
時間:2017-04-24 來源:互聯網 瀏覽量:

前不久,微軟人工智能及微軟研究事業部技術院士、微軟首席語音科學家黃學東博士,作為清華大學的校友在母校舉辦了一場講座,為大家回顧了微軟在人工智能領域的最新成就,並詳細解釋了微軟是如何使用微軟認知工具包CNTK在語音識別和機器翻譯研究中取得最新進展的。
想知道微軟語音識別技術達到人類專業水平背後的驚天大秘密麼?快來一起聽聽黃學東博士的分享。
今天我想給大家分享一下微軟在人工智能領域取得的一些最新突破,也分享一下我們在20多年的曆程中,是怎樣持之以恒取得這些突破的。
先看看今年《經濟學人雜誌》的封麵故事——我們終於可以和機器講話了。裏麵有一個很有名的圖表總結了整個領域從1954年IBM科學家第一次進行機器翻譯的探索,到2016年微軟第一次在會話語音識別上達到人類水平的曆史性突破。
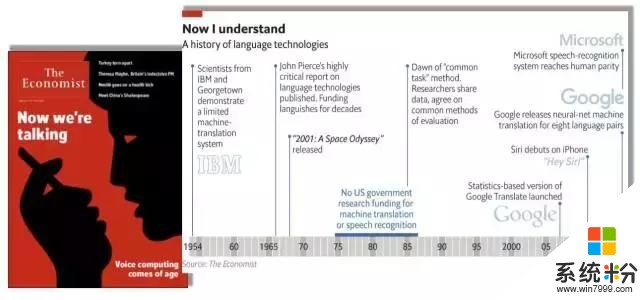
在幾十年的曆程中,有非常多優秀的公司在語音和語言領域進行了不懈地探索,終於在今天,達到了和人一樣精準的語音識別,這是非常了不起的曆史性突破。
1982年我在清華做碩士論文時,做的就是語音識別。碩士畢業讀博士時,我在計算機係方棣棠先生的帶領下,繼續做這方麵的研究。很難想象在我的有生之年,我們能讓計算機語音識別可以達到如此精準的水平。所以想跟大家分享一下,我們是怎樣追求這個夢想,持之以恒,通過不懈的努力達到曆史性突破的。
近兩年人工智能受到熱議,其實人工智能包括了兩個主要的類別以及三個主要的因素:
第一,平台。比如我要到清華演講,一定會有個場地,有一個舞台,而這個舞台就相當於計算。今天的計算通過英特爾、英偉達等公司的不懈努力和1982年我們在蘋果、IBM PC/XT上麵做的語音識別是有天壤之別的。當時我們在IBM PC/XT上用了德州儀器公司的TMS320,我還用彙編語言在上麵寫了第一個開發程序。如今,要做先進的語音識別訓練也需要GPU,這和當年的TMS320有異曲同工之妙。這是第一,要有一個平台。
第二,數據。我在這裏講話要有氧氣。人工智能和語音識別也是一樣的,要有大數據才能把算法做得精準。
第三,算法。算法很重要,要有內容。
這三點,缺一不可。
再來人工智能包括感知和認知這兩大塊。可以毫無疑問地說,在感知這個領域,人工智能已經幾乎達到人類同樣的水平,但這當然是在特定任務的情況下。在認知領域,包括自然語音理解、推理、知識學習等,我覺得還差的很遠。所以大家在說人工智能達到了前所未有的高度時,一定要搞清楚,說的是在認知領域還是在感知領域。
下麵讓我們來看看微軟在人工智能領域所取得的一些成果。首先,微軟有二十多年的積累,微軟研究院在建院時的第一個願景就是希望讓計算機能聽、能看、能說、能夠學習。這和現在人工智能所發展的方向以及能做到的工作基本上是一模一樣。
