
時間:2017-11-03 來源:互聯網 瀏覽量:
“作為一個研究人工智能二十多年,同時在醫學影像處理方向耕耘八年的過來人。我認為現階段醫療人工智存在的一大挑戰是,從業者們既沒捋順流程,也沒想清模式。單純覺得我有AI技術,有幾家合作醫院,就能大幹一場。現在風口的確很火,很多基金也願意投錢。但醫療與其他行業不同,它是一個文火慢燉的過程,不見得那麼容易。”
在與微軟亞洲研究院副院長張益肇博士對話的一個多小時裏,他不斷在強調人工智能在醫療領域的長期價值,但也有存在一些短期的擔憂。

張益肇博士現任微軟亞洲研究院副院長,負責技術戰略部。他於1999年7月加盟微軟亞洲研究院,從事語音方麵的研究工作,曾任微軟亞洲工程院副院長,是2003年工程院的創建者之一。
微軟之前,張益肇博士是全球最大語音識別公司Nuance Communications研究部創始人之一。張博士畢業於麻省理工學院,獲電氣工程和計算機科學學士、碩士和博士學位。
以下是與張益肇博士的談話內容:
:您怎麼看待今年醫學影像+AI大熱的現象?
當然是好事。
我經常談一個觀點,人類如果想要健健康康活到100歲,技術,將扮演著非常重要的角色。近幾年我也看到不少計算機界精英投入大量人力財力到醫療領域,如此大規模的醫工交叉大潮讓人非常激動人心。
這裏我也不得不提醒大家,在醫療領域,無論是創業者也好,投資人也罷,必須要有願意長期投入和投資的心態,切勿焦躁,保持平常心。
我個人研究人工智能二十幾年,其中八年時間在專攻醫療,我不覺得這個領域很容易出成果。
醫學技術的落地,不僅要千辛萬苦找對場景,還要說服政策製定者、監管部門、醫院采購者、科室主任、臨床醫生、病人等無數當事人證明技術的有效性、安全性和可行性。最後,你還要明白你的產品誰來買單。
現階段行業存在的一個挑戰在於,很多時候,大家這三大關都沒有想清楚。單純覺得我有AI技術,找到一些合作對象,就能大幹一場了。
現在醫療+AI的確很火,很多創投也願意投這個錢。但從長久來看,不見得那麼容易,也沒那麼快,大家一定要沉下心多調研、多思考、多學習。
美國很多新藥研發公司可以獲得大量的融資,有些甚至不盈利也能夠上市。大家期待它所研發的新藥品最終能通過FDA,並且在藥效達到預期後,公司市值能夠上漲5倍、10倍甚至更多。當然,麵臨一文不值的風險也非常巨大。
大家在投資時明知道風險很大,明知短時間內賬麵並不可觀,但仍舊願意投資、願意長期等待,因為他們能夠真正理解風險。
國內醫療人工智能大潮中,我最擔心的是國內醫療人工智能創業者和投資者並沒有真正理解風險,就開始投入大量資源在其中,這很可怕。
:微軟目前在醫療AI方向有哪些研究?
