
時間:2017-11-16 來源:互聯網 瀏覽量:
AI 科技評論按:在2017年的微軟Malmo協作AI挑戰賽MCAC上,新加坡南洋理工大學助理教授安波帶領的團隊憑借他們的AI HogRider從來自26個國家的81支團隊中脫穎而出拿下冠軍。
安波是新加坡南洋理工大學計算機科學與工程學院南洋助理教授,於 2011 年在美國麻省大學 Amherst 分校獲計算機科學博士學位。他的主要研究領域包括人工智能、多智能體係統、博弈論及優化。有 60 餘篇論文發表在人工智能領域的國際頂級會議 AAMAS、IJCAI、AAAI、ICAPS、KDD 以及著名學術期刊 JAAMAS、AIJ、IEEE Transactions,今年也在 IJCAI獲得了 IJCAI early career award並進行了現場演講。 AI 科技評論之前也對安博士做過專訪,詳見 能玩德撲也能保障國家安全,南洋理工安波博士闡述算法博弈論的魅力何在?

近期,冠軍團隊也發出了一篇詳細的論文介紹了他們對協作AI的思考以及這次比賽的獲獎技巧(論文已經被AAAI 2018錄用)。 AI 科技評論把論文主要內容介紹如下。
比賽環境和規則
多個各自具有獨立興趣的智能體如何在複雜環境下協作完成更高級的任務一直是亟待解決的研究難點。 微軟的 Malmo 協作 AI 挑戰賽(MCAC)就是多智能體協作領域的一項重要比賽,鼓勵研究者們更多地研究協作AI、解決各種不同環境下的問題。
今年 MCAC 2017 中的挑戰問題是,如何在基於 Minecraft 的小遊戲環境中讓兩個智能體合作,抓住一隻小豬。
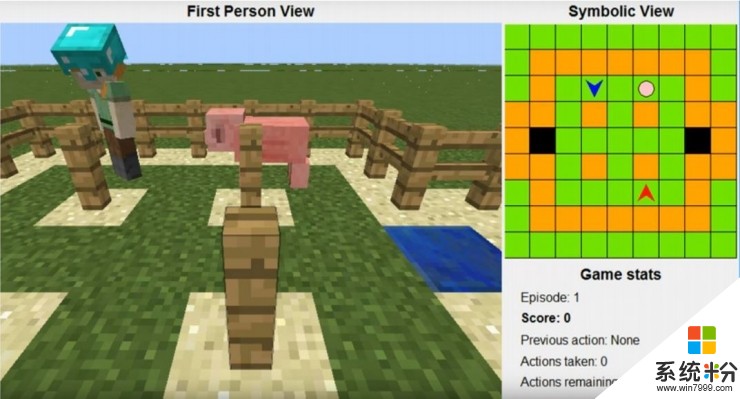
環境設置如圖所示,左側為第一人稱視角,右側為對應的符號化的上帝視角。區域一共9x9大小,綠色格子代表可以走動的草地,橙色格子是不能穿過的圍欄或者柱子,兩個黑色的格子是出口;粉色的圈是小豬;藍色、紅色兩個箭頭就是要交替行動、合作抓住這隻小豬的智能體;藍色智能體是比賽提供的,參賽選手要設計紅色智能體的策略,跟藍色智能體配合抓住小豬。
智能體的合法行為有三種,左轉、右轉以及前進。每局遊戲中,藍色智能體有25%的幾率是一個隨機行動智能體,另外75%的幾率是一個沿著最短路徑追著小豬跑的專注行動智能體。小豬的移動是完全隨機的,並且智能體得到的信息也是有噪音的。
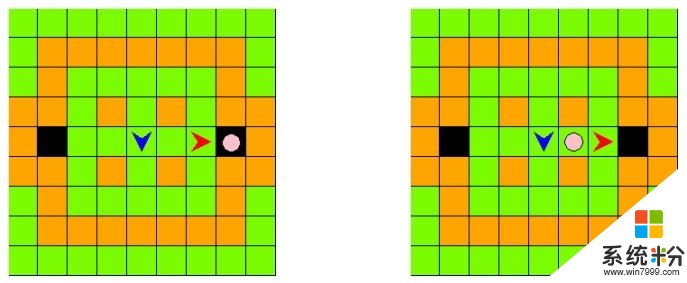
