
時間:2017-04-14 來源:互聯網 瀏覽量:

本文共6633字,建議閱讀22分鍾。
[ 導讀 ]本內容選自微軟亞洲研究院副院長、主任研究員周明在2017年4月6日清華大學的“編程之美挑戰賽”啟動儀式上的分享。由微軟主辦、電氣電子工程師學會(IEEE)協辦的2017編程之美挑戰賽在清華大學拉開帷幕。已成功舉辦五屆的編程之美挑戰賽今年全麵升級,旨在在人工智能時代幫助學生了解和學習最新的技術理念、動手實踐熱門的技術與開發工具,通過團體比賽的形式鍛煉學生的協作溝通能力,進而提升青年學子以技術實踐解決熱點問題的綜合能力。

演講全文如下(文字內容略有精簡):
做理工科的同學很擅長純粹的科技,其實科技和人文的結合更有意思,我希望在座的同學在參加編程之美大賽的時候,能夠腦洞大開,想出一些奇思妙想的東西,超越前輩,做得更好。
今天我要介紹一下自然語言對話。其實微軟小冰就是在模擬人跟電腦的對話。電腦接收文字、圖像或者語音,識別其中的內容,然後給予適當的回複。有的回複很有意思,讓人覺得好像電腦後麵就坐著一個真實的人,但有的時候回複也差強人意,而這正是我們這次編程之美所期待的,希望大家一起加入到人機對話的創新過程中,把人機對話做的更好。
我們團隊在微軟做自然語言人機對話方麵的研究,並提供了小冰的關鍵自然語言處理技術。下麵我將介紹一下人機對話機理,希望對大家有所幫助。
人機對話有三個層次,一個是聊天,一個是問答,還有一個是對話,即麵向某一特定任務的對話。比如,我要買東西時,一進門,售貨員會打招呼說,“你好!”,我回複“你好”。接著她會問“你想看看什麼?”,我說“我想買兩包方便麵”。她問“什麼牌子的呢?這個三塊錢一包,這個五塊錢一包”,我說“那要三塊錢一包的吧。”她說“那好,你用支付寶還是微信付款呢?”我說“微信”。她說“好,這就是你買的東西”。
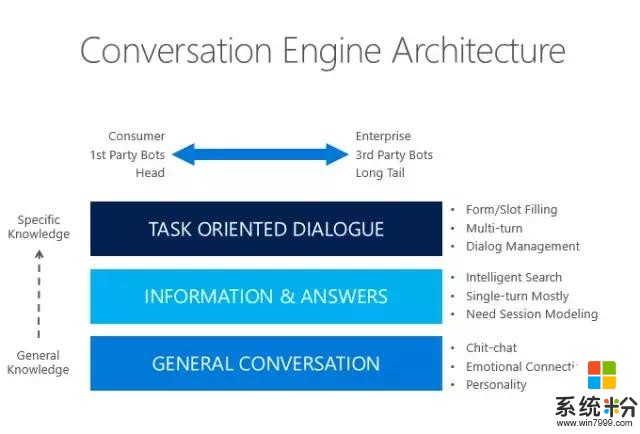
可以注意到,在我們每天都會產生的這些對話中實際上包含了三個最基本的人類智力的活動。第一個,聊天。聊天一般沒有太多實質性的內容,主要是拉近人與人之間的關係;第二個就是問答,比如“你買什麼東西”,“這個方便麵多少錢一包”,這是提問,它的目的是提供信息;第三個,麵向特定意圖的對話。比如售貨員知道我的意圖是買方便麵,開始圍繞這個意圖跟我進行了有目的的對話。最終我完成支付行為,售貨員把方便麵放到我手上。這三個技能是我們在研究人機對話當中最重要的三個技能。
