
時間:2018-09-29 來源:互聯網 瀏覽量:
微軟推出了最新版旗艦產品關係數據庫管理係統SQL Server 2019的預覽版,重點介紹了新的大數據功能。

該公司表示,v2019通過將Apache Spark和Hadoop分布式文件係統(HDFS)與SQL Server數據庫引擎打包在一起,創建了一個統一的數據平台,幫助數據開發人員無縫地提取,存儲和分析大量數據。
微軟表示,這種集成對於在大數據時代發展產品至關重要,因為SQL Server的單個實例從未被設計或構建用於處理大數據分析實施中常見的PB級或EB級分析。

微軟 SQL Server 2019
此外,微軟在其Ignite會議上宣布預覽時表示,這種新的大數據集成使SQL Server進一步超越其作為傳統數據庫的根源。 SQL Server的首席PM經理Asad Khan在 博客文章 中詳細闡述了這個和其他細節。 “與每個版本一樣,SQL Server 2019通過智能查詢處理,數據合規工具和對持久內存的支持,繼續為每個工作負載突破安全性,可用性和性能的界限,”Khan說。 “借助SQL Server 2019,您可以承擔任何數據項目,從傳統的SQL Server工作負載(如OLTP,數據倉庫和BI)到AI和高級數據的高級分析。”
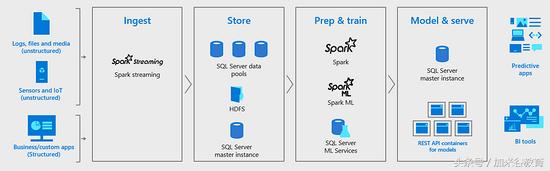
大數據集群提供“完整的AI平台”(來源:微軟)。
然而,這是內置的Spark和HDFS功能,突出了預覽公告。 微軟稱這種新的集成架構為“大數據集群”,該公司的首席項目經理Travis Wright 在9月25日 博客文章 中提供了更多信息。 “大數據集群中的SQL Server 2019關係數據庫引擎利用彈性可擴展的存儲層,集成SQL Server和HDFS,可擴展到數PB的數據存儲,”Wright說。 “現在屬於SQL Server的Spark引擎使數據工程師和數據科學家能夠利用開源數據準備和查詢編程庫的強大功能,在可擴展的分布式內存計算層中處理和分析高容量數據。“
“可能最明顯的采用障礙將是K8s/容器采用數據庫工作負載,”Wright回答道。 “公司正在加入這一行列,類似於虛擬化。[另一個障礙是]容器問題。當人們看到將SQL Server可用性組部署到K8中是多麼容易,這讓人很容易理解。”
此外,新的預覽中突出顯示了大數據集群中的人工智能(AI)功能,這與微軟在奧蘭多正在進行的Ignite會議上宣布的許多新產品和功能上強調人工智能功能的重點相呼應。
“SQL Server 2019大數據集群提供了一個完整的AI平台,”微軟表示。 “可以通過Spark Streaming或傳統SQL插件輕鬆獲取數據並存儲在HDFS,關係表,圖形或JSON / XML中。可以使用Spark作業或Transact-SQL(T-SQL)查詢準備數據並將其輸入使用各種編程語言(包括Java,Python,R和Scala)在Spark或SQL Server主實例中進行機器學習模型訓練例程。然後可以在Spark中的批量評分作業中運行生成的模型,在T-SQL中存儲用於實時評分的程序,或封裝在大數據集群中托管的REST API容器中的程序。“
D'Antoni還在單獨的總結中介紹了SQL Server 2019中的許多其他新功能,其中 詳細介紹 了安全性,數據庫性能增強,可用性等。
“SQL Server 2019仍然處於早期預覽階段,”D'Antoni說道,他是一位擁有超過十年經驗的建築師和SQL Server MVP。 “從現在到SQL Server 2019普遍可用的時間還有很多事情要做。但是,很明顯,微軟繼續在數據平台上進行大量投資,並努力使其在服務器和服務器之間保持可用和一致。數據平台,擴大了更廣泛的數據服務受眾。“
成都加米穀教育大數據培訓機構,專注於大數據人才培養,大數據開發、數據分析與挖掘新課谘詢報名中...




















