
時間:2017-04-27 來源:互聯網 瀏覽量:
機器之心編譯
參與:吳攀
生成對抗網絡(GAN)與神經機器翻譯(NMT)是當前人工智能研究的兩個熱門領域。近日,中國科學技術大學與微軟亞洲研究院的研究者提出了一種新的框架 Adversarial-NMT,將這兩者結合到了一起。機器之心對該研究的論文進行了摘要介紹,論文原文可點擊文末「閱讀原文」查閱。

摘要
在本論文中,我們研究了一種新的神經機器翻譯(NMT)的學習範式。我們沒有像之前的研究一樣最大化人類翻譯的似然(likelihood),我們是最小化人類翻譯與 NMT 模型的翻譯之間的差異。為了實現這個目標,受生成對抗網絡(GAN)近來成功的啟發,我們實現了一種對抗訓練架構並將其命名為 Adversarial-NMT。在 Adversarial-NMT 中,NMT 模型的訓練會得到一個對手的協助,這是一個精心設計的卷積神經網絡(CNN)。這個對手的目標是找到該 NMT 模型所生成的翻譯結果與人類翻譯結果之間的區別。該 NMT 模型的目標是生成高質量的能夠欺騙其對手的翻譯。我們還采用了一種策略梯度方法來聯合訓練該 NMT 模型及其對手。在英法翻譯和德英翻譯任務上的實驗結果表明 Adversarial-NMT 可以實現比幾種強基準顯著更好的翻譯質量。
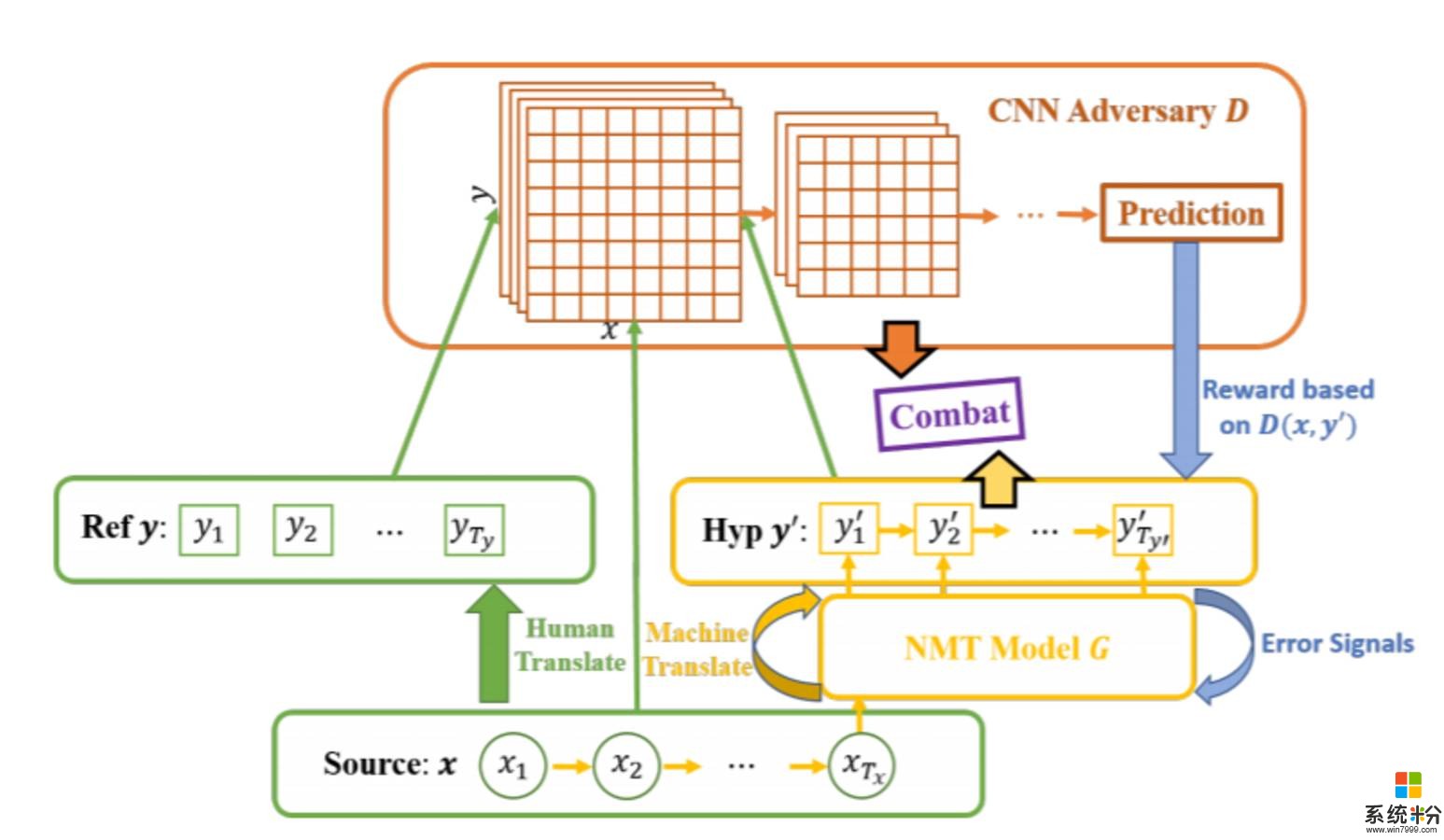
圖 1:Adversarial-NMT 框架。Ref 是 Reference 的縮寫,表示 ground-truth 翻譯。