最近幾年,深度神經網絡逐漸取代了傳統的統計機器學習,成為主流的研究方向。現在,自然語言技術已全部轉向深度學習網絡,我們的對話係統也都用到了深度學習網絡,所以先向大家介紹一下深度學習網絡。
深度學習網絡一般有一個輸入層,一個輸出層,中間有N層是神經網絡,他們之間通過一種連接方式以不同的權值來發揮作用,當輸入時,根據神經網絡的權值逐層推進,就會得到一個輸出。
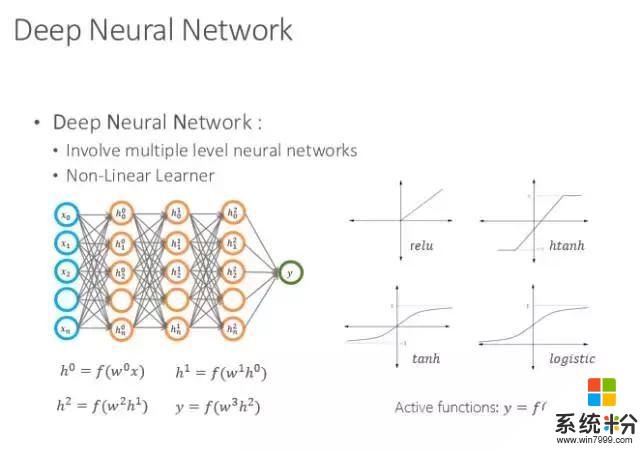
其實在訓練的時候有很多樣本,輸入和輸出是對應的。當輸入到神經網絡時,有的時候會發現結果不對,那麼則可以根據它與答案之間的差距進行反向傳播並修正參數。當網絡趨勢越來越好,那麼到一定時候網絡就可以收斂,進而網絡就達到了一定的智能行為,這就是最簡單的神經網絡架構。
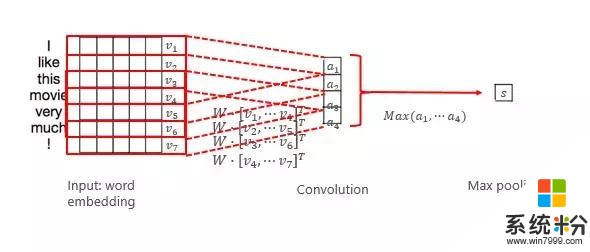
再來說一下常見的卷積神經網絡的基本原理,我們以低密、低維的卷積神經網絡為例。它實際上是從頭開始,會以一個小的窗口進行滑動,每個窗口截取一定的信息,並抽取出來做卷積,這叫卷積的行為。而每次滑動都會得到一個值,最後得到一個卷積的結果。一般卷積之後還可以抽取最大值,這整個過程都體現了信息抽取的過程。
第二個比較常用的是二維的卷積,它是在矩陣裏找一個小的窗口滑動,每個窗口通過卷積得到一個值,再通過填充所有窗口可以滑動的位置最後得到結果,這就是二維卷積的過程。
第三個叫循環神經網絡(RNN,也叫遞歸神經網絡),它描述的是一個序列串的過程。任何位置的輸出都受限於前一位置或前一狀態的位置信息,我們叫隱狀態ht-1的信息,它和當前的輸入字符串的信息一起會得到當前的隱形狀態ht,然後根據這個當前的隱狀態再預測每個詞的輸入概率。
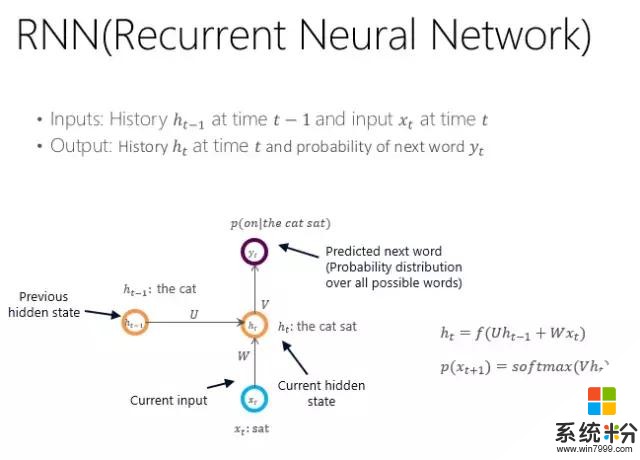
循環神經網絡訓練完以後,任何句子都可以走這樣的循環神經網絡了,它的結果是由N個隱狀態組成,而最後的隱狀態,我們則可以認為它繼承了前麵所有句子、詞的信息。
