
時間:2018-09-12 來源:互聯網 瀏覽量:
按:本文為 AI 研習社編譯的技術博客,原標題 Face detection - An overview and comparison of different solutions,作者為 David Pacassi Torrico。
翻譯 | 李灝 江舟 校對 | Lamaric 審核 | Lamaric

哪一個人臉識別 API 是最好的?讓我們看看亞馬遜的 Rekognition、穀歌雲 Vision API、IBM 沃森 Visual Recognition 和 微軟 Face API。
Part 1:基於互聯網提供軟件服務的供應商
TLDR:如果你想盡可能快的使用 API,可以直接查看我在 Github 上的代碼。
你曾經有過人臉識別的需要嗎?
可能隻是為了提高圖片裁剪成功率,保證一張輪廓圖片真實的包含一張人臉,或可能隻是簡單從你的數據集中發現包含指定人物的圖片(在這種情況下)。
哪一個人臉識別軟件服務供應商對你的項目來說是最好的呢?
讓我們深入了解它們在成功率,定價和速度方麵的差異。
在這篇文章裏,我將會分析以下人臉檢測 API:
亞馬遜 Rekognition
穀歌雲 Vision API
IBM 沃森 Visual Recognition
微軟 Face API
人臉檢測是如何工作的?
在我們深入分析不同的解決方案之前,讓我們首先了解下人臉檢測是如何工作的。
Viola–Jones 人臉檢測
2001 年這一年,Jimmy Wales 和 Larry Sanger 建立了維基百科,荷蘭成為世界上第一個將同性婚姻合法化的國家,世界也見證了有史以來最悲慘的恐怖襲擊之一。
與此同時,兩位聰穎的人,Paul Viola 和 Michael Jone,一起開始了計算機視覺的革命。
直到 2001 年,人臉檢測還不是很精確也不是很快。而就在這一年,Viola Jones 人臉檢測框架被提出,它不僅在檢測人臉方麵有很高的成功率,而且還可以進行實時檢測。
雖然人臉和物體識別挑戰自 90 年代以來就一直存在,但在 Viola - Jones 論文發布後,人臉及物體識別變得更加繁榮。
深度卷積神經網絡
其中一個挑戰是自 2010 年以來一直舉辦的 ImageNet 大規模視覺識別挑戰。在前兩年,頂級團隊主要是通過 Fisher 向量機和支持向量機的組合工作,而 2012 年這一切改變了。
多倫多大學的團隊(由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 組成)首次使用深度卷積神經網絡進行物體檢測。他們以 15.4 % 的錯誤率獲得第一名,而第二名隊伍的錯誤率卻高達 26.2 %!
一年後,2013 年,前五名的每個團隊都在使用深度卷積神經網絡。
那麼,這樣的網絡是如何工作的呢?
今年早些時候,穀歌發布了一個易於理解的視頻:
亞馬遜、穀歌、IBM 和微軟現在使用著什麼?
從那以後,並沒有太大變化。今天的供應商仍然使用深度卷積神經網絡,當然可能會與其他深度學習技術相結合。
顯然,他們沒有公布自己的視覺識別技術是如何工作的。我發現的信息是:
亞馬遜:深度神經網絡
穀歌: 卷積神經網絡
IBM: 深度學習算法
微軟: 人臉算法
雖然它們聽起來都很相似,但結果有一些不同。
在我們測試它們之前,讓我們先看看定價模型吧!
定價
亞馬遜、穀歌和微軟都有類似的定價模式,這意味著隨著使用量的增加,每次檢測的價格會下降。
然而,對於 IBM,在你的免費層使用量用完之後,你就要為每次調用 API 支付相同的價格。
Microsoft 為你提供了最好的免費協議,允許你每月免費處理 30000 張圖片。
如果你需要檢測更多,則需要使用他們的標準協議,是從第一張圖片開始付費的。
價格比較
話雖如此,讓我們計算三種不同配置類型的成本。
條件 A:小型初創公司/企業可每月處理 1000 張圖片
條件 B:擁有大量圖像的數字供應商,每月可處理 100,000 幅圖像
條件 C:數據中心每月處理 10,000,000 張圖像。
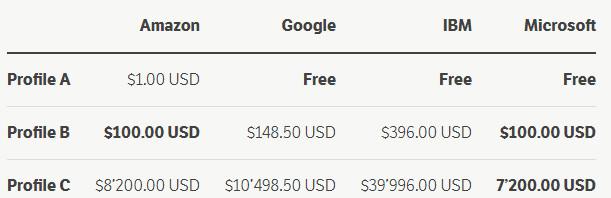
從數據上看,對於小客戶來說,定價沒有多大差別。雖然亞馬遜從第一張圖片開始收費,但處理 1000 張圖片仍然隻需要一美元。然而,如果你不想支付任何費用,那麼穀歌、IBM 或微軟將是你想要選擇的供應商。
注意:亞馬遜提供了免費協議,你可以免費處理前 12 個月,每月 5000 張圖片!然而,在這個 12 個月的試用期後,你就需要從這時第一張圖片付費了。
大量使用 API 的情況
如果你確實需要處理數百萬張圖片,那麼比較每個供應商的處理規模就變得很重要了。
以下是在一定數量的圖片後,為 API 使用支付的最低價格列表。
IBM 會不斷向你收取每 1,000 張圖片 4.00 美元的費用(無縮放比例)
Google 在第 5,000,000 張圖片之後,價格降到 0.60 美元(每 1000 張圖片)
亞馬遜會在第 100,000,000 張圖片之後,價格降到 0.40 美元(每 1000 張圖片)
微軟會在第 100 ' 000 ' 000 張圖片之後,價格降到 0.40 美元(每 1000 張圖片)
因此,比較價格,微軟(和亞馬遜)似乎是贏家。但他們能否在成功率、速度和整合度上占優麼?讓我們看一看!