2015年,微軟亞洲研究院率先在計算機視覺領域有了很大的突破。研究員們在當年的ImageNet圖像識別挑戰賽中使用了神經網絡有152層的深度學習,這是非常了不起的突破。而去年微軟在語音識別的Switchboard上再次取得重大突破,使得計算機的語音識別能力超過世界上絕大多數人,與人類專業高手持平。
語言是人類特有的交流工具。今天,計算機可以在假定有足夠計算資源的情況下,非常準確地識別你和我講的每一個字,這是一個非常大的曆史性突破,也是人工智能在感知上的一個重大裏程碑。
所以,我想簡單回顧一下語音識別的發展曆程。幾年前我和James Baker,Raj Reddy合寫了一篇文章。Raj Reddy是圖靈獎得主,James Baker是第一個用馬爾可夫模型做語音識別的人,當年創建了Dragon公司並一直擔任CEO,我最年輕。所以文章可以說表達了我們三代人在語音領域過去40年裏的一些追求。雖然文章發表在兩年前,但現在看裏麵講的很多東西已經過時了,因此可以看出這個領域的進展有多麼神速。

再看看Switchboard,這是整個工業界常用的一個測試數據集。很多新的領域或新的方法錯誤率基本都在20%左右徘徊。大規模標杆性的進展是IBM Watson,他們的錯誤率在5%到6%之間,而人的水平基本上也在5%到6%之間。過去20年,在這個標杆的數據集上,有很多公司都在不懈努力,如今的成果其實並不是一家公司所做的工作,而是整個業界一起努力的結果。
各種各樣的神經網絡學習方法其實都大同小異,基本上是通過梯度下降法(Gradient Descent)找到最佳的參數,通過深度學習表達出最優的模型,以及大量的GPU、足夠的計算資源來調整參數。所以神經網絡對計算機語音識別的貢獻不可低估。早在90年代初期就有很多語音識別的研究是利用神經網絡在做,但效果並不好。因為,第一,數據資源不夠多;第二,訓練層數少。而由於沒有計算資源、數據有限,所以神經網絡一直被隱馬爾可夫模型(Hidden Markov Model)壓製著,無法翻身。
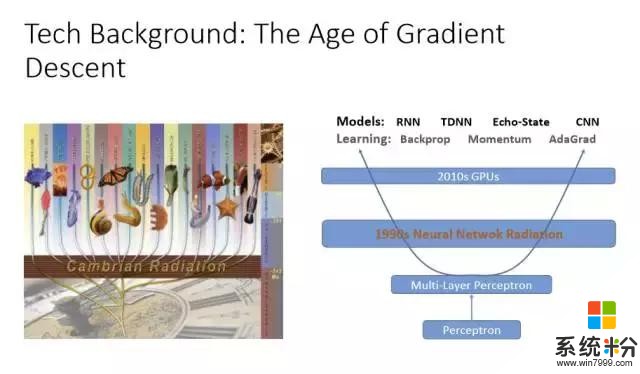
深度學習翻身的最主要原因就是層數的增加,並且和隱馬爾可夫模型結合。在這方麵微軟研究院也走在業界的前端。深度學習還有一個特別好的方法,就是特別適合把不同的特征整合起來,就是特征融合(Feature Fusion)。
如果在噪音很高的情況下可以把特征參數增強,再加上與環境噪音有關的東西,通過深度學習就可以學出很好的結果。如果是遠長的語音識別,有很多不同的回音,那也沒關係,把回音作為特征可以增強特征。如果要訓練一個模型來識別所有人的語音,那也沒有關係,可以加上與說話人有關的特征。所以神經網絡厲害的地方在於,不需要懂具體是怎麼回事,隻要有足夠的計算資源、數據,都能學出來。
