
時間:2017-08-23 來源:互聯網 瀏覽量:
選自微軟博客
機器之心編譯
參與:路雪、黃小天、蔣思源
近日在 Hot Chips 2017 上,微軟團隊推出了一個新的深度學習加速平台,其代號為腦波計劃(Project Brainwave),機器之心將簡要介紹該計劃。腦波計劃在深度學習模型雲服務方麵實現了性能與靈活性的巨大提升。微軟專為實時人工智能設計了該係統,它可以超低延遲地處理接收到的請求。雲基礎架構也可以處理實時數據流,如搜索查詢、視頻、傳感器流,或者與用戶的交互,因此實時 AI 變的越發重要。
近來,FPGA 對深度學習的訓練和應用變得越來越重要,因為 FPGA:
性能:低批量大小上的優秀推理性能、在現代 DNN 上服務的超低延遲、>10X 且比 CPU 和 GPU 更低、在單一 DNN 服務中擴展到很多 FPGA。
靈活性:FPGA 十分適合適應快速發展的 ML、CNN、LSTM、MLP、強化學習、特征提取、決策樹等、推理優化的數值精度、利用稀疏性、更大更快模型的深度壓縮。
規模:微軟在 FPGA 上擁有全球最大的雲計算投資、AI 總體能力的多實例操作、腦波計劃運行在微軟的規模基礎設施上。
所以我們發布了腦波計劃(Project BrainWave),一個可擴展的、支持 FPGA 的 DNN 服務平台,它有三個特性:
快速:小批量 DNN 模型有超低延遲、高吞吐量服務
靈活:適應性數值精度與自定義運算符
友好:CNTK/Caffe/TF/等的交鑰匙(turnkey)部署
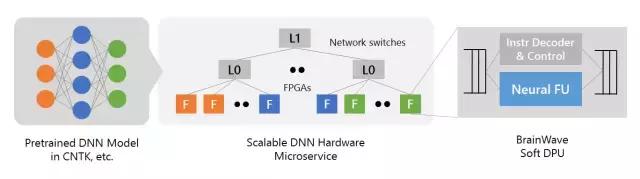
腦波計劃
腦波計劃係統的主要內容包括以下三個層麵:
一個高性能的分布式係統架構;
一個集成在 FPGA 的硬件 DNN 引擎;
一個用於已訓練模型的低摩擦(low-friction)部署的編譯器和運行時間。
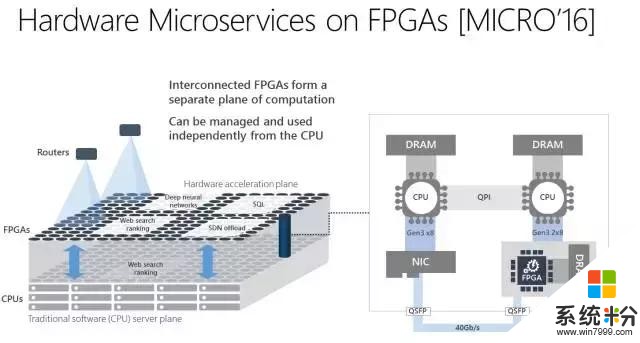
首先,腦波計劃利用了微軟這些年一直部署的大量 FPGA 基礎架構。通過把高性能 FPGA 直接連接到我們的數據中心網絡,我們可以把 DNN 作為硬件微服務,其中 DNN 可以映射到一個遠程 FPGA 池,並被循環中沒有軟件的服務器調用。這個係統架構不僅可以降低延遲(因為 CPU 並不需要處理傳入的請求),還可以允許非常高的吞吐量,並且 FPGA 處理請求可以如網絡的流式傳輸一樣快。
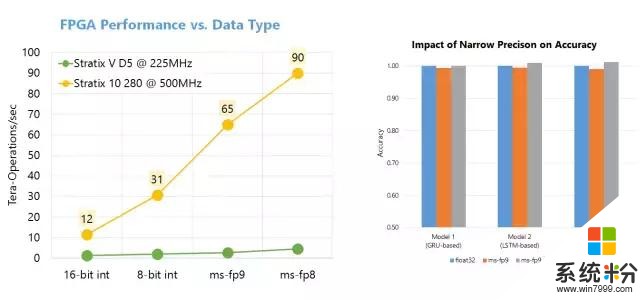