微軟其實在醫療領域投入很多,在世界各地的研究院裏有不少同事在做相關方麵的工作。
醫學影像處理這塊,微軟亞洲研究院和微軟劍橋研究院都有在做。不過微軟亞洲研究院聚焦在病理切片,英國劍橋研究院專攻CT。
我們微軟亞洲研究院近幾年開始鑽研腦腫瘤病理切片的識別和判斷,通過細胞的形態、大小、結構等,去輔助分析和判斷病人所處的癌症階段。近兩年在該領域我們基於“神經網絡+深度學習”的模式取得了兩大突破:
首先,實現了對大尺寸病理切片的圖片處理。通常圖片的尺寸為224*224像素,但腦腫瘤病理切片的尺寸卻達到了20萬*20萬、甚至40萬*40萬像素。對於大尺寸病理切片影像的識別係統,我們沒有沿用業內常用的數字醫學圖像數據庫,反而在ImageNet的基礎之上利用盡可能多的圖片,通過自己搭建的神經網絡和深度學習算法不斷進行大量訓練而成,最終實現了對大尺寸病理切片的圖片處理。
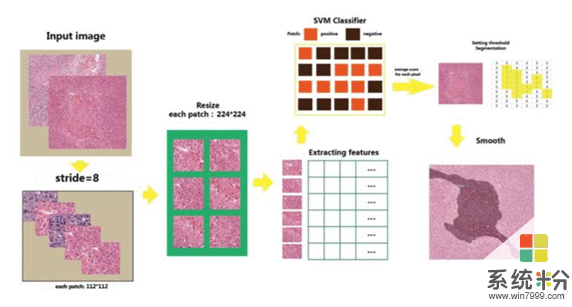
其次,在解決了細胞層麵的圖像識別之後,又實現了對病變腺體的識別。
對病變腺體的識別,主要是基於醫學角度三個可以衡量癌細胞擴散程度和預後能力的指標:細胞的分化能力,腺體的狀況和有絲分裂水平。我們針對這三個角度,通過多渠道(Multi-Channel)的數據采集和分析,希望在未來幫助醫生實現對病人術後、康複水平乃至複發的可能性做出預估和判斷。
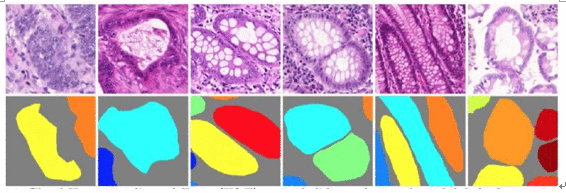
該研究結果也可以擴展至其他疾病的二維醫學影像的識別和判斷,例如我們正在研究的腸癌等。此外,我們還在研究肝腫瘤患者的CT三維影像。
除了醫學圖像外,我們在醫學文獻的處理和理解上也有所研究。
全球平均每年有將近50多萬篇醫學研究文獻發表,這種情況下,醫生在查詢所需文獻時,不可能覆蓋到位。
我們微軟亞洲研究院具體是如何解決這一問題的呢?比如醫生在尋找遺傳基因的研究與哪幾篇文章相關,我們會通過算法自動對相關文獻進行關聯。另外也在做不少與醫學相關的自然語言處理,比如不同病人想要問相關的醫療問題,可能有很多不同的方法來表達。而在話語裏又有像阿莫西林等藥物在不同醫院裏有幾十種、上百種叫法。
我們的工作就是用AI技術讓這些話語和詞彙的不同表達,轉換為機器可以理解的統一信號。最終以AI係統的形態解答各種醫學問題。
:團隊研究醫學影像處理這8年間,相比於過去有哪些大的進步?
深度學習算是一個比較大的跨越,坦白講,2013、2014年前後,深度學習開始被應用到醫學影像分析當中。按照傳統方式,很多醫學影像分析題目要做特征提取,這個特征甚至可能是細胞,過程較為複雜。
而深度學習可以自己學習並提取特征,節省了很多設計特征的時間。
其次就是遷移學習,我們在ImageNet上訓練出一個深度學習模型,以它作為基礎做醫學影像分析,雖然ImageNet上的圖像為自然圖片,但從中訓練出來的特征提取能力,對醫學影像也相當有用。
:這個過程中您發現了哪些新的思路,並走過哪些彎路?
2012年我們團隊開始用弱監督學習來更好地使用數據,這是一個對我們意義很大的方向。
大家也都知道醫生的時間非常寶貴,如果你沒辦法盡量節省他們的精力與時間,相比而言,你獲得數據的能力會更弱。用更優秀的算法去填部分數據的坑,這是一個很好的思路,而不是單純想著從醫院拿更多數據。
弱監督學習在醫學影像中的應用會是一個好的開始,也是一個值得長期投入的方向。
找到好的場景,再找到好的數據庫,其實比大家想的要耗時。很多時候,找到一個優質數據庫外,還要找到一個既懂技術,又能幫忙做標注的醫生。
對於我們走過的彎路,更多是認知和思維上的彎路吧:過早覺得我們已較好地解決了醫學問題。
包括我們在內的很多公司用Kaggel數據做基礎訓練,但這種研究僅是長期研究的起步,而且這個起步往往並不見得特別有用,所以大家應理性看待從Kaggle中訓練出的結果。
在醫療+AI方向,大家不要迷信短時間內得到的數字結果,一定要做好長期投入的準備。
語音識別從1960年代就開始萌芽,直到1970也還是所謂的非連續性語音識別,離絕大部分使用場景很遠。盡管語音識別在今天已經解決得很好,但在複雜環境和語境下的識別率仍舊不是特別理想。
人工智能在醫學中的應用亦是如此。
:像您剛提到的深度學習和遷移學習讓醫療人工智能大跨步發展,但這兩者的不可解釋性使得很多醫學問題無法詢證,這個難題目前微軟亞洲研究院有沒有一個標準對其進行參考?