我們的神經網絡係統目前有好幾種不同的類型,最常見的是借用計算機視覺CNN(Convolution Neural Net,卷積神經網絡)可以把不同變化位置的東西變得更加魯棒。你可以把計算機視覺整套方法用到語音上,把語音看成圖像,頻譜從時間和頻率走,通過CNN你可以做得非常優秀。另外一個是RNN(Recurrent Neural Networks,遞歸神經網絡),它可以為時間變化特征建模,也就是說你可以將隱藏層反饋回來做為輸入送回去。這兩種神經網絡的模型結合起來,造就了微軟曆史性的突破。
微軟語音識別的總結基本上可以用下圖來表示。
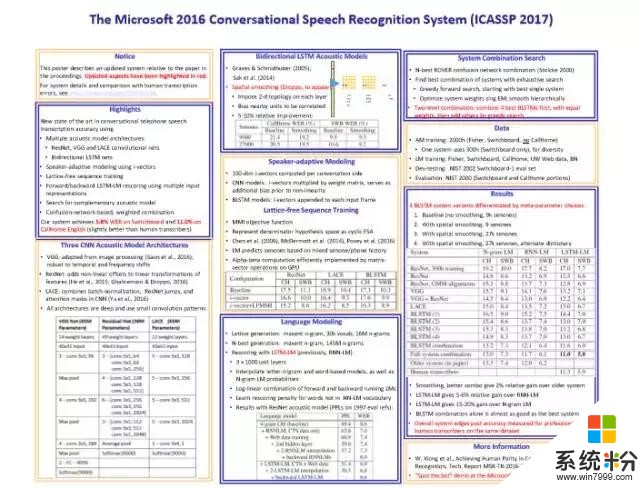
這是2017年ICASSP剛剛發表的一篇文章。我先給大家簡單介紹一下。
第一,Switchboard和人類比較的時候,很多人做過不同的實驗。1997年Lippman就做了大量的實驗,人的錯誤率大約在4%左右,當時的語音識別係統錯誤率在80%左右,從80%到4%這是遙不可及的,那時是90年代中期。
當然,測試數據也在不斷變化,後來微軟把測試數據送給人工標注專家進行測試,但並不告訴他們這是要測的,而是把這些數據當成是普通數據標注的一部分。我們得到的人工標注專家的錯誤率是5.9%。後來IBM又請澳大利亞最優秀的專家反複聽,用4個團隊標注,它的錯誤率在5.1%左右。我相信如果讓我們這些普通大眾來標注,錯誤率都將超過6%。
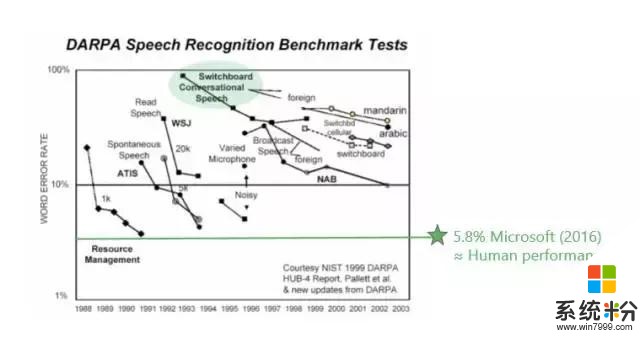
上圖是業界在過去幾十年裏麵錯誤率下降的指標,可以看到5.8%是微軟在去年達到的水平。Switchboard的錯誤率從80%左右一直到5.8%左右,是用了什麼方法呢?我們是怎麼達到這個目標呢?

大家知道語音識別有兩個主要的部分,一個是語音模型,一個是語言模型。
語音模型我們基本上用了6個不同的神經網絡,並行的同時識別。很有效的一個方法是微軟亞洲研究院在計算機視覺方麵發明的ResNet(殘差網絡),它是CNN的一個變種。當然,我們也用了RNN。可以看出,這6個不同的神經網絡在並行工作,隨後我們再把它們有機地結合起來。在此基礎之上再用4個神經網絡做語言模型,然後重新整合。所以基本上是10個神經網絡在同時工作,這就造就了我們曆史性的突破。
下麵給大家分享一下微軟在人工智能方麵的一些研究和開發總覽。
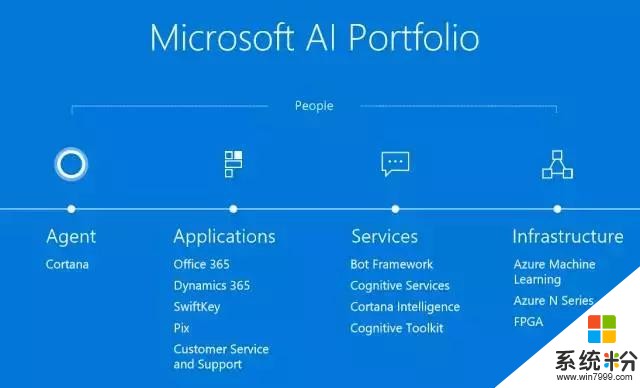
微軟在人工智能方麵有四個重要的技術。(1)計算非常重要,以Azure為代表,我們在基礎架構上有很高的投入;(2)Service方麵,我們提供了很多如微軟認知服務、微軟認知工具包等服務和工具,大家可以使用它們創造各自的人工智能應用;(3)我們的應用都會利用微軟的認知服務來增強它們的智能特質;(4)我們認為人工智能最有標誌性的是對話,所以在對話裏我們有幾個具有代表性的Agent。