第二,腦波計劃使用了一個強大的在商業化可用的 FPGA 上合成的「軟」DNN 處理單元(DPU)。大量的公司,包括大型公司和一大批初創公司,正在構造硬化的 DPU。盡管其中一些芯片具有高峰值性能,但它們必須在設計時選擇運算符和數據類型,這限製了其靈活性。腦波計劃采取了另一種方法,提供了一個可在一係列數據類型上縮放的設計。這個設計結合了 FPGA 上的 ASIC 數字信號處理模塊和可合成的邏輯,以提供一個更大更優化數量的功能單元。這一方法以兩種方式利用了 FPGA 的靈活性。首先,我們已經定義了高度自定義、窄精度(narrow-precision)的數據類型,無需損失模型精度即可提升性能。第二,我們可以把研究創新快速整合進硬件平台(通常是數周時間),這在快速移動的空間中至關重要。因此,我們取得了可媲美於甚至超過很多硬編碼(hard-coded)DPU 芯片的性能,並在今天兌現了性能方麵的承諾。
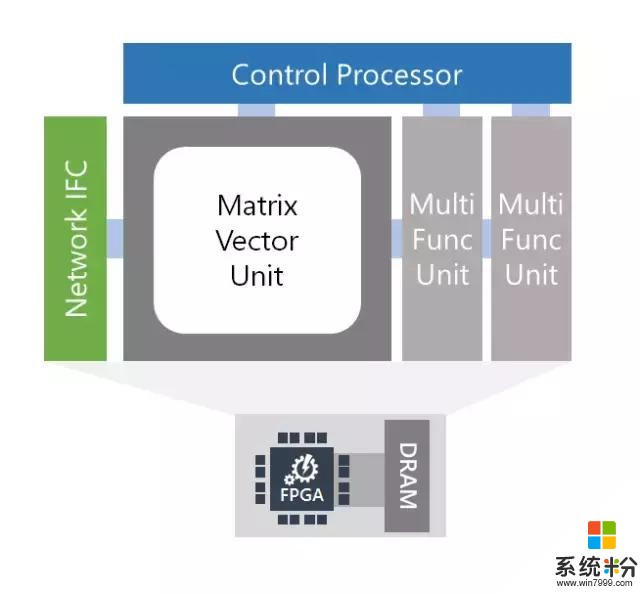
腦波軟 DPU 架構
核心特征
單線程 C 編程模型(沒有 RTL)
具有專門指令的 ISA:密集矩陣乘法、卷積、非線性激勵值、向量操作、嵌入
獨有的可參數化的窄精度格式,包含在 float16 接口中
可參數化的微架構,並且擴展到大型 FPGA(~1M ALMs)
硬件微服務完全整合(附設網絡)
用於 CPU 主機和 FPGA 的 P2P 協議
易於擴展帶有自定義運算符的 ISA
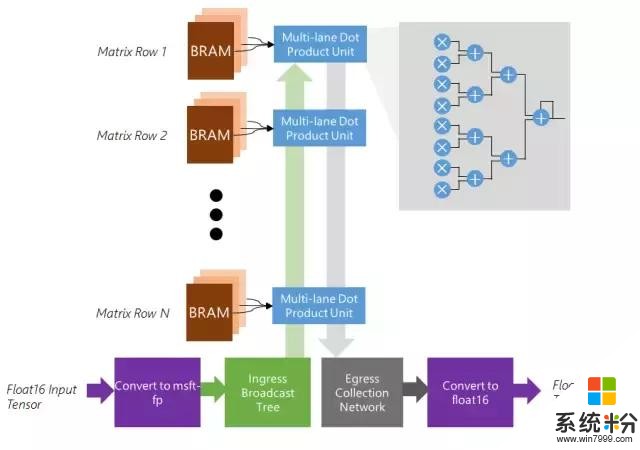
矩陣向量單元
特征
優化以適用於批量為 1 的矩陣向量乘法
矩陣逐行分布在 BRAM 的 1K-10K 個內存塊上,最高 20 TB/s
可擴展以使用芯片上所有可用的 BRAM、DSP 和軟邏輯(soft logic)
將 float 16 權重和激活值原位轉換成內部格式
將密集的點積單元高效映射到軟邏輯和 DSP
第三,腦波計劃納入了一款支持多個流行深度學習框架的軟件棧(software stack)。我們已經支持微軟 Cognitive Toolkit 和穀歌的 Tensorflow,並且計劃支持其他框架。我們已經定義了一個基於圖的中間表示(intermediate representation),我們將在流行框架中訓練的模型轉換成中間表示,然後再將其編譯成我們的高性能基礎架構。

編譯器 & 運行時:框架中立的聯合編譯器和運行時,用於將預訓練的 DNN 模型編譯至軟 DPU
架構:自適應 ISA,用於窄精度 DNN 接口;靈活、可擴展,可支持快速變化的人工智能算法
微架構:BrainWave Soft DPU 微架構;高度優化,適用於窄精度和小批量
擴展一致性:在 FPGA 芯片內存中一致的模型參數;可在多個 FPGA 中擴展以支持大模型
英特爾 FPGA 上的 HW 微服務:英特爾 FPGA 大規模部署,帶有硬件微服務 [MICRO'16]