Hyp 是 Hypothesis 的縮寫,表示模型翻譯的句子。所以的黃色部分表示 NMT 模型 G,其將源句子 x 映射成翻譯句子。紅色部分是對手網絡 D,其預測給定的目標句子是否為給定源句子 x 的 ground-truth 翻譯。G 和 D 互相戰鬥,通過策略梯度生成采樣過的翻譯 y' 來訓練 D,生成獎勵信號來訓練 G。
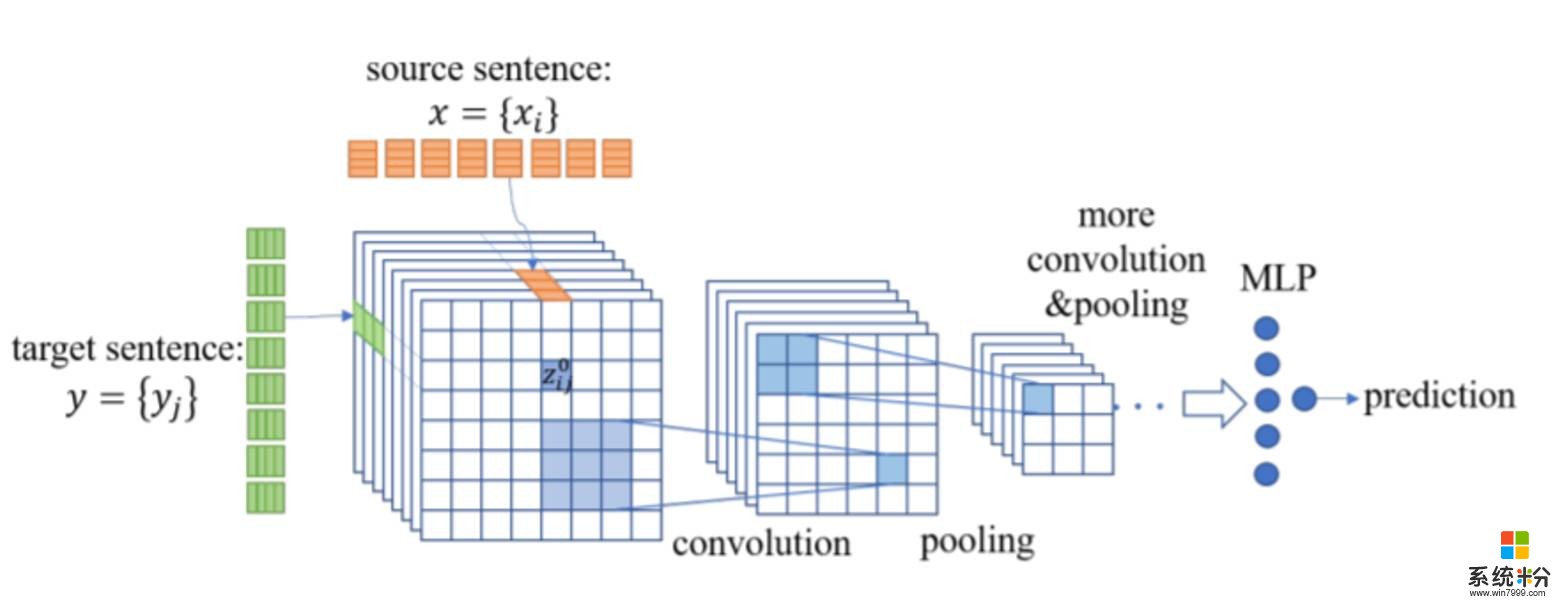
圖 2:CNN 對手網絡的框架
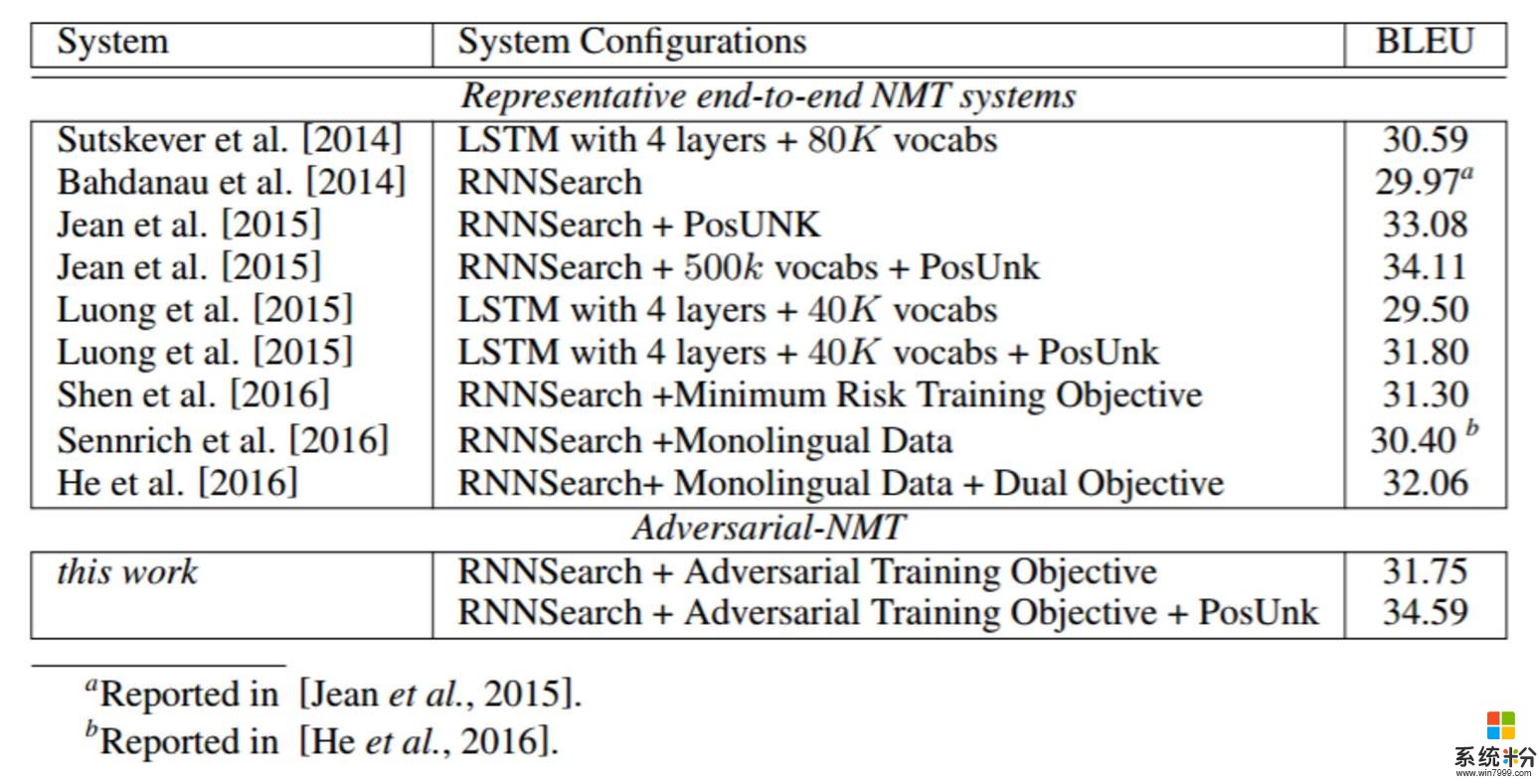
表 1:在英法翻譯上不同 NMT 係統的表現。其默認設置是一個單層的 GRU + 30k 詞彙+ MLE 訓練目標,使用的是 no monolingual