剛才提到的微軟認知服務,它包括了20多個人工智能領域的API,我們將其打包,以雲服務的方式提供。如果你是一個開發人員,那麼你不需要掌握人工智能、計算機視覺、機器翻譯等等的技術知識,隻需調用API就可以了。通過這種形式,微軟為廣大的應用開發人員提供了一個良好的服務。
而源自於中國團隊的微軟小冰,其語音合成基本上達到了非常高的水平。小冰的自然度、情緒表達能力已經很接近人類水平了,比業界其他的合成係統有一個很大的提高,這也是得益於深度學習。
另外,微軟的研究使得語音識別在Switchboard達到了很高的水平,但是跨領域的語音識別performance還是一個問題,所以微軟提供了一個可以量身定製的語音識別係統。微軟的自定義語音服務(Custom Speech Service)在每個人的應用場景裏都可以完全量身定製語音識別係統。這是微軟把人工智能普及化的最好案例之一。
接下來,講講我們團隊在機器翻譯裏的進步。微軟機器翻譯其實做了很長時間,目前機器翻譯我們可以同時支持100個講不用語言的人使用。如果我的演講PPT是英文,我要把它翻譯成英、法、日、德等,隻要用手機下載了Microsoft Translator應用,照一張相就可以翻譯成你需要的語言。Microsoft Translator可以支持60種語言的翻譯,所以當到任何地方去,隻要用Microsoft Translator,就可以消除所有的語言障礙。
Microsoft Translator的現場翻譯功能是一個非常有意義的使用案例,也是用深度學習來達到一個非常高性能指標的成功案例。它用的神經網絡語言模型是聯合模型,不僅僅是原語言、目標語言的dependency都可以用神經網絡來訓練,它用的語言模型也是LSTM。以前統計機器翻譯的運作方法和語音係統非常類似。現在最新的神經網絡機器翻譯,其實非常簡單,它就是有一套輸入係統,用的是LSTM,有一套輸出係統用的也是LSTM,LSTM輸入係統有一個最後的狀態,這個狀態通過一些加權,可以通過解碼器的方法產生輸出的語言句子,基本的架構就是這樣。
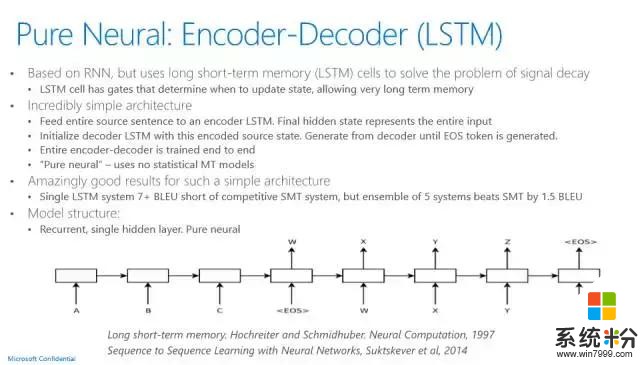
和傳統的機器翻譯相比,神經網絡機器翻譯像語音識別一樣,有了一個大幅度的提高,漲了四個點。做機器翻譯研究的應該都知道,這是一個很了不起的曆史性的進步。目前,語音識別在有計算資源的情況下可以達到人的水平,我相信,機器翻譯也指日可待。
盡管我們語音識別達到了曆史性的水平,但是語音理解還有很長的路要走。微軟在智能客服方麵做了很多工作,現在微軟產品的客服上已經使用了有深度學習的人工智能,這個功能目前已在微軟美國上線了。
如果,用戶有關於微軟產品線的問題需要相關的支持,這時就是微軟人工智能在幫忙回答問題。這裏涉及的是有深度的,也很有挑戰性的客服問題,是需要有深度訓練的人工智能。比如,問-怎麼樣才能升級Windows?人工智能回答-你現在的Windows是什麼樣的產品?用戶-XP。然後它會給你具體的建議,如果不滿意,那麼可以點擊一個鏈接,這時候就有真實的客服人員幫你解決問題。智能客服的經濟效益是極大的。
