
時間:2017-09-25 來源:互聯網 瀏覽量:
近日,斯坦福大學NLP小組發推特稱,微軟提交了最新一次SQuAD的測試成績,再次奪回得了該數據集測試榜單第一的位置。
自然語音理解長期以來被譽為“人工智能皇冠上的明珠”,讓機器學會閱讀和理解人類語言一直是研究者和業界關注的對象,今年以來更是受到了極大的追捧,熱度不減。
由斯坦福大學李飛飛教授發起的ImagNet,是目前世界上圖像識別最大的數據庫,試圖讓冰冷的機器讀懂照片背後的故事。而在斯坦福大學自然語言組發起的挑戰賽SQuAD,行業內公認的機器閱讀理解標準水平測試,也是該領域的頂級賽事,更是被譽為機器閱讀理解界的”ImageNet”。
參賽者來自全球學術界和產業界的研究團隊,包括微軟亞洲研究院、艾倫研究院、IBM、Salesforce、Facebook、穀歌以及卡內基·梅隆大學、斯坦福大學等知名企業研究機構和高校,賽事對自然語言理解領域的學術進步和人才選拔都起到重要作用。
SQuAD比賽規則是怎樣?對於機器的閱讀理解,如何作答和評判?
SQuAD挑戰賽通過眾包的方式構建了一個大規模的機器閱讀理解數據集(包含10萬個問題),就是將一篇幾百詞左右的短文給人工標注者閱讀,讓標注人員提出最多5個基於文章內容的問題並提供正確答案;短文原文則來源於500多篇維基百科文章。
參賽者提交的係統模型在閱讀完數據集中的一篇短文之後,回答若幹個基於文章內容的問題,然後與人工標注的答案進行比對,得出精確匹配(Exact Match)和模糊匹配(F1-score)的結果。得益於SQuAD提供的大規模高質量的訓練數據以及層出不窮的模型,該挑戰賽的榜單一次又一次刷新。
以下是最新排名,MSRA位居第一:
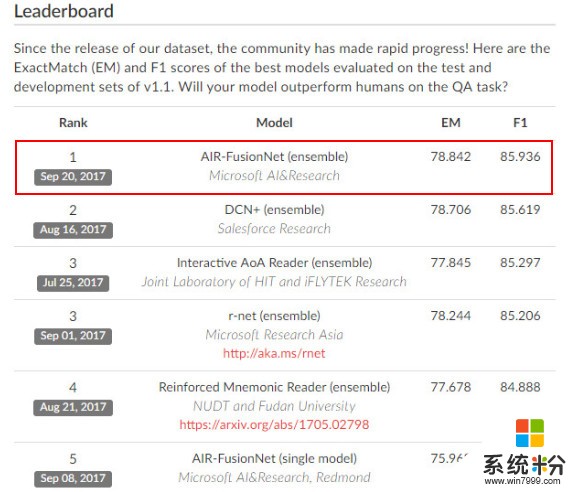
微軟亞洲研究院常務副院長、NLP小組組長周明曾表示,從這個數據集成立之初MSRA就開始有所關注,這個數據集的規則是需要不停刷新排名,隔一段時間就要提交最新的測試成績。MSAR連續多次位居數據集排名第一。
“雖然偶爾有一兩天其它團隊超過了我們的成績,但我們也有最新的算法能夠很快地進行更新,並取得更好的成績,對於這一點我們的團隊始終十分自信。”機器閱讀理解研究的主要負責人、微軟亞洲研究院自然語言計算研究組主管研究員韋福如曾這樣說。
此外,國內業界代表科大訊飛也在關注並參與該數據集的比賽,7月份科大訊飛與哈工大聯合實驗室(HFL)提交的係統模型在測試中奪得第一名,同樣實力不俗。足以可見自然語言處理領域競爭十分激烈。
自然語言處理領域一直是實現人機交互、人工智能的重要技術基石,機器閱讀理解正是這一領域的一個研究焦點。如今異常火熱的智能語音助手,最關鍵的除了“聽清”就是“聽懂”,語音技術在不斷完善,而自然語言理解的進展則相對較為緩慢。萬裏長征可謂剛剛起步,NLP產業界和學術界均任重道遠。




















