
時間:2017-10-24 來源:互聯網 瀏覽量:
科學圖表能簡潔地概括趨勢、速率和比例等有價值的信息,讓我們直觀地了解概念。而機器對這種結構化視覺信息的理解能幫助我們從大量文獻中提取信息。
這不,微軟旗下的Maluuba對這事的研究有了新進展。
近日,Maluuba推出了一個用於推理的可視化數據集FigureQA,並將研究相關論文《FigureQA: An Annotated Figure Dataset for Visual Reasoning》發布在ArXiv上。量子位挑其重點編譯整理,與大家分享。
數據集簡介
在關係推理最新研究的啟發下,研究人員推出了FigureQA數據集,其中包含了基於10多張圖表的100多萬對問答,用於研究機器理解和推理方麵的問題。
FigureQA數據集中有五種常見的圖表模型,這些圖表能顯示連續的和分類信息,分別為折線圖、點圖、垂直柱狀圖、水平條形圖和餅圖。而其中的問答對,會涉及到圖表中元素一對一和一對多的關係,例如:X是中位數嗎?X與Y相交嗎?得出正確答案需要對多圖表中的要素進行推理。
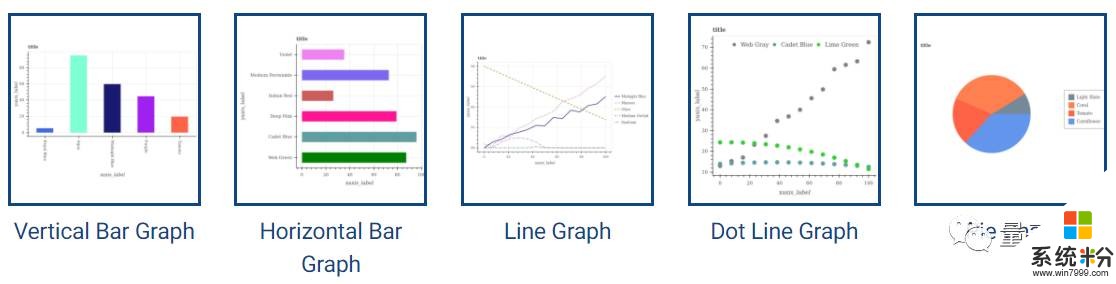
△ 數據集中包含的5種圖表類型
數據集中的問題,共有15種類型,涉及到數值大小、最大值、最小值、中值、曲線下麵積、平滑度和圖像交叉點等信息。

△ FigureQA中包含的15類問題
問答集中問題均基於上述問題,答案統一為“是”或“否”。
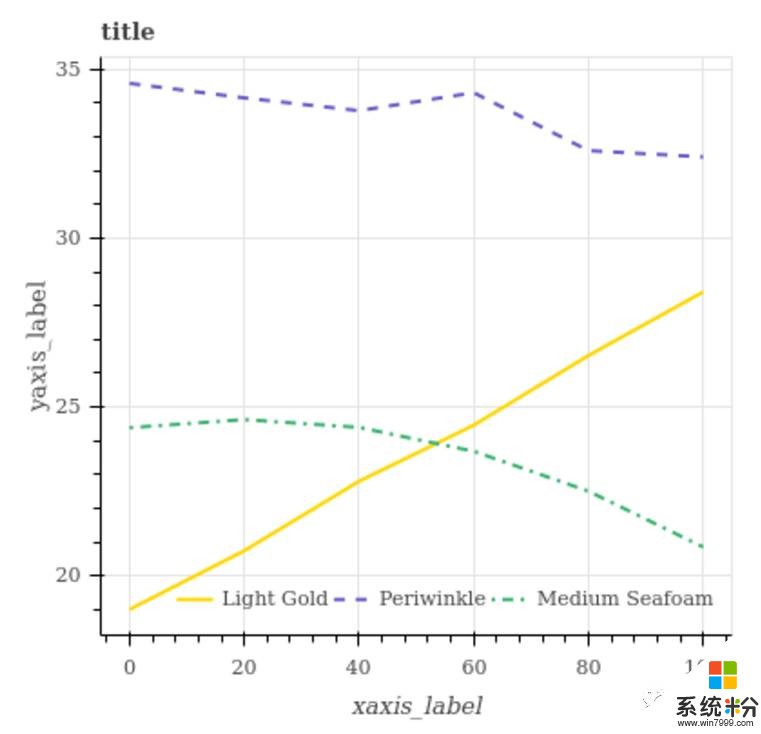
△ 數據集以問答的形式呈現。Q:Medium Seafoam和Light Gold相交嗎?A:是。Q:Medium Seafoam是否有最低值?A:否
微軟團隊在介紹論文中表示:“FigureQA是一個合成的數據集,類似視覺推理相關的CLEVR數據集。雖然數據沒有真實環境中那麼豐富,但能更大程度控製任務的複雜性,還支持輔助監管信號。此外,通過分析在FigureQA上訓練的模型真實數據,還能擴展語料庫處理弱項問題。”
製作過程
FigureQA數據集的生成製作分階段進行。
首先,研究人員根據一組經過仔細調整的約束和啟發式設計對數值數據進行采樣,讓使取樣數據顯得更自然。隨後,研究人員用開源可視化庫Bokeh繪製圖表中的數據,得到定量數據。
此外,研究人員修改了所有圖表的Bokeh後端輸出的邊界信息:包括數據點、坐標軸、坐標軸標簽、標記和圖注等信息。他們還提供了底層數值數據和一組邊界數據作為每張圖表的補充信息。
最後,研究人員平衡了每個問題答案中“是”和“否”的比例,這保證模型不會利用回答頻率上的偏差來推斷結果,而忽略視覺內容。
測試結果
在論文中,研究人員表示,FigureQA中測試集的準確率還達不到人類水平。接下來,研究人員計劃測試在FigureQA上訓練的模型在真實科學數據上的表現,並將數據集擴展到人類編寫的自然語言問題上。FigureQA“官方”版的數據集可公開使用,是未來研究的基準。
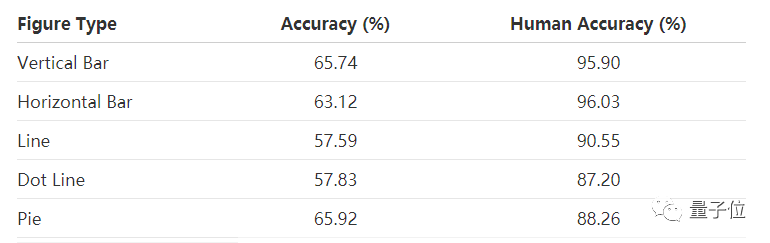
△ 數據集與人類回答15種問題的準確性對比
研究人員還提供了生成腳本,它們配置容易,使用戶能調整生成參數生成自己數據。
資料下載
https://datasets.maluuba.com/FigureQA/dl

關於FigureQA的介紹我們可以在ArXiv上一探究竟:
祝你玩得愉快~




