當然,每個位置也代表了到目前為止句子的信息,所以使用時,要麼用最後一個結點,要麼就把結點全用起來,形成一個向量來代表當前句子的編碼。這樣訓練就比較簡單了,一個句子進來走一遍剛才的這個過程,就可以得到每一位置詞的輸出概率,這些概率之乘就是這個循環神經網絡的損失函數,然後根據損失函數,用反向傳播去修正網絡的連接強度,最後等網絡穩定時就可以得到循環神經網絡。

所以,隻要有大規模的語料庫,通過這種訓練方法就會形成一個描述當前語料庫每個句子的循環神經網絡。
再來介紹一下剛才所說的三種對話的功能。第一個,聊天是怎麼做的,這樣的人機對話是怎樣形成的?其實一般有兩種辦法。一種很簡單,就是將網上的論壇、微博或是網站裏出現過的對話句子抽取出來,當成訓練語料庫。當來了一個句子時,係統會從語料庫裏找到一個跟這個句子最相像的句子,而這個句子對應的答複就可以直接輸出作為電腦的回複。雖然看起來這個方法簡單粗暴,但有時候還是挺有效的。
然而有的時候,係統找到的句子可能對應了很多回複,它不知道哪個回複最適合當前的輸入語句。所以這裏就要有一個匹配的過程,就是怎麼判斷輸入語句跟語料庫裏的回複在語義上是相關的或者是一致的。
這裏就有了很多度量的方法,給大家介紹其中的兩種。
第一種,如下圖,q代表當前輸入的語句,r代表目前的一個回複,想看q和r是否相關或者一致,要給它一個分數。如果有多個選擇時,首先要把所有的東西排下去,輸出最佳的分數,即實際上是對整個句子進行編碼,對問題、回複進行編碼。編碼的方式可以用循環神經網絡,也可以用卷積神經網絡,也可以用最簡單的就是每個維度取平均值,最後算一下這兩個向量之間的距離。
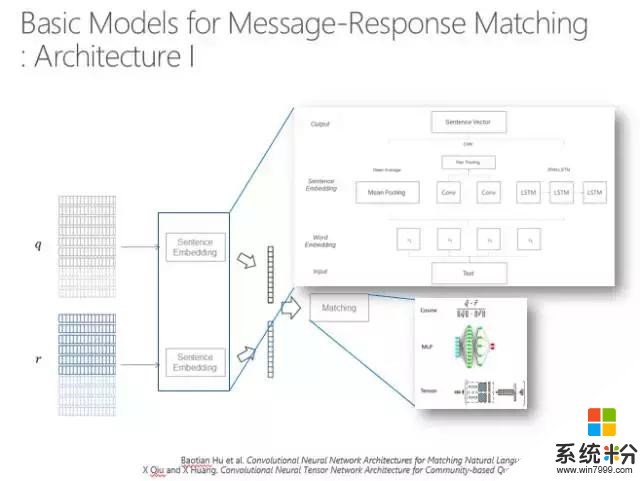
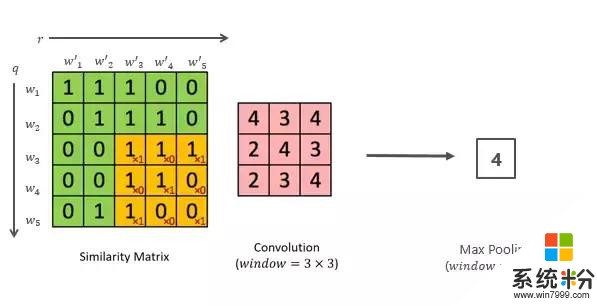
第二個方法也比較簡單,就是把問題和回答的每個詞都算一個距離,這樣就形成了一個相似度的矩陣,通過卷積得到矩陣變換的信息,然後再取最大池化層,矩陣的維度就越來越小,最後可能就做到一個結點上。這個可以有多種變換,那麼最後就會有一組結點,所有的結點其實都代表了這兩個字符串之間的距離,再通過多層感知就可以算出句子。
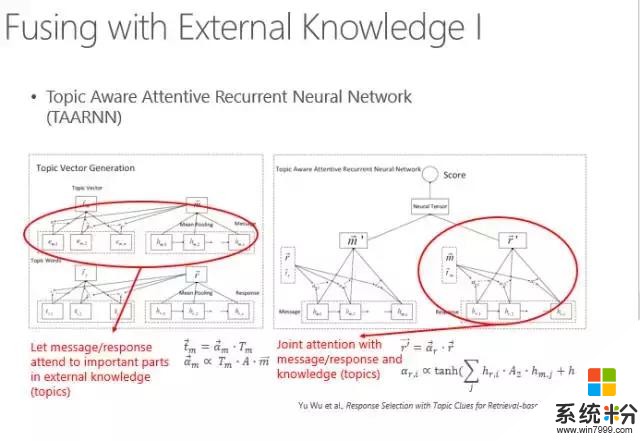
