
時間:2018-06-26 來源:互聯網 瀏覽量:
編者按:微軟技術院士、圖靈獎得主Jim Gray提出了科研的第四範式——數據科學在科學研究中的普遍性。隨著大數據時代的到來,除了計算機科學領域,其它跨學科與跨領域的研究也同樣對高質量的數據集存在大量需求。為此,微軟研究院發布了開放數據項目,並對外開放了部分內部研究數據集,希望促進全球學術界和產業界的廣泛合作。本文翻譯自微軟研究院博客“Announcing Microsoft Research Open Data –Datasets by Microsoft Research now available in the cloud”,有刪減。
近期,微軟對外發布了微軟研究院開放數據項目(Microsoft Research Open Data),這套新的雲數據資料庫囊括了微軟多年以來在已發表的研究中所使用的數據管理和研究成果。
我們的目標是為研究人員與合作者提供一個簡單便捷的平台,來共享數據集和相關研究技術與工具。微軟研究院開放數據項目旨在簡化對這些數據集的訪問流程,促進使用雲資源的研究人員之間的協作,實現研究資源的可複用性。
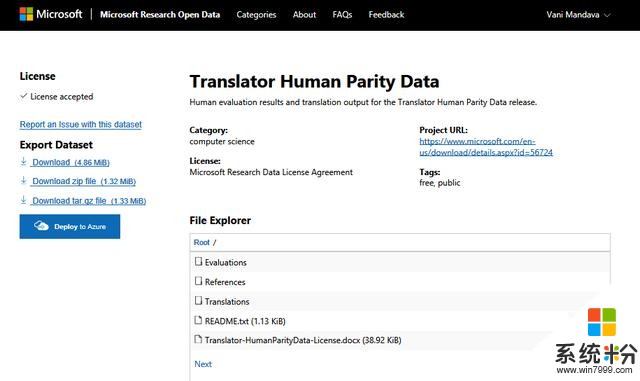
微軟研究院開放數據項目中的數據集
隨著全球數據總量的指數級增長,人們普遍認為在2025年數據總量就將超150ZB。人們已經認識到應該優先處理數據,而不是依賴緩慢增長的互聯網帶寬遷移數據。因此我們相信,開放數據集將為學術界和產業界帶來巨大的應用價值。
麻省理工學院教授Sam Madden表示“微軟開放數據項目將改變大數據時代的遊戲規則,能夠大大減少數據共享的障礙,借助雲計算的力量促進研究資源的可複用性。”
開放了哪些數據集?
微軟研究院開放數據項目中的數據集根據研究領域進行分類,涵蓋計算機科學、社會科學、物理學、天文學、生物學、經濟學等等多個學科領域,如下圖所示。
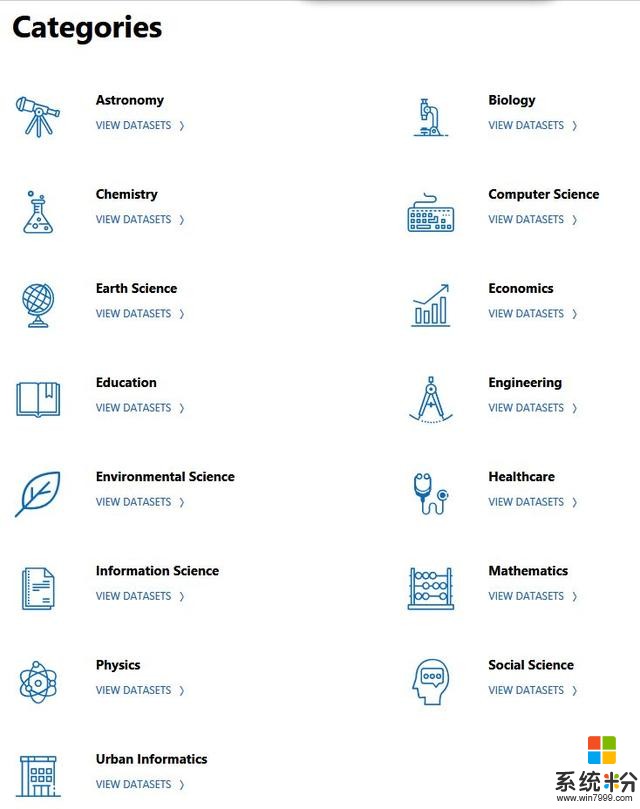
數據集中的分類
微軟研究院開放數據項目盡可能達到了數據共享的最高標準,以確保數據集可發現性、可訪問性、互操作性和可複用性,且整套數據資料庫不包含任何個人身份信息。
目前該項目包含了數十個已開放的數據集,我們為大家介紹其中的幾個精選數據集:
微軟機器閱讀理解(MS MARCO)
微軟機器閱讀理解(MS MARCO)是一個全新的用於閱讀理解和問題解答的大型數據集。在MS MARCO中,所有問題都來自於真正匿名用戶的搜索查詢。用於推斷回答的上下文語境則來自於必應搜索引擎抓取的真實Web文檔。回答則由人工生成。
文件大小:469.03 MB
文件類型:json
許可協議:微軟研究院數據許可協議
詳細信息:
https://msropendata.com/datasets/2bda14a7-ee25-4092-8f2f-9272d48ae903
微軟研究院社交媒體對話語料庫
該數據集集合了從Twitter日誌中提取的代表4,232個三步會話片段的12,696個Tweet ID。數據集中的每一行表示一個單獨的上下文-消息-響應三元組,眾包注釋者在李克特量表上為上下文響應質量的評分平均為4或更高。數據已被隨機分為開發數據集和測試數據集,分別包含2118和2114個三元組。該數據集僅在自然語言處理社區供學術研究之用。為了訪問底層推文和相關元數據,需要調用Twitter API。
如果在研究中使用該數據集,請在文中引用以下文章:
Alessandro Sordoni, Michel Galley, Michael Auli, Chris Brockett, Yangfeng Ji, Meg Mitchell, Jian-Yun Nie, Jianfeng Gao, and Bill Dolan, A Neural Network Approach to Context-Sensitive Generation of Conversational Responses, Conference of the North American Chapter of the Association for Computational Linguistics – Human Language Technologies (NAACL-HLT 2015), June 2015.
