
時間:2018-09-16 來源:互聯網 瀏覽量:
近年來,人工智能技術與醫療健康領域的融合不斷加深,以人工智能醫療發展最為迅速的美國為例,科技巨頭和資本巨頭都在積極布局智能醫療產業。比如,IBM Watson能夠快速篩選癌症患者記錄,為醫生提供可供選擇的治療方案;穀歌DeepMind與英國國家健康體係(NHS)合作共同開發新技術;微軟發布了麵向個人的健康管理平台,整合不同的健康及健身設備搜集的數據等。
可以說,智能醫療是未來一個重要發展趨勢。但是智能醫療真的靠譜嗎?眾所周知,在AI訓練的過程中,用於訓練醫療係統的數據對於確保診斷結果至關重要,因為研究一再表明,人工智能算法是他們學習數據的奴隸。換句話說,如果AI研究員使用的醫療數據集存在偏見,那麼將會對人的生死有很大的影響。在這種情況下,AI要成為世界的醫生,那麼就需要更好的教科書。
文/灰灰
來源/人工智能觀察(ID:Aiobservation)
在昨天的蘋果秋季新品發布會上,除了iPhone外,新一代Apple Watch也是一大亮點。在這款手表中,最值得注意的是其繪製心電圖(KEG)的功能:用戶隻需打開一個應用程序,把手指放在數字表冠(Digital Crown)上,便可觸發EKG。這是科技與醫療最新的結合成果。據悉,目前蘋果已經得到了FDA的許可,允許其手表作為醫療設備使用。
實際上,除了蘋果等科技巨頭外,不少大型製藥公司也都在采用人工智能技術進行研發,可以說,醫療保健已經成為了人工智能研究和應用的重點領域。舉個例子,穀歌DeepMind的神經網絡在診斷50種眼疾方麵其準確性已經與人類專家不相上下;而在製藥公司方麵,大型藥企Merck與創企Atomwise達成合作,後者試圖將深度學習用於新藥開發,以降低高額的研發費用,這也是將人工智能技術應用於醫藥健康領域的經典案例之一。
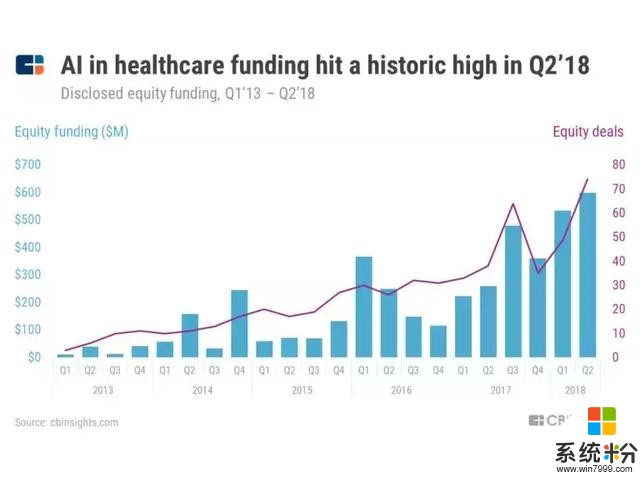
根據CB Insights的數據,醫療領域的創業公司自2013年以來已經完成了576億筆融資交易,總計金額達4.3億美元,超過了人工智能融資活動中的所有其他行業,可見這一市場的潛力。
不過,對人工智能來說,它也麵臨著醫療行業獨有的技術和可行性的挑戰,比如沒有標準格式或患者數據的中央存儲庫,以及在不可讀的PDF格式的患者文件上提取信息等,但最主要的還是在於確保數據的準確性以及客觀性。
以美國為例,談AI-as-a-medical-device的興起今年4月,FDA批準了一個名為IDx-DR的人工智能軟件的應用,該軟件可以在不需要專家意見的情況下,對糖尿病視網膜病變的患者進行篩查。這一舉動加快了將相關產品推向市場。比如,IDx是近幾個月FDA批準用於臨床商業應用的眾多AI軟件產品之一。而Viz.ai也被批準用於分析CT掃描,並就潛在的中風患者做出通知。
目前,FDA工作的重點是明確定義和管理“AI-as-a-medical-device”(軟件即醫療設備),特別是考慮到最近人工智能的快速發展。對此,FDA計劃將今年1月試行的一個項目“pre-cert”應用於AI,這將使企業能夠“對其設備進行微小的改動,而不需要每次都提交”。
蘋果公司正在“擾亂”臨床試驗盡管努力將健康記錄數字化,但機構和軟件係統之間如何實現健康信息的共享,仍然是醫療領域麵臨的一個巨大挑戰,尤其是在臨床試驗中,將正確的試驗與正確的患者進行匹配對臨床研究團隊和患者來說都是一個耗時且極具挑戰性的過程。
