
時間:2018-01-16 來源:互聯網 瀏覽量:
在由斯坦福大學發起的 SQuAD (Stanford Question Answering Dataset)文本閱讀理解挑戰賽中,來自阿裏巴巴和微軟團隊的人工智能模型分別以高分戰勝了人類選手,位列榜單的前兩位。

馬先生和比先生的團隊真是一次次打破人們對他們的認知。
閱讀理解戰勝人類,聽起來簡單,做起來還是很不容易的。要知道,這需要很強的自然語言處理能力和對語言詞句的理解能力。想想你高中閱讀理解考多少分就明白了,哈哈!
而 AI 在這方麵戰勝人類意味著什麼?意味著它們這種能力已經超過了人類閱讀理解界的大咖!
好,下麵說說這個測試是咋回事。在這場閱讀測試中,斯坦福大學的自然語言計算組會先從 500 多篇維基百科文章中抽取出大量的數據集(包含 10 萬個問題),然後將一篇幾百字(平均 100 字,最多 800 字)的文章給標注者閱讀,讓標注人員提出最多 5 個基於文章內容的問題並提供正確答案。
參賽者可以利用這個數據集進行模擬訓練,並且通過開放平台來提交自己的算法用於評分。

這個測試相當權威,被認為是當前世界監測機器閱讀水平的最權威測試之一。這是因為 SQuAD 能夠提供的龐大的數據規模,並能檢測出機器學習模型能否在處理大量信息後給出問題的準確答案。
看看比賽結果:來自阿裏巴巴 iDST 團隊的 SLQA+ 模型最終取得了 82.440 的成績,超越了人類的 82.304 分;而晚一天參與挑戰的微軟亞洲研究院自然語言計算組的 R-NET+ 模型,也在 EM 值(即 Exact Match)上取得了 82.650 的最高分。
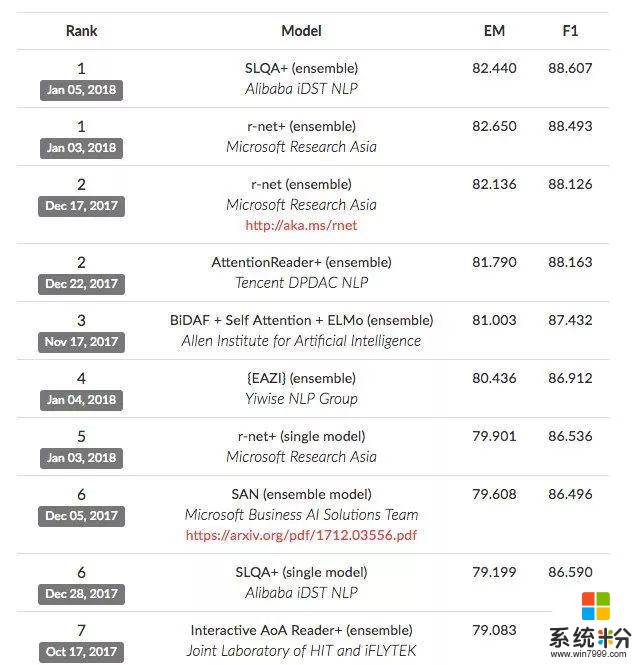
看看這個榜單,驚不驚喜!騰訊和科大訊飛也名列前茅。中國團隊相當厲害了。
AI 在回答客觀性問題上已經相當聰明了,可謂對答如流。這次,阿裏巴巴團隊在 AI 上建立了一種“基於分層融合注意力機製”的深度神經網絡模型,這讓 AI 獲得了模擬人類在閱讀理解文本時的一些思考、標注、通篇理解能力。
其實這種技術離我們並不遙遠,隻是可能平時沒太注意。記得淘寶的阿裏小蜜嘛,它就采用了這種機器學習閱讀理解技術。
當顧客對某個商品提出一些基礎性的問題時,阿裏小蜜可以直接對商品詳情頁麵中的信息進行閱讀和歸納,來解答用戶的提問,提高服務效率。
阿裏小蜜在雙 11、雙 12 大型購物節簡直就是人工客服的福星,把基礎性的問題交由智能客服去解決,複雜問題再留給人工客服,不僅減少了人工客服的工作量,顧客也無需在買東西時等待。
除了電商零售行業之外,機器語言理解技術也已應用於博物館指南、在線醫療問題解答等領域中。
說完阿裏巴巴,再說說微軟。微軟最出名的就是旗下的兩個人工智能助手小娜(Cortana)和小冰了。尤其是中國血統更加濃厚的小冰,在提供聊天機器人商業解決方案上麵應用範圍頗廣。
京東小冰、東航小冰、敦煌小冰……當你打開嵌入了微軟小冰的智能客服係統時,經過研究員對基於文本、語音、語義識別的幾次技術迭代,如今的小冰已經變得越來越“善解人意”,回答也越來越接近於人類的自然語言。
AI 在閱讀理解方麵都超過人類了!這次又該有一大波吃瓜群眾憂心忡忡, AI 是不是要取代人類了啊。TechPunk 想說的是作為不會犯錯的人工智能,總有一天會打敗容易 bug 的人類。當然別緊張,人工智能不一定稀罕取代你。




