data 進行訓練,即 Bahdanau et al. [2014] 提出的 RNNSearch 模型

表 2:在德英翻譯上不同 NMT 係統的表現。其默認設置是一個單層的 GRU 編碼器-解碼器模型+ MLE 訓練目標,即 Bahdanau et al. [2014] 提出的 RNNSearch 模型
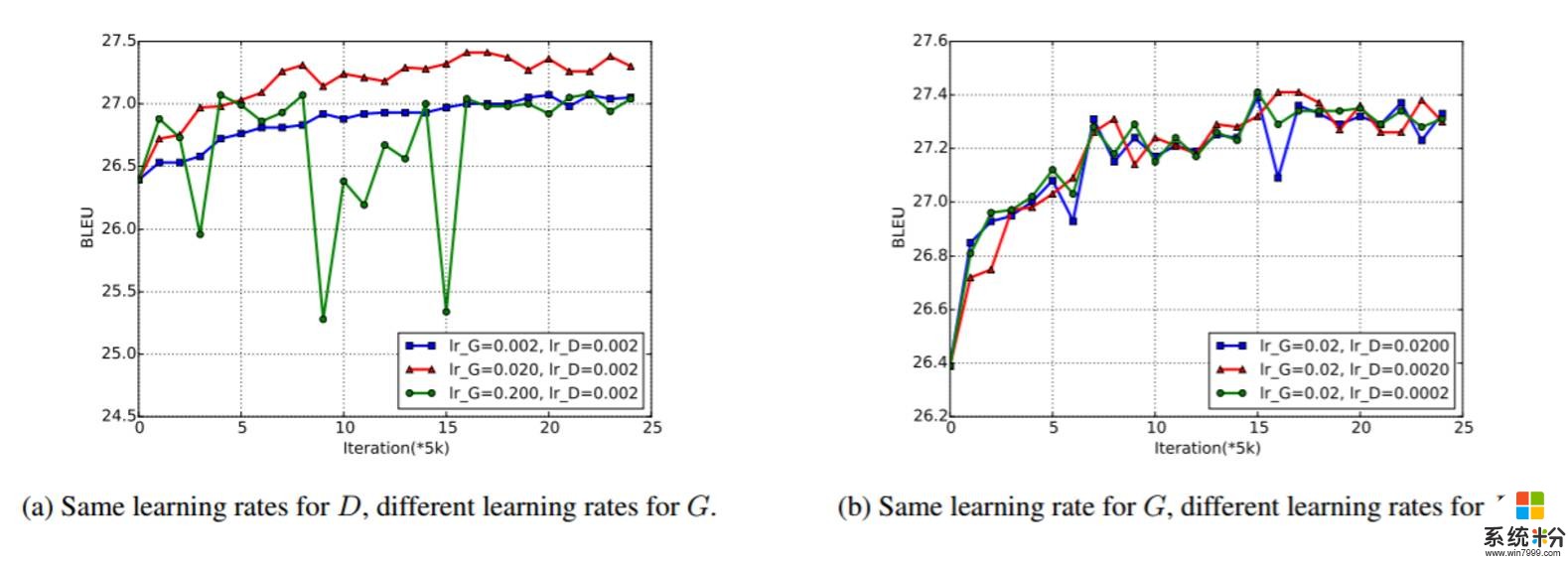
圖 3:在英法 Adversarial-NMT 訓練過程中的 Dev set BLEU。圖 3(a) 中 D 使用了一樣的學習率,G 使用了不同的學習率。圖 3(b) 中 G 使用了一樣的學習率,而 D 則使用了不同的學習率。





