深度學習的可解釋性確實是一個很熱的題目。
算法可解釋性通常可以用看邊界和顏色特征來判斷正負,偏統計學方法,但也很難說出具體原因。
其實很多醫學任務也是靠統計來做。之前有醫生提到說,假如一個腫瘤小於5厘米和大於5厘米該各應怎麼判斷。大家提到“5厘米”這個單位也憑經驗去描述,為什麼是5,而不是5.1或4.9。
我的意思是,醫學本身很多判斷是依照經驗來做,這些經驗裏,也存在一些無法解釋的因素,因此不能完全否定“不可解釋性”。
很多AI功能尤其像靠深度學習訓練出來的係統,除了給你一個明確的判斷外,還會生成百分比形式的“程度值”做參考,這個程度值體現機器對判斷的“自信”與否。
現階段我們希望隻做輔助醫生的工具,最後的結論還是需要醫生自己判斷。
任何係統都多多少少會產生一定的誤差和偏差,哪怕簡單的血壓儀也可能存在偏差,所以最終還需讓醫生把所有信號整合起來判斷機器給出的結果是否合理。
:也確實因為深度學習存在的弊病,最近Hinton提出要“拋棄”反向傳播,您怎麼看待這件事的?
反向傳播也有幾十年的曆史了,這期間陸續有人提出不同的想法、不同的算法。
人的學習能力很強,無需很多數據,往往通過一兩個樣本就能學習、分類,但現在機器沒有辦法靠少量不同樣本進行驅動。
所以人工智能在算法層麵可提升的空間很大,所以要有新的學習方法來做,尤其像可供使用數據量較小的醫療領域。
:相比於醫學影像處理,語音電子病曆錄入服務各方麵的條件更為成熟,Nuance和訊飛都已在醫院落地,微軟亞洲研究院目前有沒有切入這個方向?
推出這類產品,需要做的事情就比較專比較細了。
我加入微軟之前在Nuance Communications做語音識別,你提到的語音電子病曆錄入是Nuance的主要業務之一。
但國內很多人可能有所不知,Nuance的業務裏,語音轉錄係統隻是一方麵,另一方麵Nuance還需雇人把機器轉好的文字,進行人工整理。所以Nuance提供的是一整套服務,而非單一的語音識別這一環節的產品。與此同時,Nuance針對不同場景、不同科室做不同的產品優化和服務。
所以如果做這類產品,研究之外的任務和工作相對來說會比較多。
:您此前一直研究語音,是什麼原因致使您開始做跨度很大的醫學影像?
從研究角度講,無論是語音還是影像,兩者之間有很多相通點,都是基於機器學習作為發動機,數據作為汽油來建模、判斷。
當然了,醫學影像也確實有很多專業知識需要學習,更具挑戰性,同時也更有意思。因為你需要跟很多不同領域的人一起學習,這個過程非常有意思。
另一方麵,那時候我母親得了癌症,我當時心想醫學如果借助計算機技術一定會找到更多新的方法和新的應用場景。作為普通民眾,我覺得這對身邊人,對社會非常有意義。作為研究人員,這個研究方向會非常有前景。
:微軟亞洲研究院的醫學影像數據來自哪些地方?與哪些機構有合作?
主要還是來自於公開數據集,首先這類公開數據標注經過很多人審核。其次,你要發表結果的話,同一類數據集上大家才有可比性。
在某些特定領域,我們與浙江大學前副校長來茂德團隊合作探索病理切片分析,來校長在大腸癌方向有著很多積澱。大腸之外也有研究肺癌等國內常見的幾個方向。除此之外,生活習慣和飲食健康也所有探究。
:提到肺癌等國內常見的方向,上次我跟訊飛陶曉東博士交流時,他講到其實目前選擇做眼底、肺結節這類常見的、公開數據較多的領域,可以反映出大家創新力不足的現狀。微軟亞洲研究院在布局常見的方向之外,還在探索哪些挑戰性特別大的方向?