比賽的計分規則並不複雜,經過一定局數的遊戲(比如100局或500局)後,統計總分。智能體和圍欄/柱子一起把小豬完全圍住,兩個智能體就可以都得到25分,如上圖所示單個智能體把小豬堵在黑色格子或者兩個智能體共同夾擊小豬都可以,然後進入下一局;某一個智能體自己走到出口也會進入下一局,但這時隻有先走到出口的智能體可以得到5分;比賽選手的智能體每一個行動都會扣掉1分。另外,一局中智能體一共達到25個行動,或者達到大約100秒的比賽時間後,也會進入下一局。
從計分規則可以看出,參賽選手的智能體必須用盡可能少的行動步數抓到小豬才能得到高分,這個過程中也最好和比賽提供的智能體有所配合(能在更多位置抓到小豬)。
HogRider團隊的比賽思路
在HogRider團隊看來,多智能體合作係統本來就是一大難題。其中一個重要因素是智能體之間的互動問題,在許多實際情境中,由於每個智能體都是利己的,所以它們不一定會選擇共同合作達到高回報,而可能選擇回報更穩定的單獨行為(即便獲得的回報較少)。還有一個重要因素是不確定性,一種不確定性來自對環境和對其它智能體的有限的知識,這種不確定性還可以用概率模型應對,但也有一種更麻煩的不確定性來自某些環境相關的因素,很難用建模的方式處理。
而在MCAC這樣需要形成係列決策的環境中更會放大這些困難。首先因為除了短期回報之外,還要考慮長期回報,所以在變化的環境中必須考慮當前的行動可能帶來的未來影響。另一個關鍵特性是有限的學習次數,Minecraft中的一輪動作通常要花好幾秒,要學到一個高效的策略也就很花時間。
所以團隊分成了下麵幾步來應對。
首先分析遊戲環境,找到環境的關鍵難點和遊戲規則沒有揭示的特性。
比如遊戲規則並沒有給出小豬的行為模式,而它的行為模式顯然又很重要。在記錄了一萬步行動後,他們繪製出了小豬位置的分布圖,如下圖。
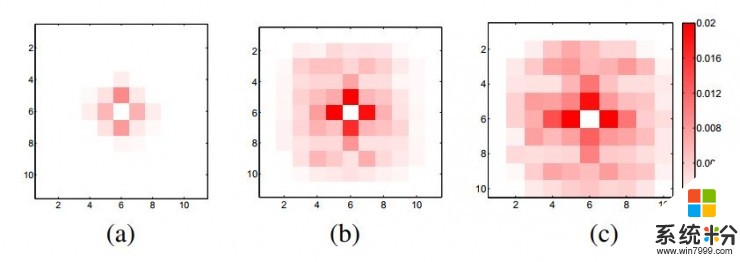
最中間的格子是小豬的初始位置,a、b、c三張圖分別對應參賽選手的智能體剛做出行動的那一刻、做出行動1秒鍾後、以及做出行動3秒鍾後的位置。
從圖中他們發現:1,小豬和智能體的行動規則不一樣,智能體走一步的時候,小豬可以走好幾個格子,甚至還能轉彎;2,小豬往每個方向走的概率是相同的;3,參賽選手智能體兩個行動間的時間越久,小豬位置移動的概率就越高。
這給他們帶來一個有幫助的想法,如果小豬當前在一個抓不住的位置,那就可以等幾秒鍾,等待它走到能抓住的位置了再讓智能體行動。