動手吧!讓我們試試不同的 API
有夠多的理論和數字了,讓我們直接深入研究編碼!你可以在我的 GitHub存儲庫中找到這裏使用的所有代碼。
設置我們的圖像數據集
首先要做的事,在我們掃描人臉圖像之前,讓我們設置圖像數據集。
在這篇博客文章中,我已經從 pexels.com 下載了 33 張圖片,非常感謝圖片的貢獻者/攝影師以及感謝 Pexels!
這些圖像已經提交到了 GitHub 存儲庫,所以如果你隻想開始使用 API,則不需要搜索任何圖像。
編寫基本測試框架
框架可能是錯誤的,因為我的自定義代碼隻包含兩個類。然而,這兩個類幫助我輕鬆地分析圖像(元數據)數據,並在不同的實現中有盡可能少的代碼。
一個非常簡短的描述:FaceDetectionClient 類保存有關圖像存儲位置、供應商詳細信息和所有處理過的圖像(作為 FaceDetectionImage 對象)的一般信息。
比較供應商的 SDK
因為我最熟悉 PHP,所以我決定在這次測試中堅持使用 PHP。我想指出每個供應商提供了什麼樣的 SDK(截至今天):
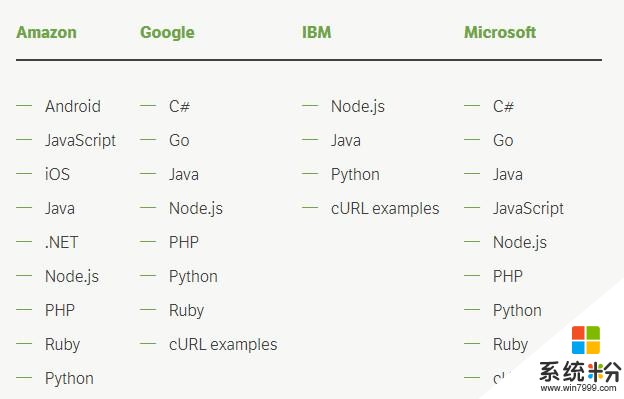
注意:微軟實際上並沒有提供任何 SDK,但他們為上麵列出的技術提供了代碼示例。
如果你仔細閱讀了這些列表,你可能會注意到 IBM 不僅提供了最少數量的 SDK,而且還沒有提供針對 PHP 的 SDK。然而,這對於我來說並不是一個大問題,因為他們提供了 cURL 示例,這些示例幫助我輕鬆地為一個(非常基本的)IBM 視覺識別客戶端類編寫了 37 行代碼。
集成供應商的 API
獲取 SDK 非常容易。使用 Composer 更容易。然而,我確實注意到一些可以改進的東西,以便開發者的生活變得更輕鬆。
亞馬遜
我從亞馬遜的識別 API 開始。瀏覽他們的文檔後,我真的開始覺得有點失落。我不僅沒找到一些基本的例子(或者無法找到它們?),但我也有一種感覺,我必須點擊幾次,才能找到我想要的東西。有一次,我甚至放棄了,隻是通過直接檢查他們的 SDK 源代碼來獲得信息。
另一方麵,這可能隻發生在我身上?讓我知道亞馬遜的識別對你來說是容易(還是困難)整合的吧!
注意:當 Google 和 IBM 返回邊界框坐標時,Amazon 會返回坐標作為整體圖像寬度/高度的比率。我不知道為什麼,但這沒什麼大不了的。你可以編寫一個輔助函數來從比率中獲取坐標,就像我一樣。
穀歌
接下來是穀歌。與亞馬遜相比,他們確實提供了一些例子,這對我幫助很大!或者也許我已經處於投資不同 SDK的心態了。
不管情況如何,集成 SDK 感覺要簡單得多,而且我可以花費更少的點擊次數來檢索我想要的信息。
IBM
如前所述,IBM(還沒有?)為 PHP 提供一個 SDK。然而,通過提供的 cURL 示例,我很快就建立了一個自定義客戶端。如果已經能提供一個 cURL 例子,那麼你使用它也錯不了什麼了。
微軟
看著微軟的 PHP 代碼示例(使用 Pear 的 HTTP _ request2 包),我最終為微軟的 Face API 編寫了自己的客戶端。
我想我隻是一個 cRUL 人。
評估者的可靠性
在我們比較不同的人臉檢測 API 之前,讓我們先自己掃描圖像吧!一個普通的人能檢測到多少張臉?