然而這些方法都有一個問題,就是短字符串匹配的時候太依賴於自己的信息了。而我們日常說話時往往是有背景、有常識的,我們說的每句話都有一個主題詞表。比如我來到了清華三食堂,那這個背後的主題詞可以說吃飯、早飯、中飯、晚飯、價錢、飯卡等,這些詞都是跟它相關的主題詞,匹配的時候要體現出這些主題詞。
怎麼體現呢?首先找出輸入語句的N個主題詞,然後再找出可以回複的那些句子的主題詞,用主題詞來增強匹配的過程。這也是通過神經網絡來算兩個詞串,再加上主題詞增義的相似度。
具體算法實際上是通過Attention model(注意力模型)計算每個主題詞跟當前這句話的匹配強度,所有主題詞根據強度不同進行加權以體現當前背景主題詞的強度,然後再和原句匹配在一起,來算相似度。
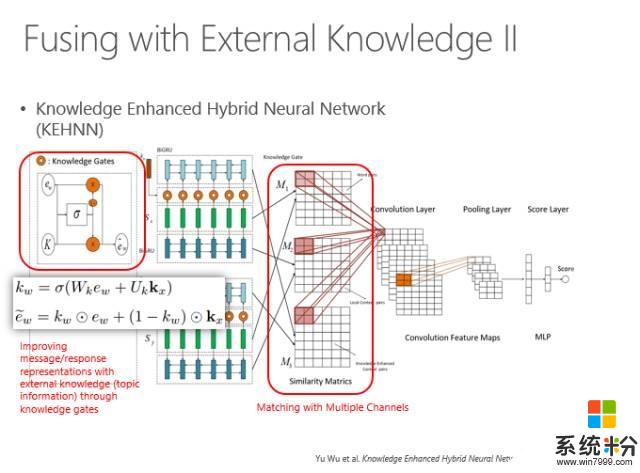
另外,我們也可以把主題詞當成所謂的Knowledge base(知識圖譜),通過主題詞限定當前的輸入應該有哪些信息可以輸出,哪些信息不要輸出,哪些信息應該補足,哪些信息可以直接使用等等。實際上在具體實現時可以看到一個句子有三種表示方法,兩個句子之間每個句子都有三種表示方法,用兩兩表示方法計算距離,最後就會得到一個矢量,再通過多層感知得到一個數值,來表征這兩個輸入串的距離。所以,這兩個輸入串不是赤裸裸地直接去匹配,而是用周圍知識所代表的主題詞來增強。
以上是基於搜索的一種回複方法,我們也可以用生成模型,其實生成模型走的也是神經網絡的路線。輸入一個句子,然後通過循環神經網絡進行編碼,再通過解碼的過程輸出每個詞。當機器翻譯的時候是跨語言的輸出,由原文輸出譯文,而在古詩裏是第一句生成第二句,在這裏就是輸入一個用戶的問題得到一個係統的回複。
這就是一個生成的過程,可以看到圖中下部是進行一個句子的編碼,用這個編碼指導每一個詞的輸出,在輸出時既考慮原始句子的編碼,也考慮前麵的詞輸出什麼樣的詞以及前麵的隱狀態是什麼,最後傳遞輸出,直到輸出詞尾。
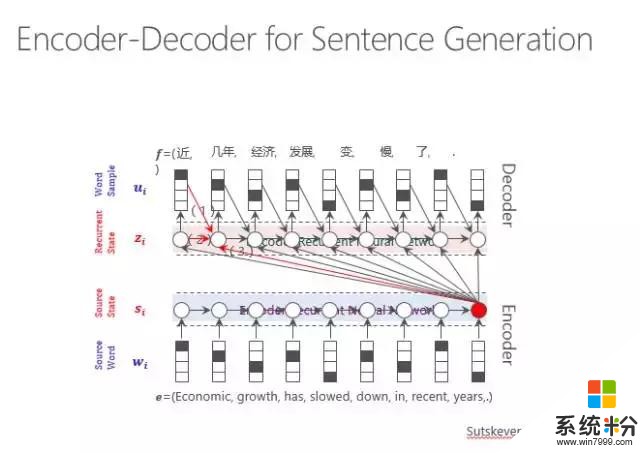
實際上,輸出時不能一而貫之所有的詞都等價對待。有的詞權重比較高,這就由Attention model來體現輸出某一類詞時,哪個源端詞對它的影響力最大,要體現在輸出的概率方麵。
用傳統的RNN以及注意力模型就可以做問題輸入,係統回複。但是它也有很多問題,比如它的回答太枯燥不豐富,那怎麼辦?