但蘋果公司正在改變醫療領域的信息流動,並為人工智能開辟了新的可能性,特別是圍繞臨床研究人員如何招募和監控患者。具體而言,自2015年以來,蘋果推出了兩個開源框架——ResearchKit和CareKit,以幫助臨床試驗招募患者並遠程監控他們的健康狀況。該框架允許研究人員和開發人員創建醫療應用程序來監控人們的日常生活。

比如,杜克大學的研究人員開發了一款Autism&Beyond應用程序,通過iPhone的前置攝像頭和麵部識別算法來篩選自閉症兒童。同樣,近10,000人使用mPower應用程序研究帕金森病患者,他們也同意與研究團隊共享自己的數據。
此外,蘋果還與Cerner和Epic等流行的EHR供應商合作解決互操作性問題。今年6月,蘋果為開發人員推出了Health Records API,用戶現在可以選擇與第三方應用程序和醫學研究人員共享數據,為疾病管理和生活方式監控開辟新的機會。
AI要成為世界的醫生,就需要更好的教科書想象一下,存在這樣一種測試人類是否患有老年癡呆的方法:你隻需通過說話對一張照片的描述,軟件就能分析得出結果,這是一個快速而簡單的準確率可達90%的方法,但可能除了你以外,對任何人都不起作用。
其實,這是一個真實存在的案例。總部位於多倫多的創業公司Winterlight Labs正在為老年癡呆症,帕金森氏症以及多發性硬化症等神經係統疾病建立聽覺測試。但是,在2016年發表了初步研究後,該團隊遇到了障礙:該技術僅適用於部分講英語的加拿大人。這就意味著,語言障礙成為了Winterlight的最大挑戰。
而類似的AI係統,正逐漸走出實驗室成為真正幫助做出醫療決策的前沿科技。每個公司基本都采用了相同的模式:收集以前患者的大量數據,並用它們預測新患者會有什麼情況發生。在這種情況下,保證數據的準確性、安全性以及客觀性對於研究結果來說至關重要。

還有一個值得注意的是,公開供AI研究員使用的醫療數據集中都存在一種偏見,特別是美國,這也並不是什麼秘密:醫療數據非常男性化、白人化的,這在現實世界中會產生很嚴重的影響。2014年的一項研究追蹤了20多年的癌症死亡率,結果顯示,缺乏不同的研究對象是美國黑人死於癌症的可能性高於美國白人的一個重要原因。
雖然關於AI偏見的討論會讓人感到不舒服,畢竟偏見是隱藏的,也很棘手,但其危險卻顯而易見。而在智能醫療領域,這些偏見的結果往往意味著有一群人會比另一群人獲得更好的醫療保障,不管是以性別或種族為特征,還是語言、膚色甚至是生活方式。
對此,一些研究員正試圖收集更多的不同數據進行研究。像位於奧馬哈的 Fred and Pamela Buffett Cancer Center,就保留了病人的基因組數據來訓練人工智能。而在全球範圍內,存在國際癌症基因組聯盟(ICGC),旨在收集來自世界各地的癌症患者的基因組標記。
據了解,該項目有來自近20個不同國家的數十種癌症的數據,但存在嚴重的不平衡:許多國家僅存在一種疾病的數據集。比如,美國有32個項目(人口3.26億),但印度隻有一個(13億),整個非洲大陸沒有(約13億)。
而意識到問題的存在,積極采取措施進行,對現在智能醫療的發展來說,是迫在眉睫的。就像IBM已經在更新麵部識別工具,以便讓它更具包容性來減少機器學習中存在的偏見。




















