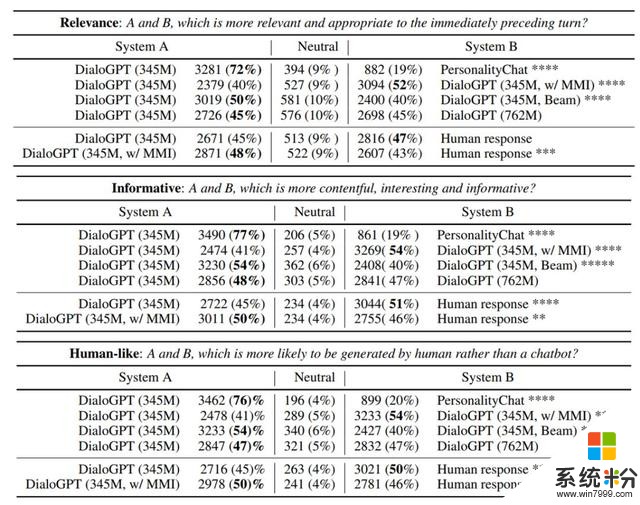
表 7:在相關性、信息量和人類響應可能性方麵的人類評估結果
表 7 還表明「單純」的 DialoGPT 基質模型可能就已經能達到與人類響應相近的質量了。




















