
時間:2019-10-17 來源:互聯網 瀏覽量:

編 | 雲鵬
導語:它已經掌握了28996個詞彙,但它還要學習更多。
智東西10月17日消息,去年10月穀歌發布的BERT模型已經在閱讀理解測試中全麵超越人類,今天微軟的UniLM模型將這一領域的研究推向了新的高度。
微軟近日推出的UniLM AI訓練模型通過改變傳統AI係統學習方式,成功實現單向預測,突破了自然語言處理中大量文本修改的瓶頸。
一、改變雙向預測方式
語言模型預訓練(Language model pretraining)是一種機器語言處理技術,它通過依據文本預測詞彙的方式,教會機器學習係統(machine learning systems)如何把文本情景化地表述出來。它代表了自然語言處理(natural language processing)領域的最新突破。
目前,像穀歌的BERT模型,是雙向預測,也就是根據左右兩側的詞彙來預測,因此不適合大量文本的處理。
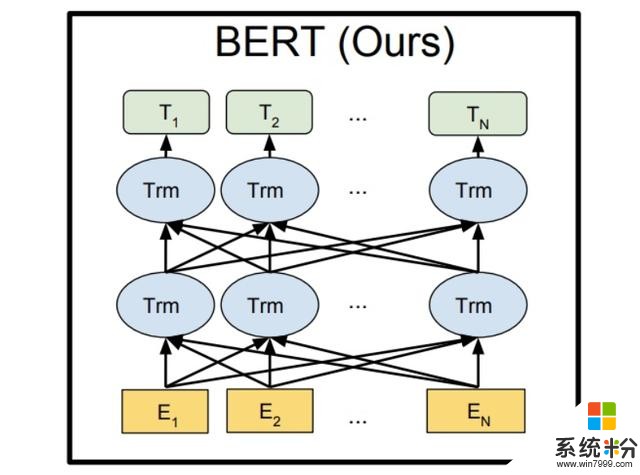
▲穀歌BERT模型
為此,微軟科學家們研究出了UniLM(UNIfied pre-trained Language Model)這種新模型。該模型可以完成單向、序列到序列(sequence-to-sequence)和雙向預測任務,並且可以針對自然語言的理解和生成進行微調(fine-tuned)。
微軟表示它在各類常見的基礎測試中都要優於BERT,並且在自然語言處理的一些測試項目中取得了該領域的最新突破。
二、“變形金剛”的威力
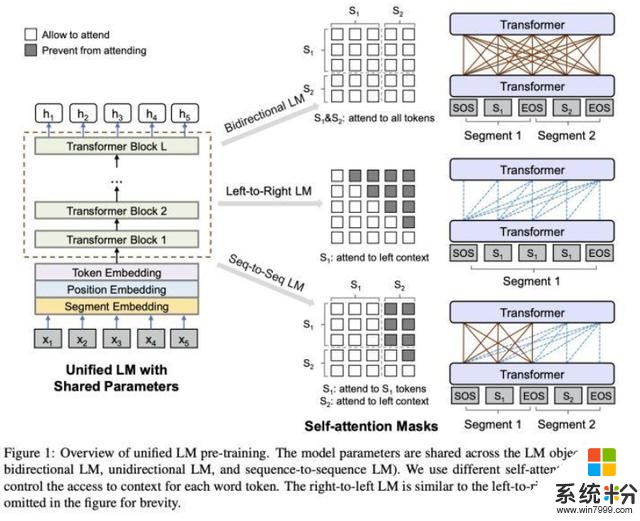
▲UniLM模型概覽
UniLM模型是一個多層網絡,其核心是由Transformer AI模型組成的,這些模型針對大量文本進行了共同的預訓練,並針對語言建模進行了優化。
跟其他AI係統學習預測方式不同的是,Transformer AI將每個輸出元素都連接到每個輸入元素。它們之間的權重是可以動態調整的。
微軟研究人員認為,經過預訓練的UniLM與BERT類似,可以進行微調以適應各種下遊任務。但是與BERT不同,UniLM可以通過一種特殊方式(using different self-attention masks),彙總不同類型語言模型的上下文。
此外,Transformer網絡可以共享從曆史訓練中學到的數據,不僅使學習到的文本表示更加通用,也降低了對單一任務的處理難度。
三、學海無涯
微軟研究人表示,UniLM通過學習英語維基百科(English Wikipedia)和開源BookCorpus的文章後,已經擁有高達28996的詞彙量。並且在預培訓後,UniLM的跨語言任務表現也非常好。
團隊人員表示,UniLM未來發展的空間還很大,例如在“網絡規模(web-scale)”的文本語料庫上訓練較大的模型來突破當前方法的局限性。
他們還希望讓UniLM在跨語言任務中取得更大突破。
結語:自然語言處理領域的重大突破
自然語言處理,是人工智能界、計算機科學和語言學界所共同關注的重要問題,它對於實現人機間的信息交流起著重要作用。
穀歌BERT和微軟的UniLM是這一領域的開拓者,後者通過單向預測突破了大量文本處理的難題,進而提升了此類AI在實際應用中的價值。
此次穀歌霸主地位被動搖,也勢必將在該領域引發更加精彩的AI大戰。
原文來源:Venturebeat




