我們要用到外部知識來豐富回答。我們可以用主題詞增義。原始的句子可以用Attention model輸出每個位置的詞,然後再增強跟這個句子有關的主題詞,把主題詞編碼,也做一種Attention model來預測輸出。一個詞的輸出除了來自源端的信息之外,還受到了主題詞的製約,最後輸出的概率是這兩個輸出預測結果的概率之和,選擇一個最優的來輸出。

剛才說的是單輪的,現在說多輪怎麼回答,因為人在說話的時候是考慮上下文的,不是隻看當前的一句話,多輪的信息都要考慮進去。所以要把整個對話(session)考慮進去,對session進行編碼,用session來預測輸出的回複。
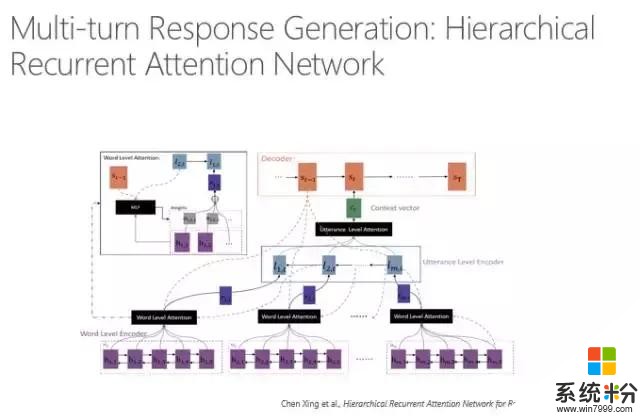
在計算的時候,我們有幾個這樣的模型。剛才是基於搜索的方式,還可以用多層感知的方式來模擬多輪對話。對每一個之前出現的句子進行編碼,每個編碼都可以通過一個句子的編碼體現整個句子的信息,再通過Attention model跟目標連接,最後預測的時候就是通過基於句子的Attention model來預測。大家可以理解為我們在回複的時候既要看到前麵哪一句話重要,還要看到那一句話裏哪個詞重要,所以是一個雙層的Attention model。
以上是關於聊天的介紹,還有問答和對話。
問答就是用戶有問題,係統要理解這個問題,然後利用係統所有的資源來回答這個問題,資源可能是FAQ、文檔、表格、知識圖譜等等,哪一個回答出來了,就說明哪一個是答案,如果有多個資源都可以回答問題,那我們選取那個最有可能的來進行輸出。
簡單說一下所謂Knowledge base(知識圖譜)有兩條路走,一條是對用戶的問題進行語義理解,一般用Semantic Parsing(語義分析),語義分析有很多種,比如有用CCG、DCS,也有用機器翻譯來做的。它得到了一個句子的邏輯表示,根據邏輯表示再到知識庫裏去查,查到這個結點是什麼,關係是什麼等,通過這種方式,自然而然就查到了。
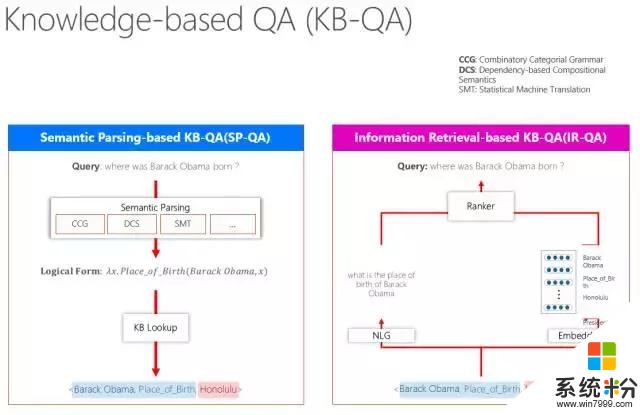