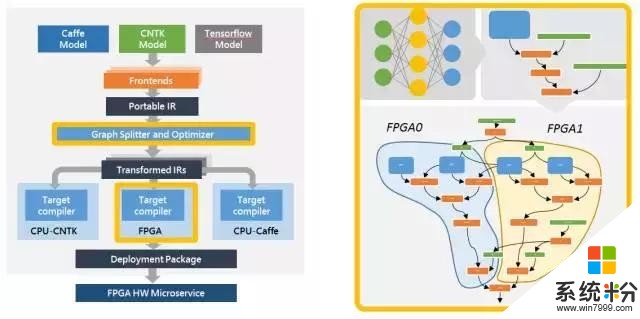
腦波編譯器和運行時
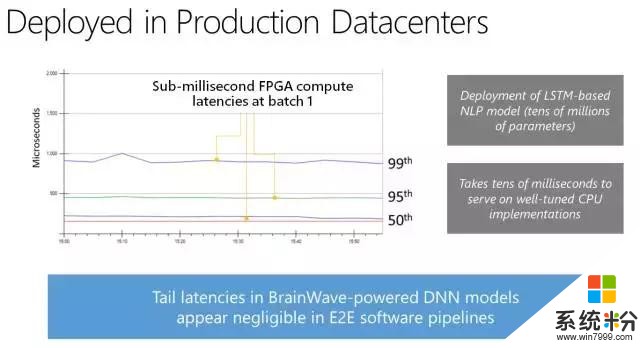
我們構建該係統,以展示其在多個複雜模型中的高性能,同時無須執行批處理(batch-free execution)。公司和研究人員構建 DNN 加速器通常使用卷積神經網絡(CNN)展示性能 demo。CNN 是計算密集型,因此它取得高性能相對比較簡單。那些結果通常無法代表其他域的更複雜模型上的性能,如自然語言處理中的 LSTM 或 GRU。DNN 加速器經常用來提升性能的另一項技術是用高度批處理運行深度神經網絡。盡管該技術對基於吞吐量的架構和訓練等離線場景有效,但它對實時人工智能的效果沒有那麼好。使用大批量,一個批次中的第一個查詢必須等待該批次中的其他查詢完成。我們的係統適用於實時人工智能,無須使用批處理來降低吞吐量,即可處理複雜、內存密集型的模型,如 LSTM。
即使在早期 Stratix 10 silicon 中,移植的 Brainwave 係統可運行大型 GRU 模型,它們可能比不使用批處理的 ResNet-50 還要大 5 倍,同時該係統也實現了創紀錄的性能。該演示使用的是微軟定製的 8 位浮點格式(「ms-fp8」),它在很多模型中都不會遭受到平均準確度損失。我們展示了 Stratix 10 在大型 GRU 模型中保持了 39.5 Teraflops,並且每一個請求的運行時間都在毫秒內。在性能方麵,腦波架構每一個周期保持了超過 130000 個計算操作,並且由每 10 個周期發布的宏指令驅動。腦波在 Stratix 10 上運行,實現了實時 AI 的強大性能,特別是在非常具有挑戰性的模型上。我們將在接下來的幾個季度調整係統,希望它能夠實現顯著的性能提升。
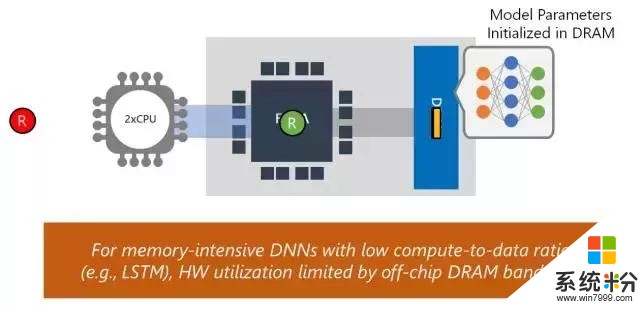
傳統的加速方法:Local Offload and Streaming
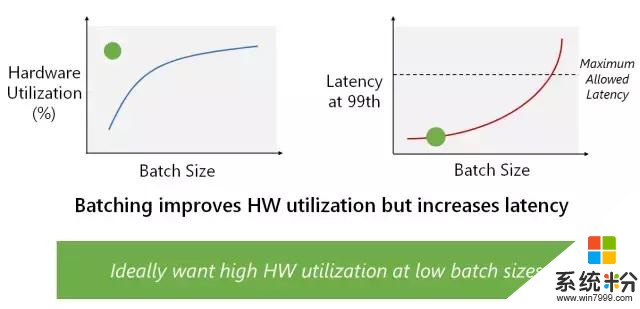
通過批處理提升硬件效用
FPGA 上的窄精度接口
結語
我們正將這種強大的實時 AI 係統介紹給大家,特別是 Azure 平台的用戶。這樣,我們的用戶才能從腦波計劃中直接獲益,並間接補充了訪問我們的服務的路徑,如 Bing。在不久的未來,我們將具體說明 Azure 用戶可以怎樣使用該平台運行他們複雜的深度學習模型,並達到創紀錄的性能。因為腦波計劃係統是大規模集成係統並對我們用戶是可用的,所以 Microsoft Azure 在實時人工智能上有行業領先的性能。




