文件大小:245.46 KB
文件類型:txt
SigmaDolphin
SigmaDolphin是2013年初在微軟亞洲研究院啟動的一個項目,其主要目標是建立一個具有自然語言理解和推理能力的計算機智能係統,專注於自動解題的應用,即自動解決用自然語言編寫的問題(特別是數學問題)。
文件大小:11.54 MB
文件類型:json、pdf、pkl、py、txt
許可協議:微軟研究院數據許可協議
詳細信息:
https://msropendata.com/datasets/f0e63bb3-717a-4a53-aa79-da339b0d7992
如何獲取和使用開放數據集?
現在可以訪問microsoftopendata.com瀏覽和下載可用的數據集,或者通過自動工作流將它們直接通過Azure訂閱複製到基於Azure的Data Science虛擬機上,如下圖所示。
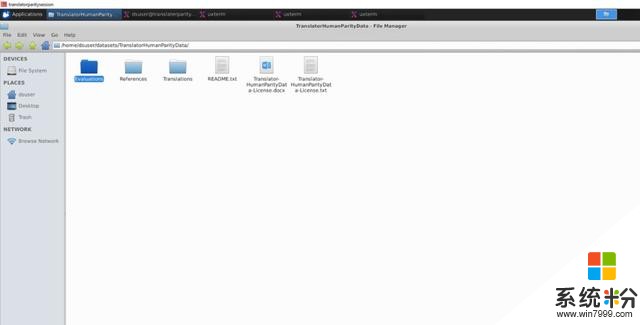
數據集可直接複製到基於Azure的Linux虛擬機上
Data Science虛擬機已經預裝了許多廣受研究人員與開發者歡迎的開發工具,如下圖所示。
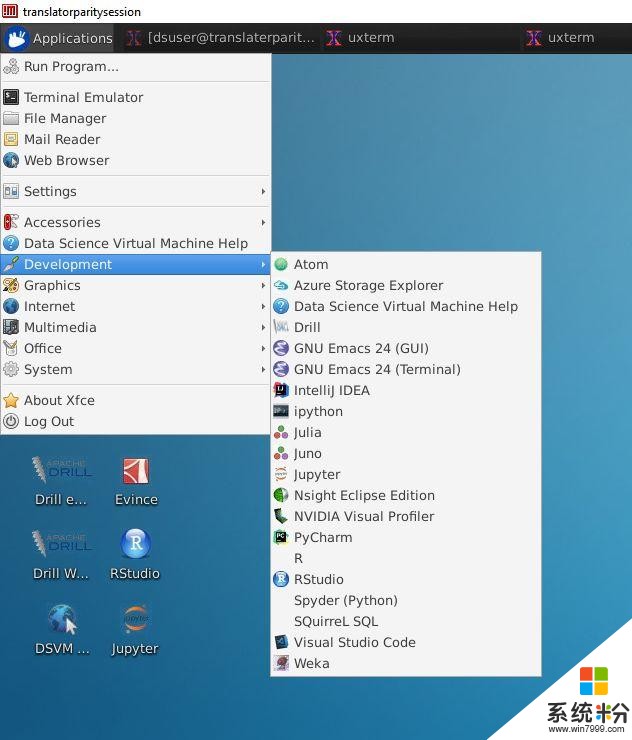
Linux Data Science虛擬機
微軟研究院開放數據項目是微軟各個團隊、研究人員、行業合作夥伴以及學術顧問的合作成果。在未來,我們還將根據社區的反饋意見繼續完善和發展這套雲數據資料庫。
點擊閱讀原文,了解項目更多詳情。
你也許還想看:
,共建交流平台。來稿請寄:msraai@microsoft.com。




