對於比賽提供的藍色的智能體,如前文所述它有25%的概率是隨機的、75%的概率是專注的;同時團隊發現,觀察藍色智能體的行為也有25%左右的錯誤率。如果忽略了這種觀察帶來的不確定性就很麻煩。
這就引出了第二步,提出了一種新的智能體類型假說,用來處理這種類型的不確定性以及觀察動作的不確定性。
他們設計了一個智能體類型假說框架用於更新對藍色智能體的類型的判斷,他們建立的方法能抵抗觀察動作帶來的不確定性。其中用到了泛化貝葉斯方法,並用雙曲正切函數壓縮類型判斷的更新因子作為抵抗觀察錯誤的方法。
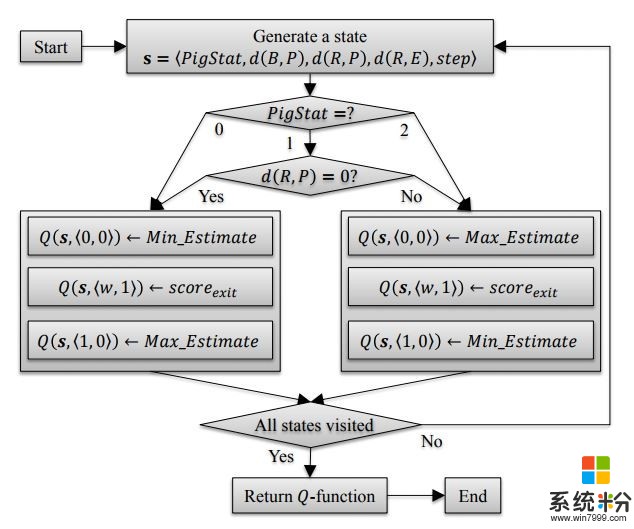
第三步,提出了一種新的Q-learning框架。
這是用來學習每一類型的智能體對應的不同最優合作策略。首先對“狀態 - 行動”的對應關係進行抽象提取,發現其實隻有智能體、小豬和出口之間的空間對行動決策有影響,就顯著減小了原本巨大的行動空間。然後,相比於傳統Q-learning中的Q值先用隨機值初始化再花很多時間訓練,HogRider團隊用了一個熱啟動的方法初始化,通過人類的推理過程形成決策樹。如下圖。訓練時也分別為另一個智能體是隨機或專注的情況訓練出不同的Q-函數,集成在Q-learning框架中。
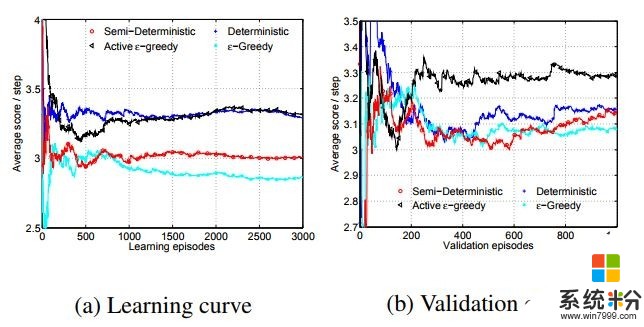
進一步地,他們還證明,當學習嚐試的次數有限時,一直在整個行動空間內做隨機探索是非常低效的(“ε-貪婪”),有時候甚至會妨礙找到最優策略,尤其是當找到的策略樹已經不錯的時候。所以他們提出了一個“活躍的 ε-貪婪”方法,以(1 - ε)的概率選擇現有策略,以 ε 的概率嚐試新的策略;如果帶來的表現提升概率大於認為設定的50%,就更新策略。這樣在“執行現有策略”和“尋找更好策略”之間比以往方法取得更好的平衡。
模型表現
首先看比賽分數。得分最高的5支隊伍分數如圖,每局平均分數(越高越好)和變化幅度(分數波動/平均分數,越低越好)方麵,HogRider分別領先第二名13%和21%。這表明HogRider在優化程度和穩定性方麵都表現很好。
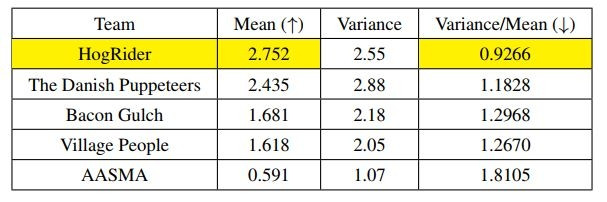
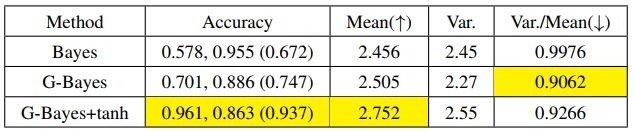
模型中選擇的一些具體方法也進行了單項驗證。比如第二步中更新對藍色智能體的判斷的方法,泛化貝葉斯+雙曲正切限幅的準確率和平均得分就比傳統貝葉斯方法高不少。
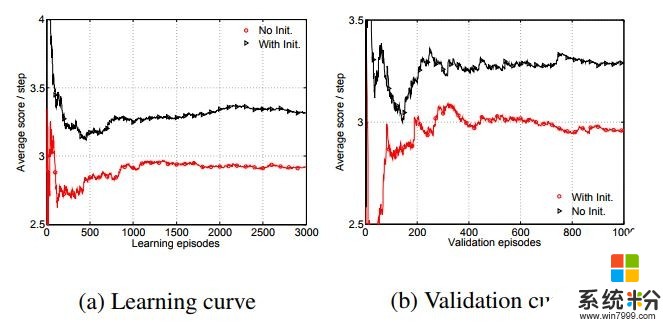
