
時間:2017-08-09 來源:互聯網 瀏覽量:
IBM宣布進一步增強其PowerAI軟件平台,旨在促進AI模型在目前最快的GPU上的實際擴展。IBM利用新的分布式深度學習(DLL)庫擴展到256個GPU,IBM報告表示,打破了之前由Google和Facebook在兩個著名的圖像識別工作負載上所創造的記錄。

Moor Insights&Strategy總裁兼首席分析師Patrick Moorhead表示:“這是過去六個月來所有深入學習行業公告中所見的最大突破之一。 “有趣的是,它來自IBM,而不是像Google這樣的互聯網巨頭,這意味著企業可以使用OpenPower硬件和PowerAI軟件,甚至通過雲提供商Nimbix進行首次使用。”
該公告的核心是由IBM Research科學家開發的一種新的通信算法,並封裝為通信庫,稱為PowerAI DDL。作為PowerAI 4.0版本一部分的Power用戶,現在可以使用庫和API作為技術預覽。改進多節點通信的其他努力往往隻集中在一個單一的深度學習框架上,因此值得注意的是,PowerAI DDL被集成到多個框架中。目前,TensorFlow,Caffe和Torch計劃添加對Chainer的支持。
沒有使用Power係統的用戶可以通過Nimbix Power Cloud訪問新的PowerAI軟件。
Nimbix首席執行官史蒂夫·希伯特(Steve Hebert)說:“像超級計算機和大型企業一樣,Nimbix一直在努力將分布式能力建立在深入的學習框架中,而正如IBM公布的那樣,事實證明這是一個完整的多框架的軟件解決方案。
“這是真正的HPC技術,”他繼續說。 “它采用傳統HPC的一些最好的軟件組件,並與AI和深度學習結合,以便能夠提供該解決方案。我們的平台非常適合在HPC意義上進行擴展,對於能夠對問題大小進行線性縮放的代碼,它的延遲非常低。這意味著深入學習首次開始解決企業級的深度學習問題。使之成為可用於任何公司或消費者的大型超級計算機,而不是隻有穀歌,百度這樣的互聯網企業,從而普惠於民。
DDL中的多環通信算法(參見IBM研究論文),提供延遲和帶寬之間的良好折衷,並適應各種網絡配置。完整的方法是專有的,但本文的第4部分提供了相當詳細的庫和算法的描述。
目前的PowerAI DDL實現基於Spectrum MPI。研究人員指出,MPI提供了許多需要的設施,從調度流程到基本的通信原語,在便攜式,高效和成熟的軟件生態係統中,研究人員提到,“如果需要,可以在沒有MPI的情況下實現核心API”。
為了評估其新的PowerAI分布式深度學習庫的性能,IBM使用64台IBM“Minsky”Power8 SL822LC服務器的集群進行了兩次實驗,每台服務器配備了通過Nvidia的高速NVLink互連連接的四個Nvidia Tesla P100 GPU。係統占用四個機架(每個16個節點),通過InfiniBand連接。
IBM報告說,其Power硬件和軟件的組合為使用Caffe的Resnet-50神經網絡提供了比Facebook最近通過Caffe2深度學習軟件實現的更好的通信開銷。DDL軟件使用Caffe在其256-GPU Minsky集群上實現了95%的效率,而Facebook使用Caffe2框架在256個NVIDIA P100 GPU加速的DGX-1集群上實現了89%的擴展效率。可能影響比較的實施差異,例如Caffe與Caffe2,將在IBM Research論文中討論。
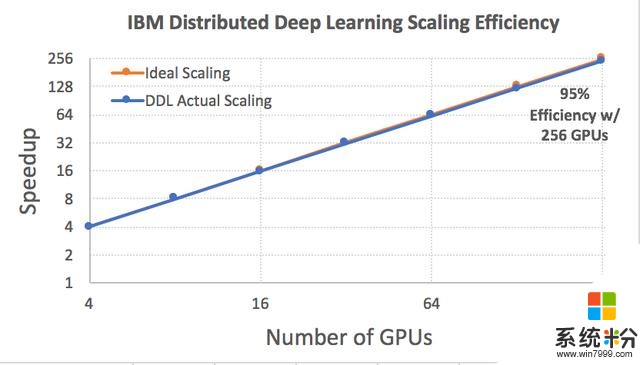
使用Caffe與PowerAI DLL縮放結果,以使用總共256個Nvidia P100 GPU的64個Power8服務器上的ImageNet-1K數據集訓練ResNet-50模型(來源:IBM)
在第二次基準測試中,IBM針對在非常大的數據集上訓練的Resnet-101神經網絡(750萬圖像,部分ImageNet-22k集)報告了新的圖像識別精度為33.8%。微軟在2014年發布的以前的記錄顯示了29.8%的準確性。
IBM研究員Hillery Hunter觀察到,相比過去典型改進不到1%,準確度提高了4%,這是一個巨大的飛躍。
此外,借助IBM的分布式深度學習方法,ResNet-101神經網絡模型在短短七個小時內進行了培訓,相比之下,微軟花了10天的時間來訓練同一模型。IBM報告提到縮放效率為88%。
IBM認知係統業務部門的AI和HPC副總裁Sumit Gupta認為,提高速度和準確性將對企業客戶帶來巨大的利益。他說:“如果訓練一個AI模型需要16天的時間,那麼這個挑戰的一部分就是不實際的。” 當你在一家大型企業工作時,隻能擁有一些數據科學家,而你真的需要使其具有生產力,從而將16天降至7小時,從而使數據科學家的工作效率更高。”
某些應用程序特別受到時間限製。市場分析師Rob Enderle說:“在安全,軍事,欺詐保護和自動駕駛中,你經常隻需要幾分鍾或幾秒的時間來訓練係統來應對新的漏洞或問題,但目前通常需要幾天時間。這有效地減少了幾天到幾個小時,並提供了一個潛在的路線圖,以達到幾分鍾甚至幾秒鍾。像這樣的場景讓購買Power Systems來加速深入學習更容易。”
用例方麵。推薦引擎,信用卡欺詐檢測,抵押分析,零售客戶的加售/交叉銷售,購物體驗分析都得到了IBM客戶的極大關注。




















