
時間:2018-01-22 來源:互聯網 瀏覽量:
如果在你麵前鋪開一張紙,讓你畫一隻鳥,黃色的身子、黑色的翅膀和短短的喙,你很有可能一開始先勾勒出鳥的輪廓,然後將鳥的身體塗滿黃色,再為翅膀塗上黑色,最後描繪那個短短的喙。可能為了更有意境,你會補上一根樹枝,讓鳥站在上麵。
現在,機器人也可以做到這些了。
微軟研究實驗室最新開發了一項人工智能技術,可以從類似字幕的文本描述中生成圖像,更關鍵的是,它被編程為尤其關注單個詞彙。該研究論文中注明,一項行業標準測試結果顯示,這種有意識地“聚焦”讓“這種技術”在圖像質量方麵比之前最先進的從文本到圖像的生成技術提升了將近三倍。

這種技術——研究人員簡單地將之稱為繪圖機器人(drawing bot)——可以生成各種各樣的圖像,從鄉村場景(例如正在吃草的牛)到百無聊賴的內容(例如漂浮在湖麵上的雙層巴士客車)。每一幅圖像中都包含了一些文字描述中沒有的細節,意味著,這種人工智能包含了一種人造的想象力。
微軟研究院首席研究員何曉東說,“如果你用Bing搜索‘鳥’這個關鍵字,你會得到一張鳥的圖片。但是在這裏,這張圖片是由計算機創造的,一個又一個像素重新創造而成。” 而且,“這些鳥可能並不存在於現實世界——它們隻是我們的計算機對鳥的想象。”
這個繪圖機器人完成了圍繞計算機視覺和自然語言處理交叉部分的研究循環,何曉東和他的同事在過去五年中一直在這個領域內摸索。他們一開始研究的是一項能夠自動為照片編寫標題的技術——CaptionBot,然後轉向能夠回答人類關於圖像問題(例如語音對象的位置和屬性)的技術,這種技術對於盲人來說特別有用。

這些研究工作需要訓練機器學習模型來識別對象、解釋行為並用自然語言進行交談。
微軟研究院研究員Pengchuan Zhang補充表示,圖像生成是一項比圖像字幕更具挑戰性的任務, 因為這個過程需要繪圖機器人想象出標題中沒有包含的細節。“這意味著,你需要讓運行人工智能的機器學習算法想象出這個圖像中缺失的部分。”
會集中注意力的圖像生成
微軟繪畫機器人的核心是生成式對抗網絡(Generative Adversarial Network,或者稱為GAN)技術。該網絡包含了兩個機器學習模型,一個根據文字描述生成圖形;另一個則作為鑒別器(discriminator),使用文本描述來判斷所生成的圖像的真實性。這兩個模型組合既矛盾又融合,生成器試圖讓假的圖片通過鑒別器的鑒定,鑒定器決定了自己不被愚弄,兩者一起工作,鑒定器會推動生成器變得完美。
傳統生成式對抗網絡(GAN)在根據簡單文字(例如藍色的鳥或者常青樹)描述生成圖像方麵做得非常好,但是當文字描述變得更複雜的時候,例如綠色的頭、黃色的翅膀、紅色的肚皮的鳥,質量就會停滯不前。這是因為整個句子對於生成器來說是一個單一輸入,這些描述中的詳細信息丟失了,結果生成的圖像是一隻模模糊糊的、有點綠、有點黃也有點紅的鳥,而不是嚴格按照句子中的描述進行著色的鳥。但是,微軟的該項技術尤其擅長根據複雜的句子繪製圖像,而且,在標題的描述中沒有提到的具體細節方麵,機器人也可以填補這些空白。
這是因為,它有一點自己的常識和想象力,這要感謝它的訓練數據。在鳥的例子中,機器人畫的鳥通常是站在枝頭上的,即使是文本內容中並沒有提到這一細節也是如此,這是因為最初提供給它的圖像經常出現類似的內容。