微軟用最先進的人工智能幫用戶解決問題,而這也是微軟的人工智能和其他人工智能最不同的地方,理念的不同,產品思路的不同。
剛剛講了好幾個案例,從語音識別到語音合成到智能客服,他們都得益於深度學習的進步。其實我們最大得益於的是微軟有一個自己開源的認知工具包,叫Computational Network Toolkit(CNTK)。它為我們提供了強大的計算力量。有人會問,強大到什麼地步?大家都知道穀歌有一個TensorFlow,它非常流行,大家談到深度學習一定會覺得TensorFlow很強大。此前英偉達做了一個評測,這個評測是圖型越高越好。黃色是穀歌的TensorFlow,藍色是微軟的CNTK,可以看出不僅僅是一個GPU、兩個GPU、四個GPU、八個GPU,微軟是全線超越最流行的深度學習工具包。
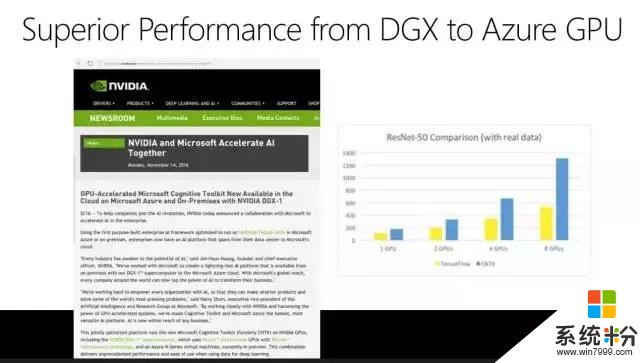
ComputerWorld在2017年2月份做了一個評測,它說微軟CNTK的性能是10,TensorFlow也是10。它把幾個不同的深度學習工具包做了一個打分,我們是第二名,你如果要關注速度的話,CNTK是非常優秀的。這也是微軟的語音識別係統為什麼能做到曆史性的突破,我們做了非常多的實驗,如果沒有CNTK這樣高速的工具包很難想象我們可以取得今天的成績。
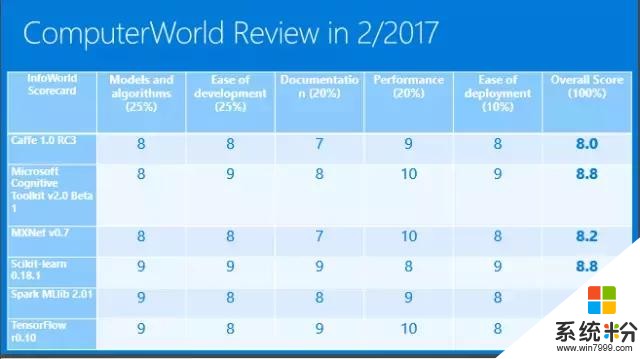
最後一點要講,微軟Azure計算平台不僅僅有GPU還有FPGA,FPGA對實時運算速度的提高也是很大的,這樣強大的計算機係統可以在雲上為我們提供強大的計算資源。
總結一下,這是整個微軟公司在人工智能領域所做的一些基本工作。從Azure到Cortana,到應用再到服務,我們想為大家提供一個非常強大的服務。我們的願景很明確,就是為大家提供人工智能的實惠,普及人工智能的開發和應用,這就是我的總結和我們今天能達到人類語音識別水平的背後故事,謝謝大家!
作者簡介
黃學東博士,微軟人工智能及微軟研究事業部技術院士,目前領導微軟在美國、中國、德國、以色列的全球團隊,負責研發微軟企業人工智能、微軟認知服務等最新人工智能產品和技術。作為微軟首席語音科學家,黃學東博士領導的語音和對話研究團隊在 2016 年取得了語音識別曆史性的裏程碑。
1993年加盟微軟之前,黃學東博士在卡內基-梅隆大學計算機學院工作。曾榮獲1992年艾倫紐厄爾研究卓越領導獎、1993年IEEE 最佳論文獎、2011年全美亞裔年度工程師獎。2016年Wired 雜誌評選他為全球創造未來商業的25位天才之一。
他在愛丁堡大學、清華大學、湖南大學分別獲得博士、碩士、學士學位。他還已獲IEEE和ACM院士等殊榮。




















