
時間:2017-08-21 來源:互聯網 瀏覽量:
編者按:語音識別是眾多研究團隊和企業正在努力攻克的技術高地,有關識別準確率的競爭和比較從未停止。去年,微軟率先實現語音識別係統5.9%的低錯誤率,在Switchboard對話語音識別任務中已經達到人類對等的水平。
就在昨天,微軟語音和對話研究團隊負責人黃學東宣布微軟語音識別係統錯誤率進一步降低到5.1%,此次突破堪稱是語音識別行業新的裏程碑,準確率超過專業速記員。本文譯自“Microsoft researchers achieve new conversational speech recognition milestone”,點擊閱讀原文查看論文。
8月20日,微軟語音和對話研究團隊負責人黃學東宣布微軟語音識別係統繼微軟對話語音識別技術達至人類專業水平,開啟人工智能新征程之後再次取得重大突破,錯誤率由5.9%進一步降低到5.1%,可與專業速記員比肩。此次突破大幅刷新原先記錄,並在語音識別行業樹立新的裏程碑。
在微軟轉錄係統達到5.9%的錯誤率之後,其他研究人員在此基礎上分別進行研究,采用了更多參與的多轉錄程序,成功在語音識別準確性道路上更進一步。
這兩次研究轉錄的都是Switchboard語料庫中的錄音,Switchboard是一個電話通話錄音語料庫,自上世紀90年代以來一直被研究人員作為測試語音識別係統的樣本。語音識別測試任務包括對陌生人對話交流中的不同話題,比如體育和政治方麵的討論,進行從語音到文字的轉錄。
研究人員通過改進微軟語音識別係統中基於神經網絡的聽覺和語言模型,在去年基礎上降低了大約12%的出錯率,同時引入了CNN-BLSTM(convolutional neural network combined with bidirectional long-short-term memory,帶有雙向LSTM的卷積神經網絡)模型,用於提升語音建模的效果。並且,係統中以前就在使用的從多個語音模型進行綜合預測的方法,如今在幀/句音級別和單詞級別下都可以發揮效果。
除此以外,研究人員還對整個對話過程進行曆史記錄分析,預測接下來可能會發生的事情,進一步加強識別器的語言模型,使其能夠有效適應對話話題和語境的快速轉變。
微軟認知工具包Microsoft Cognitive Toolkit 2.1(CNTK)在研究過程中表現突出,研究人員充分利用CNTK探索模型架構和優化模型的超參數。此外,微軟對雲計算基礎設施(特別是Azure GPU)的投資,也幫助提升了訓練模型、測試新想法的效果和速度。
實現識別準確率上的“人類對等”是語音識別領域過去25年來一直奮力追求的研究目標,微軟始終堅持深耕語音識別,並力爭將新技術最快、最好地運用到Cortana、Presentation Translator、Microsoft Cognitive Services等微軟產品和服務中,讓用戶能夠親身體驗新技術的魅力。微軟的研究團隊非常高興可以看到每天有數百萬的用戶在使用這些產品,未來將更加努力,創造出更具突破性的工作成果。
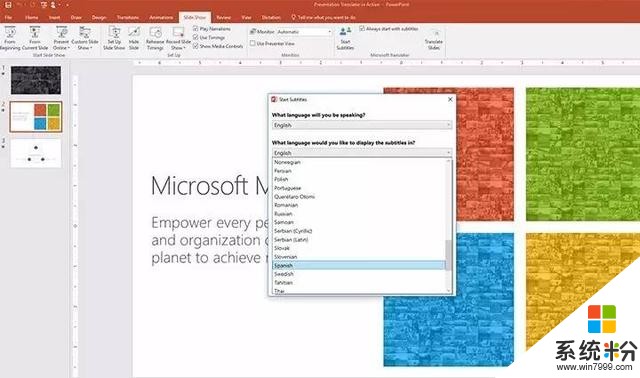
Presentation Translator:利用語音識別實現多語言觀眾實時翻譯演示文稿
在語音識別領域,業界和學術界有許多研究團隊都有重大進展,微軟研究團隊在行業的整體發展下同樣獲益良多。盡管目前在Switchboard 語音識別任務中實現了5.1%的低錯誤率,事實上語音研究領域仍然挑戰重重,例如嘈雜環境、錄音距離較遠場景下的語音識別,方言識別,有限訓練數據條件下的語音識別或較少人使用的語言的語音識別,這些距離達到人類相近水平還相差甚遠。而且,計算機學會將語音轉換為文字並非語音識別的終點,讓計算機能夠理解其中的含義和目的才是道阻且長。從語音識別到話語理解,將會是語音相關技術的下一個重要前沿。
你也許還想看:
,共建交流平台。來稿請寄:msraai@microsoft.com。
 微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。
微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。




















