
時間:2019-06-23 來源:互聯網 瀏覽量:
如果你被要求畫這樣一張圖片——幾個穿著滑雪服的人站在雪地裏,你很可能會先在畫布中間合理位置畫出三四個人的輪廓,然後繼續畫他們腳下的滑雪板。雖然沒有具體說明,但你可能會決定給每個滑雪者都增加一個背包,以配合他們預期的運動。最後,你會仔細地填充細節,也許把他們的衣服塗成藍色,圍巾塗成粉色,把所有的背景都塗成白色,讓這些人看起來更真實,並確保他們周圍的環境符合描述。最後,為了使場景更加生動,你甚至可以用一些棕色的石頭與白雪對比突出表示這些滑雪者在山裏。
現在有一個機器人可以做到這一切。
微軟研究院正在開發的新的人工智能技術可以理解自然語言描述,繪製圖像布局草圖,合成圖像,然後根據提供的布局和單個詞彙細化細節。換句話說,這個機器人可以從類似於說明的日常場景描述文本中生成圖像。根據於加利福利亞州長灘市舉行的 CVPR 2019 上發表的文章「Object-driven Text-to-Image Synthesis via Adversarial Training」所述,標準測試結果表明,相對於前一代最先進的複雜日常場景文本轉圖像技術,上述機器人有成熟的機製,可顯著提高生成圖像的質量。該論文是微軟人工智能研究院 Pengchuan Zhang、 Qiuyuan Huang、 Jianfeng Gao,微軟的 Lei Zhang,JD 人工智能研究院的 Xiaodong He,以及紐約州立大學奧爾巴尼分校 Wenbo Li、Siwei Lyu(Wenbo Li 曾在微軟人工智能研究院實習)合作的成果。
基於描述的繪圖機器人麵臨兩個主要挑戰。第一個挑戰是在日常場景中會出現很多種類的物體,機器人應該能理解所有種類的物體並將其畫出來。前述文本轉圖像生成方法使用圖像—說明對,這些方法僅為生成單個目標提供非常粗粒度的監督信號,限製了它們對物體的圖像生成質量。在這項新技術中,研究人員使用了 COCO 數據集,該數據集包含 80 個常見目標分類裏麵 150 萬個目標實例的標簽和分割圖,使得機器人能夠學習這些目標的概念和外觀。這種用於目標生成的細粒度監督信號顯著提高了這些常見目標類型的生成質量。
第二個挑戰是理解和生成一個場景中多個目標之間的關係。在幾個特定領域,例如人臉、鳥類和常見目標,在生成隻包含一個主要目標的圖像方麵已經取得了巨大的成功。然而,在文本轉圖像的生成技術中,在包含多個目標和豐富關係的更複雜場景中生成圖像仍然是一個重大的挑戰。這個新的繪圖機器人從 COCO 數據集共現模式中學會了生成目標的布局,然後根據預先生成的布局生成圖像。
目標驅動的專注圖像生成微軟人工智能研究院的繪圖機器人核心是一種被稱為生成式對抗網絡( GAN)的技術。GAN 由兩個機器學習模型組成:一個是根據文本描述生成圖像的生成器,另一個是根據文本描述判斷生成圖像可靠性的鑒別器。生成器試圖讓假照片通過鑒別器,而鑒別器不希望被愚弄。兩者共同工作,鑒別器推動生成器趨向完美。
繪圖機器人在一個包含 10 萬幅圖像的數據集上進行訓練,每個圖像都有突出的目標標簽和分割圖,以及五個不同的標題,允許模型構思單個目標和目標之間的語義關係。例如,GAN 在比較有狗和沒有狗的描述的圖像時,學習狗應該是什麼樣子。
GANs 在生成隻包含一個突出目標,例如人臉、鳥類或狗的圖像時表現很好,但是在生成更複雜的日常場景時,圖像生成的質量就會停滯不前,比如描述為「一個戴頭盔的女人正在騎馬」的場景(參見圖 1)。這是因為這類場景包含了多個目標(女人、頭盔、馬),這些目標之間有著豐富的語義關係(女人戴頭盔、女人騎馬)。機器人首先必須理解這些概念,並將它們放在具有意義的布局的圖像中。然後,需要一個更強的監督信號來教 GANs 進行目標生成和布局生成,從而完成語言理解與圖像生成任務。

圖 1:具有多個目標和關係的複雜場景