我們現在做病理切片的一大原因,就是因為病理切片分析極具挑戰性。
首先病理切片單個數據很大,一張圖最大可達40萬×40萬像素,麵對這麼大的數據該怎麼分析?要怎麼才能把這個係統應用得很好?這是很有趣的問題。
如此大的圖像,單是傳輸就已是一項很大的挑戰,在此基礎上還進行分析,計算量會非常巨大。
好在微軟亞洲研究院也有很多同事是係統方麵的專家,研究高速運算,基於此,我們可以通過整合研究院不同團隊的專長來做這件事。
:這個過程當中微軟亞洲研究院各個技術部門之間如何打配合?
各部門之間的合作其實蠻多。
2015年我們視覺計算組發明的ResNet大家都很熟悉了,它就是一個特別好的圖像特征提取方法,有了它之後,我們就在考慮如何用ResNet提取醫學影像特征。
微軟亞洲研究院已經在做一些通過看一張圖然後對它進行標注的技術,當機器可以給一張圖自動標注的話,這就表明機器在一定程度上理解這張圖,不僅知道裏麵有哪些物體,同時也知道裏麵物體及場景之間的關係。
這屬於更高層次的理解。
回到肺結節上,通常情況我們隻是去判斷某塊小區域是不是肺結節。其實有時候通過分析肺本身以及人體的構造,也可以得出其他有用信息,而這些肺結節之外的信息,往往對診斷起到非常重要的作用。
目前大部分係統並沒有有效利用到這些“其他”信息,但影像科醫生與機器不同,他們在讀片時,肯定會對這些信息有宏觀的認知。所以我也經常在講,人工看一張圖片時,他不會隻看一小部分,而是會形成一個整體的認知去判斷。
所以,無論是一張普通海景照片中船和海的關係,還是醫學影像中肺結節和其他組織信息的關聯度,很多方麵是相通的。我們希望把對常規圖像的認知和理解,遷移到醫學影像中,這是一項非常重要的工作。
:如果還要判斷其他組織信息,那麼在對眾多非目標對象的分割上,是否有產生更多更複雜的新問題?
確實如此,我再舉個例子,正常人的心髒在左邊,因此做內髒分割時,會有這樣的預知。但是也不排除少數人心髒長在右邊的可能性,類似這種情況容易讓機器產生誤判和混淆,因此需要有更高層麵的的知識理解。
但總體而言,現在在做的機器學習研究,無論是檢測、識別還是分割也罷,很多地方都是相通的。
:除了影像和語音語義之外,微軟還有哪些醫療人工智能方麵的研究?
我們在大數據處理上探索也非常多。
負責管理微軟全球研究院的Eric Horvitz,他既是醫學博士,也是哲學博士。Eric Horvitz做了很多非常有趣的研究,通過用戶在互聯網上的搜索詞,來判斷你是否有一些疾病和症狀。
:那麼這個研究的最終形態是以一個什麼樣的終端功能或者服務去呈現?
我們有一項服務叫微軟Health,就是用一些功能,來提供insight,這些insight一方麵給用戶看,一方麵提供給醫生參考。
比如通過係統收集到很多人的血糖、血壓甚至睡眠和運動量數據後,存儲起來進行長期的追蹤和分析。基於此,把這些信息全部整合起來後更好地幫助醫生、幫助用戶自身。
我們也與美國匹斯堡大學醫學中心UPMC合作,探討用AI挖掘有效健康信息。
一方麵我們在做很多基礎研究,另外一方麵,微軟也希望尋找更多合作夥伴,探討可以著陸的場景。
:“長期”大概是多久?
取決於場景本身。
我們與蓋茨基金會的合作中,在非洲用機器來判斷一個人是否有得瘧疾,同時得出病症的嚴重程度。
在國內大家談機器與醫生的對比,但非洲這些地方連醫院醫生都沒有,相對來講,有一個工具給病人診斷,已經是一個很大的醫療進步。
這個例子,我相信在未來短期三五年之內,會有著很大的幫助,現在有些產品已經在一些相對落後的國家試用。
但在比較發展的國家,醫生已經有比較成熟、習慣的工作方式,供應商的係統要進入到醫院,需要想清楚整個環節才有辦法幫助到醫生。因為多種客觀因素,會致使過渡時間更長。
當然了,如果找好場景的話,最快兩三年之內就可以安全著陸。
:您覺得哪幾個場景前景相比而言會比較明朗?