與專注的藍色智能體協作時,帶有熱啟動初始化的Q-Learning得分更高,學習曲線也收斂得更快
對於“活躍的 ε-貪婪”方法,通過學習曲線可以看到,淺藍色線代表的“ε-貪婪”方法果然出現了表現下降,“活躍的 ε-貪婪”方法則可以保證在訓練過程中表現總是在進步的。驗證曲線更明顯地體現了“活躍的 ε-貪婪”方法的優秀性。
HogRider團隊還邀請了一些在讀博士生嚐試這個遊戲,結果HogRider模型的表現比人的表現還要好不少,平均分數和變化幅度分別領先28%和29%。

比賽經驗教訓
論文中HogRider團隊也分享了他們的經驗教訓,以供其它研究人員或者比賽團隊參考。
首先,在開頭的時候一定要深入了解要解決的問題。HogRider團隊在設計智能體類型的集成框架和新的Q-Learning方法前經過了漫長的摸索,一開始他們選擇的不區分智能體類別的Q-Learning隻有非常糟糕的表現,畢竟要解決的問題確實會出現不同的特點,也有非常多的不確定性。前沿的算法固然是解決問題的有力工具,但認真了解問題的基礎特征才能確保自己走的是正確的方向。並且,要解決麵向應用的問題,最終的方案往往是多種技術的結合體,而不能指望單獨用某一種複雜的方法就可以一次搞定。
其次,人類的直覺可以幫助把機器表現提升到新的高度。團隊成員們一開始打算用DQN而不是Q-Learning,它雖然有良好的Q函數表達能力,但參數化的Q函數無法初始化。有一些用了DQN的團隊也是表現很糟糕。這種時候,帶有人類的推理能力幫助的Q-Learning就展現出了巨大優勢,這種初始化方式也可以用在更多背景知識可以幫助利用人類推理能力的地方。
最後,當發現新的隱含屬性後,模型和解決方案算法都應當跟著持續地更新。在比賽過程中,算法幾乎編寫完畢的時候團隊才發現觀察另一個智能體的動作原來是有一定出錯的比例的,這時候他們沒有偷懶,向算法中的傳統貝葉斯方法中增加了兩項額外的適配,也對算法表現帶來了顯著的提升。
結語
在對遊戲結構的細致探索之後,HogRider團隊結合了高效的智能體類型判斷方法,以及帶有熱啟動的新型Q-Learning(並運用了狀態-動作空間的抽象化和新的搜索策略),造就了HogRider的優秀表現。
在MCAC後,未來更有挑戰的研究方向是兩個完全不知道對方特點的智能體如何協作,以及開發能夠泛化到不同環境中的算法,這種時候智能體需要把離線學習和在線學習相結合,以及融合更多強化學習的方法。這都需要研究者們繼續努力,也還有更多有趣的新發現在前方等著大家發現。




















