
時間:2018-03-27 來源:互聯網 瀏覽量:

*本文經AI新媒體量子位(公眾號 ID: QbitAI)授權轉載,轉載請聯係出處。
這可能不在大多數人的意料之中。
在著名的微軟MSMARCO(Microsoft MAchine Reading COmprehension)機器閱讀理解測試排行上,現在排名第一的團隊,已經悄然變成了猿輔導。
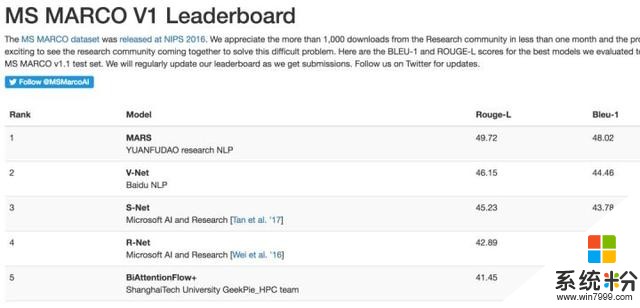
這意味著,一家提供中小學在線輔導的創業公司,在這場機器閱讀理解實力比拚中,戰勝了百度、微軟這兩個強勁的對手。
不止於此,猿輔導這個AI係統的表現,也超過了人類水平。
這是MSMARCO排行榜上首次出現的情況。猿輔導團隊的兩項測試得分為:49.72、48.02。而人類基準為47、46。
什麼是超過人類水平?猿輔導給了一個解釋:
MSMARCO數據集包含微軟BING搜索的query以及query對應的top 10的搜索結果。超過人類的意思就是說,給定query和top 10搜索結果,機器找出的答案比普通人找的更準。
 MSMARCO官方發來賀電
MSMARCO官方發來賀電實際上,MARCO是微軟基於搜索引擎BING構建的大規模英文閱讀理解數據集,包含10萬個問題和20萬篇不重複的文檔。
MARCO數據集中的問題全部來自於BING的搜索日誌,根據用戶在BING中輸入的真實問題模擬搜索引擎中的真實應用場景,是該領域最有應用價值的數據集之一。
此前百度提供的信息稱,在機器閱讀理解領域,研究者多參與由斯坦福大學發起的SQuAD挑戰賽。但相比SQuAD,MARCO的挑戰難度更大,因為它需要測試者提交的模型具備理解複雜文檔、回答複雜問題的能力。
今年2月,百度NLP團隊在這個排行榜登頂時,得分為46.15、44.46。百度之前憑借的是V-NET單一模型。
而這次猿輔導使用的一個名為MARS(Multi-Attention ReaderS)的模型。這個模型采用層疊式的注意力機製,在多候選文檔采樣出多個候選答案區域,並在此基礎上使用交叉投票模型,優化最終的答案。
這套係統來自猿輔導的NLP團隊,主要成員包括柳景明、趙薇等人。
不瞞你們說,量子位當時就腦補了一句話:“趙薇團隊擊敗了百度”。
不要當真、不要當真。據了解,這個趙薇是一位真漢子,加入猿題庫前曾經供職過微軟,就是那個AI黃埔軍校一般的微軟。
其實,猿輔導在NLP領域的成績,不止這一件。更早一些時候,量子位還在arXiv上看到過一篇來自猿輔導的論文。這篇論文的作者是猿輔導NLP團隊的王亮。
題目很直白:
Yuanfudao at SemEval-2018 Task 11: Three-way Attention and Relational Knowledge for Commonsense Machine Comprehension.
簡單來說就是,猿輔導的NLP團隊在SemEval-2018(國際語義評測)的一個任務上,獲得了一個第二名的成績。
這個任務名為Machine Comprehension using Commonsense Knowledge,意為:使用常識的機器閱讀理解。
這個任務排名第一的是哈工大訊飛聯合實驗室團隊。

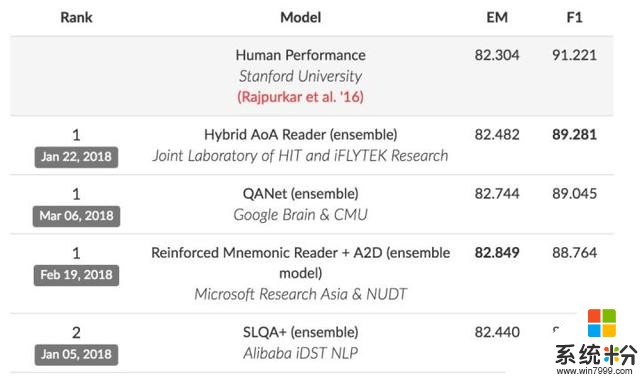
在另一個著名的機器閱讀理解排行榜SQuAD上,目前猿輔導NLP團隊的成績排在第六名。
目前SQuAD有三個並列第一,除了哈工大訊飛聯合實驗室團隊、微軟亞洲研究院和國防科大聯合團隊之外,還有一個新麵孔擠了進來:Google Brain和CMU聯合團隊。
看來,NLP領域的爭奪會更激烈、更好玩了。
最後,量子位聯係上了猿輔導,官方給出一些正式的回應。我們也列在下麵,供參考。
1、猿輔導為什麼要做機器閱讀理解
從公司組建起,我們就有自己的應用研究部,AI做為教育未來應用的底層技術,我們公司也在著重打造自己在這方麵的能力,包括猿輔導在線課程在內的公司各項業務,也都享受著AI技術帶來的推動和變革。
機器閱讀理解、語音識別、手寫識別、圖像識別等技術,分別被應用在了猿輔導的在線輔導課程,小猿搜題、小猿口算、斑馬英語等等產品中,諸如小猿搜題的搜題功能,英文作文的手寫識別及打分,小猿口算的拍照批改,斑馬英語的繪本朗讀打分等等。
機器閱讀理解隻是這個團隊眾多AI技術方向中的一支,公司一直在技術層麵上做更多的嚐試,這次取得第一也是階段性的成果之一
2、研發團隊的成員組成
猿輔導應用研究團隊成立於2014年年中,一直從事深度學習在教育領域的應用和研究工作。團隊成員均畢業於北京大學、清華大學、上海交大、中科院、香港大學等知名高校,大多數擁有碩士或博士學位。
研究方向涵蓋了圖像識別,語音識別、自然語言理解、數據挖掘、深度學習等領域。團隊成功運用深度學習技術,從零開始打造了活躍用戶過億的拍照搜題APP——小猿搜題,開源了分布式機器學習係統ytk-learn和分布式通信係統ytk-mp4j。
3、此次提交給微軟的模型是怎樣的?為何會超過百度?
此次我們提交的MARS(Multi-Attention ReaderS)模型,采用層疊式的注意力機製在多候選文檔采樣出多個候選答案區域,並在此基礎上使用交叉投票模型,優化最終的答案。
在可評測的指標上,猿輔導此次上傳的MARS是MSMarco的數據集上首次超過人類的模型,並且大幅超過第二名百度。根據團隊介紹,這個數據集包含微軟bing搜索的query以及query對應的top 10的搜索結果,超過人類的意思就是說,給定query和top 10搜索結果,機器找出的答案比普通人找的更準。
【關於超過人類數據,微軟方麵給出的說法是:Can your model read, comprehend, and answer questions better than humans? The below is current human performance on the MS MARCO task (which we will improve in future versions). This was ascertained by having two judges answer the same question and measuring our metrics over their responses.】
另外,我們的模型在semEval(國際語義評測)上的閱讀理解task上,獲得了第二名。此前曾在SQUAD數據集上,單模型第三。
本文轉自量子位,作者允中。




