目前市場上很多企業在做診斷,其實我覺得可以往前探一步:做好分割。
一個醫生在做放射性療法之前,要先把不同放射性療法所影響到的這些不同區域標出來,並進行分割。分割工作的人力和時間成本很高,如果現在有一個工具能夠自動進行分割,再讓醫生去確認,需求會比較大。
當一個係統先對影像做標注,醫生去看的時候已經有90%完成地很好,沒做好的地方醫生再去修改,最後一關由醫生來把守,這種輔助工具醫生也很樂意接受。
:談談未來微軟醫療人工智能的展望?
我們希望能從人一出生開始便了解你的整個健康情況,通過收集身體信息,實時分析你生活和機體哪些地方需要改進,如飲食、睡眠、運動、病痛等等。
我覺得在未來應該會演進為這種形式,每個人都有一個專門屬於他的醫療人工智能健康助理。
:產品形態是2C的形式嗎?
這個倒不見得是2C,更多是2B2C模式,產品在麵向終端用戶時也要有醫生的參與。像美國就有很多家庭醫生,可通過家庭醫生把係統推向病人。
:哪些新的人工智能技術將會對醫療行業帶來巨大變革?
其實“如何把不同的信息在不同層次進行整合”這一認知層麵的課題,整個行業仍舊存在很多不足,現階段單是把知識結構化就是一項很複雜的任務。如果解決了上述問題則對技術體係和行業的推動力將非常大。
我們先以機器翻譯為例,大部分機器翻譯還是單句單句翻,但一段段翻跟一句句翻就很不一樣了,它涉及到“理解”。再以圖像識別為例,機器識別出圖像中有藍色的天空和藍色的海和帆船,但如果突然出現圖像中的天空為紅色,而它過去的訓練集中沒有對紅色天空進行標注,那機器能懂得紅色的天空代表是晚霞嗎?
因此我們要讓機器建立起一個對故事、對世界、對環境的認知能力。
這裏的難點在於,它有很多很多參數的變化,你不可能讓機器學習把整個世界的種種元素挨個看一遍才能理解。而是應該創建一種新的方法,把不同地方學到的知識給整合起來,從而解釋出圖像看起來是合理的。
醫學影像的解釋同樣如此,醫生在看MRI影像時,基於經驗判斷某個人是女性,但有一些地方卻不像女性(如變性人等)。這時候要有更高層的知識能力、知識架構,也就是用Mental Mode去解釋去理解,這會是一個很大的挑戰,同時也是一個很大的機會。
:當前很多像醫院等傳統機構對AI處於觀望狀態,市場還需教育。企業應該如何讓各行各業的人更快了解人工智能?
為什麼互聯網興起後能迅速影響到各行各業?因為那時候大家即便不懂互聯網,但至少有瀏覽器產品供我們使用,雖然有別於可觸摸的實體物品,但我們可以看到互聯網產品的界麵,也可在上麵進行操作和交互,這才使得人們對互聯網的認知建立的如此之快。
人工智能普及進度慢,一大原因就是沒有一些典型的終端產品讓大家直接感受。要想教育一個市場,最好的方式就是讓他們去體驗AI的能力。
:您在微軟亞洲研究院任職18年,談談這裏留住您最大的一個原因是什麼?
在這18年裏,我最大感觸是微軟亞洲研究院為很多優秀的研究員創建了能夠長期鑽研細分領域課題的極佳環境。在微軟亞洲研究院這樣的基礎研究機構裏,好比在MIT、斯坦福,我們在長時間探索各式各樣的有趣題目。
近兩年量子計算很火,但很多人所有不知,我們研究院從十幾年前便開始做量子計算了。除此之外,也有美國的同事在探索用DNA來存儲信息,人體中一個DNA大概有4GB內存,你想想,一個細胞大小的體積便能存儲4GB的內容,密度遠高於我們用的SD卡。
像這種看得很遠的方向,隻有在研究院才有機會去接觸,這對任何一位研究者都極具吸引力。
蓋茨早在26年前便建立微軟研究院,並且在同期啟動三大研究組:自然語言處理組、語音組、計算機視覺組。
這些研究在當時來看,離落地非常遙遠。
但微軟今天能夠站在人工智能最頂端,不是因為我們體量多大,也不是我們人才夠多,而在於研究院和熱愛研究的這一批批人早已為此準備26年之久。





