微軟的繪圖機器人使用了標題和圖像匹配好了的數據集進行訓練,這讓這些模型能夠學會如何將文字內容和這些內容的可視化表達相匹配。例如,這個生成式對抗網絡(GAN)學會了在標題是鳥的時候生成一個鳥的圖像,而且也學到了鳥的圖像應該是什麼樣子。何曉東表示:“這是我們相信機器可以學習的根本原因。”
在人類畫畫的過程中,會反複查看下一步畫什麼,並且十分專注於正在描繪的這一部分內容當中。為了捕捉這一人類特質,微軟研究人員創建了他們稱之為注意力生成式對抗網絡或AttnGAN的技術,它從數學上代表了人類的注意的概念。它是通過將輸入的文本內容分解為單個的詞語,並將其同圖像中特定的區域進行匹配來完成這一任務的。
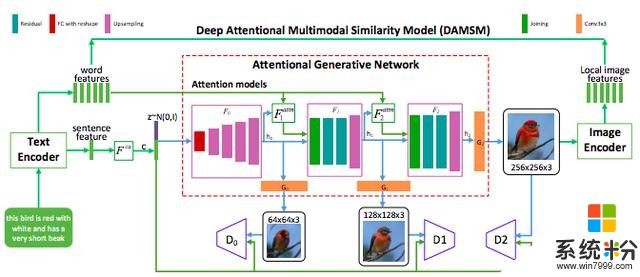
何曉東解釋說:“注意力是一個人類的概念;我們把注意力的問題變成了一個計算的問題。”
該模型還會從訓練數據中學習人類稱之為常識的東西,並且利用這些學到的概念來填補圖像中可供想象的空白部分。例如,由於訓練數據中的很多圖像裏的鳥都是站在枝頭之上的,所以除非文本內容另有詳細說明,AttnGAN通常畫出的鳥也都是站在枝頭之上的。
Pengchuan Zhang表示:“從數據來看,機器學習算法學到了鳥應該在哪裏這一常識。”作為難度測試,該團隊給這個繪圖機器人一些荒謬的題目,例如“漂浮在湖麵上的紅色雙層巴士。”結果它生成了一個模糊的、濕漉漉的圖像,既有點像一艘有雙層甲板的船,又有點像一輛雙層巴士,漂浮在群山環繞的湖麵上。這個圖像表明,該機器人內部產生了鬥爭,它知道船是漂浮在湖麵上的,而文本內容卻詳細指定了對象是一輛巴士車。
何曉東解釋說:“我們的描述可以天花亂墜,看看機器會如何反應。這台機器有一些背景知識的常識,但它仍然服從你的要求,盡管有時這些要求聽起來有點荒謬。”
當然,這不是第一項將藝術和人工智能結合在一起的技術案例。
這兩者的交叉有時會產生奇妙的結果。比如穀歌的人工智能繪製的這些夢幻般的圖像就有了自己的藝術展,穀歌還有一個神經網絡可以猜測你正在畫的是什麼,還有一個自動繪圖機器人等等。
Facebook也一直在教導神經網絡繪製一些小圖形,例如飛機、汽車和動物等,甚至從照片中創建自己的Bitmoji風格的化身形象。
英偉達的研究人員使用人工智能(A.I)創建了計算機生成的名人。
實際應用
從文本到圖像的生成技術可以找到很多實際應用,可以作為畫家和室內設計師的草圖助理,或者作為語音激活照片的細化工具。何曉東認為,如果有更多的計算能力,這項技術能夠根據電影劇本生成動畫電影,通過消除一些手工勞動來改善動畫電影製片人的工作。
然而目前來看,微軟的這項技術還不完善。如果你仔細檢查圖像就能找到瑕疵,例如鳥的喙是藍色的而不是黑色的,以及水果攤位上有突變的香蕉。這些缺陷清楚地表明,創造這幅畫的是電腦而不是人類。盡管如此,何曉東認為,這個AttnGAN生成的圖像的質量比之前最好的GAN生成的圖像質量提高了接近三倍,已經成為了通往類人類智能道路上的一個裏程碑,這些類人類智能能夠增強人類的能力。
何曉東進一步解釋說,“對於生活在同一個世界裏的人工智能和人類來說,他們必須有一種彼此交流的方式。而語言和視覺是人類和機器互相交流的兩種最重要的方式。”
【微軟研究院關於“繪圖機器人”論文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks獲取方式:關注科技行者公眾號(itechwalker),並打開對話界麵,回複關鍵字“微軟AI”,即可獲得下載地址】




