如果你已經看過我的數據集,你可能已經看到了一些包含棘手麵孔的圖像。棘手是什麼意思?好吧,指的是隻看到一張臉的一小部分或這張臉處於一個不尋常的角度時。
是時候做一個小實驗了
我瀏覽了所有的圖片,記下了我認為已經檢測到的麵孔數量。我會用這個數字來計算每個供應商對圖片的成功率,看看它是否能檢測到像我一樣多的麵孔。
然而,設置僅由我單獨檢測到的預期麵部數量對我來說似乎有點太偏頗了。我需要更多的意見。這時,我懇請我的三位同事瀏覽我的照片,並告訴我他們會發現多少張臉。我給他們的唯一任務是告訴我你能探測到多少張臉,而不是頭。我沒有定義任何規則,我想給他們任何可以想象的自由來完成這項任務。
什麼是臉?
當我瀏覽圖像檢測麵部時,我隻計算了至少四分之一左右可見的每張臉。有趣的是,我的同事提出了一個略微不同的麵部定義。
同事 1:我也計算過我大多無法看到的麵孔。但我確實看到了身體,所以我的腦海裏告訴我有一張臉。
同事 2:如果我能夠看到眼睛,鼻子和嘴巴,我會把它算作一張臉。
同事 3:我隻計算了能夠在另一張圖像中再次識別的臉部。
樣例圖片 #267855

在這張照片中,我和我的同事分別檢測到了 10、13、16 和 16 張麵孔。我決定取平均值,因此得到了 14。我對每個人是如何想到不同的人臉檢測技術這一點非常的感興趣。
話雖如此,我還是使用了我和同事的平均人臉計數來設定一幅圖像中檢測到的預期人臉數量。
結果比較
現在我們已經設置了數據集和代碼,讓我們處理所有競爭對手的所有圖像並比較結果。
我的 FaceDetectionClient 類還附帶一個方便的 CSV 導出格式,它提供了一些分析數據。
這是我得到的結果:
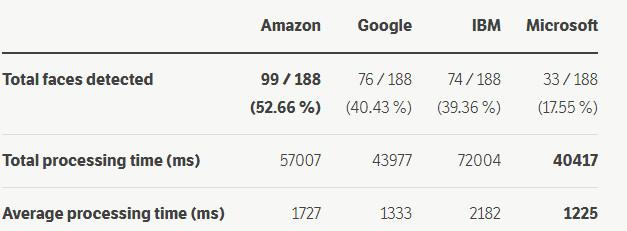
成功率很低?
亞馬遜能夠檢測到 52.66 % 的人臉,穀歌 40.43 %,IBM 39.36 %,微軟甚至隻有 17.55 %。
為什麼成功率低?首先,我的數據集中確實有很多棘手的圖像。其次,我們不應該忘記,作為人類,我們有著兩百萬年的進化背景來幫助理解什麼是什麼。
雖然許多人認為我們已經掌握了科技領域的人臉檢測,但仍有改進的餘地!
對速度的需求
雖然亞馬遜能夠檢測到最多的人臉,但穀歌和微軟的處理速度明顯快於其他公司。然而平均來說,他們仍然需要超過一秒鍾的時間來處理我們數據集上的單個圖像。
將圖像數據從我們的計算機/服務器發送到另一台服務器肯定也會影響性能。
注意:我們將在本係列的下一部分中了解(本地)開源庫是否可以更快地完成同樣的工作。
(相對)小臉的人群
在分析了這些圖像後,亞馬遜似乎非常擅長檢測人群中的人臉,以及相對較小的臉部。
小摘錄
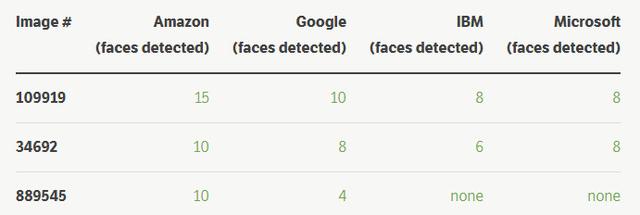
亞馬遜的示例圖像 # 889545

亞馬遜能夠在這張圖片中檢測到 10 張麵孔,而穀歌隻發現了 4 張,IBM 檢測到 0 張以及微軟檢測到 0 張。
不同的角度,不完整的臉
那麼,這是否意味著 IBM 根本不如他競爭對手好呢?一點也不。雖然亞馬遜可能擅長於在集體照片中檢測小臉,但 IBM 還有另一個優勢:困難的圖像。這是什麼意思呢?好吧,指的是頭部處於不尋常角度或者可能沒有完全顯示的臉部圖像。
以下是我們數據集的三個例子,IBM 是唯一一家檢測到其中人臉的供應商。
IBM 的示例圖像 # 356147

僅由 IBM 檢測到麵部的圖像。
......
想要繼續閱讀,請移步至我們的AI研習社社區:http://www.gair.link/page/TextTranslation/884




