還有一種辦法就是最近幾年流行的信息檢索方法。比如,一個問題“where was Barack Obama born ?”這句話裏出現的了一個實體——Obama,假設這個知識庫是完備的,那麼係統就會判斷答案一定是跟Obama關聯的某個結點,這樣就可以到知識庫裏以Obama為半徑,把跟它有關的詞全部挖出來,然後係統要算相似度,相似度算的時候有一種辦法,是把這個知識圖譜的某一個知識單元用自然語言表征出來,也可以用詞嵌入做一個多維向量表示。這時候做一個Ranker跟當前的問題算一個距離,距離近的就是它的答案。我們也將這些技術運用在了微軟小冰裏,比如小冰回答問題,跟你聊天等等。我們還做了京東商城裏的導購。
怎麼在京東商城裏通過對話過程來實行導購呢?實際上就是對用戶輸入的話,檢測意圖是什麼,如果檢測不到,係統就判斷可能是聊天,然後通過聊天的引擎進行溝通。如果檢測到意圖,比如知道用戶是要訂旅館,那麼就有對應的訂旅館的對話狀態表記錄目前進行的狀態及要填充哪些信息。
係統知道要填什麼信息的時候,就會生成相應的問題讓用戶回答,用戶回答完之後係統再把信息抽取過來填充到這個表裏,直到所有的信息全部填充完畢,就完成了這個任務的對話過程。
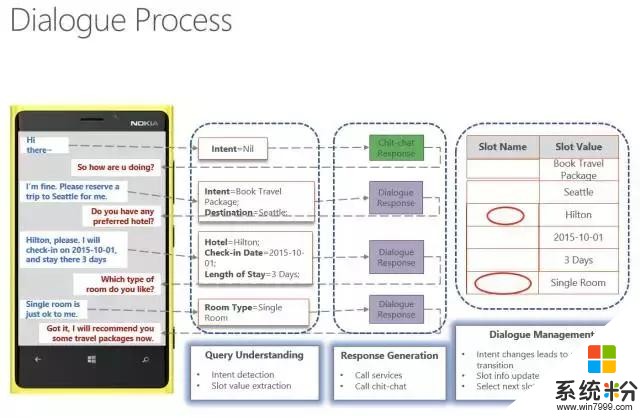
這裏就涉及到了對問題的理解,問題中有哪些信息要抓取出來,還有對話管理,比如狀態的轉移,slot的填充或者更改,選擇一個新的slot開始對話,以及如果要決定填充哪個slot的時候,怎麼生成對話可以讓用戶很自然地回答這個問題,從而獲得係統所需要的信息。
今天簡單的給大家介紹了三個關鍵技術,這三個技術每個都不容易,我們現在雖然取得了一定的成績,但還有很多問題需要解決,也期待大家運用自己的智慧把這個領域推進一步,更好的解決難題。
在未來有三件大事非常重要,第一個就是如何更好地來為上下文或者是多輪對話建模,目前還是用比較粗糙的信息表示方法來做,沒有精確的來斷定前文出現了哪些具體的信息,將來我們可以用信息抽取的方法把這些信息記錄下來,引導未來的對話。
第二個,個性化的信息如何指導生成個性化的回複。最後,現在的回複也是千篇一律,大人、小孩、男孩、女孩,可能都是一樣的,但人們在實際對話中麵對不同的人群是不一樣的,如何能夠對回複的風格進行自動調整,使對話更加豐富多彩,這也是目前的一個挑戰。




