當人類繪製這些複雜的場景時,我們首先決定繪製的主要目標,並通過在畫布上為這些目標設置邊框來進行布局。然後,通過反複檢查該目標相應的描述來實現對每個目標的聚焦。為了捕捉人類的上述特點,研究人員創造了一種被他們稱為目標驅動的專注 GAN,或 ObjGAN,來對人類以目標為注意力中心的行為進行數學建模。ObjGAN 通過將輸入文本分解成單獨的單詞並將這些單詞與圖像中的特定目標進行匹配,從而實現上述人類的特點。
人類通常會從兩個方麵來改進繪圖:單個目標的真實感和圖像補丁的質量。ObjGAN 通過引入兩個鑒別器來模擬這種行為---智能目標鑒別器和智能補丁鑒別器。智能目標鑒別器試圖確定生成的目標是否真實,以及該目標是否與語句描述一致。智能補丁鑒別器試圖判斷這個補丁是否真實,以及這個補丁是否與語句描述一致。
相關工作:故事可視化最先進的文本轉圖像模型能夠基於單一語句描述生成真實的鳥類圖像。然而,文本轉圖像生成技術可以遠遠不止基於單一語句合成單一圖像。由微軟研究院 Jianfeng Gao,微軟動態 365 人工智能研究員 Zhe Gan、Jingjing Liu 和 Yu Cheng,杜克大學 Yitong Li、David Carlson 和 Lawrence Carin,騰訊人工智能研究院 Yelong Shen,以及卡耐基梅隆大學 Yuexin Wu 所著的論文「StoryGAN: A Sequential Conditional GAN for Story Visualization」中更進一步的提出了一個稱之為故事可視化的新任務。給定一個多語句段落,該段落構成的完整故事可以被可視化,即生成一係列的圖像,且每個語句對應一個圖像。這是一個具有挑戰性的任務,因為繪圖機器人不僅需要想象一個適合故事的場景,為故事中出現的不同角色之間的交互建模,而且還必須能夠在動態場景和角色之間保持全局一致性。這一挑戰還沒有任何單一圖像或視頻生成方法能夠解決。
研究人員提出了一種基於序列條件 GAN 框架新的故事-圖像-序列生成模型,稱之為 StoryGAN。該模型的獨特之處在於,它由一個可以動態跟蹤故事流的深層上下文編碼器和兩個故事與圖像層級的鑒別器組成,從而增強圖像質量和生成序列的一致性。StoryGAN 還可以自然地擴展為交互式圖像編輯,其可以根據文本指令按順序編輯輸入的圖像。在這種情況下,一係列用戶指令將作為「故事」輸入。因此,研究人員修改了現有的數據集,創建了 CLEVR-SV 和 Pororo-SV 數據集,如圖 2 所示。
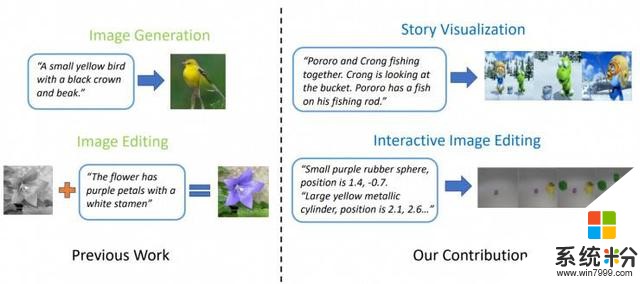
圖 2:簡單圖像生成 VS 故事可視化
實際應用——一個真實的故事在實際應用中,文本轉圖像生成技術可以作為畫家和室內設計師的素描助手,也可以作為聲控照片編輯工具。隨著計算能力的提高,研究人員設想了一種基於劇本生成動畫電影的技術,能使動畫製作者的工作產量變大,同時省去一些手工勞動。
目前,生成的圖像與照片的真實感相差甚遠。生成的圖像中單個物體幾乎都會暴露出缺陷,比如模糊的人臉或變形的公交車。這些缺陷清楚地表明,該圖像是電腦生成而非人類創造。盡管如此,ObjGAN 圖像的質量明顯好於以前同類中最好的 GAN 圖像,並且在通往通用人工智能的道路上起到了裏程碑作用。
人工智能和人類要共享同一個世界,就必須要有一種與他人互動的方式。語言和視覺是人類和機器相互作用最重要的兩種方式。文本轉圖像生成技術是語言視覺多模態智能研究的重要內容之一。
ObjGAN 和 StoryGAN 的開源代碼請在 GitHub 上查看。
via:Microsoft blog
ObjGAN:https://arxiv.org/pdf/1902.10740.pdf
StoryGAN:https://arxiv.org/abs/1812.02784
AI 科技評論編譯整理。




















