時間:2017-08-02 來源:互聯網 瀏覽量:
對於人類來說,通過閱讀理解獲取知識,通過對海量數據的分析了解世界是最平常不過的事情。但對於一個智能係統來說,要實現這個功能卻非常困難。攻克這個困難,讓閱讀理解成為智能係統的標配也成為了各家科技公司研究開發的焦點之一。
據澎湃新聞8月2日報道,近日,科大訊飛與哈工大聯合實驗室(HFL)提交的係統模型,在斯坦福大學發起的SQuAD(Stanford Question Answering Dataset)挑戰賽當中取得了第一名的成績。這也是中國本土研究機構首次取得該賽事的榜首。
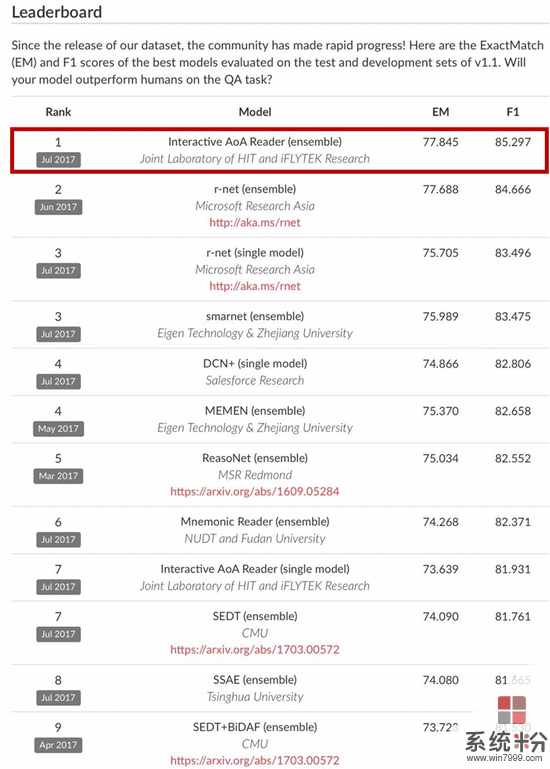
SQuAD挑戰賽最新成績榜單:
科大訊飛AI研究院副院長、哈工大訊飛聯合實驗室副主任王士進告訴澎湃新聞:“對機器來說,記憶海量知識並進行淺層推理,是一個相對較容易的工作,之前很多相關的工作證明了機器不比人類差,但精準的理解並實現推理,是一個相對更難的任務,為此目前全球最優秀的AI團隊都在進行類似的研究。”
據王士進介紹,2015年5月,哈工大訊飛聯合實驗室開始啟動研究機器閱讀理解技術,是國內較早啟動該項研究的團隊。隨後該團隊又啟動了內部項目 “六齡童閱讀理解”,期待機器在認知智能上達到六歲兒童的智力,希望通過顛覆式的技術創新,做到機器看文章能夠做出理解、推理和求解。
從眾多外國研究機構手中拿下第一名
據楚北網報道,SQuAD挑戰賽是行業內公認的機器閱讀理解標準水平測試,也是該領域的頂級賽事,被譽為機器閱讀理解界的ImageNet(圖像識別領域的頂級賽事)。
參賽者來自全球學術界和產業界的研究團隊,包括微軟亞洲研究院、艾倫研究院、IBM、Salesforce、Facebook、穀歌以及卡內基·梅隆大學、斯坦福大學等知名企業研究機構和高校,賽事對自然語言理解的進步有重要的推動作用。
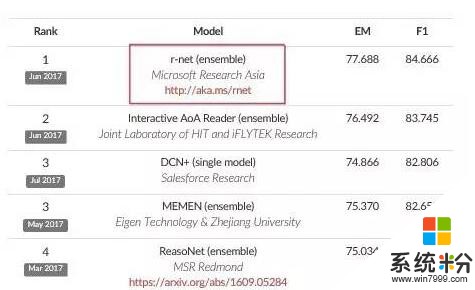
在科大訊飛今年獲得第一名之前,微軟亞洲研究院的自然語言計算研究組持續穩居榜首。
SQuAD挑戰賽通過眾包的方式構建了一個大規模的機器閱讀理解數據集(包含10萬個問題),將一篇幾百詞左右的短文給人工標注者閱讀,讓標注人員提出最多5個基於文章內容的問題並提供正確答案,短文原文則來源於500多篇維基百科文章。參賽者提交的係統模型在閱讀完數據集中的一篇短文之後,回答若幹個基於文章內容的問題,然後與人工標注的答案進行比對,得出精確匹配(Exact Match)和模糊匹配(F1-score)的結果。
SQuAD向參賽者提供訓練集用於模型訓練,以及一個規模較小的數據集作為開發集,用於模型的調優和選型。與此同時,SQuAD還提供了一個開放平台供參賽者提交自己的算法,由SQuAD官方利用隱藏的測試集對參賽係統進行評分,並在SQuAD官方確認後將相關結果更新到官網上。
得益於SQuAD提供的大規模高質量的訓練數據以及層出不窮的模型,該挑戰賽的榜單一次又一次的刷新。目前,根據SQuAD此次公布的結果,科大訊飛與哈工大聯合實驗室提交的係統模型取得了精確匹配77.845%和模糊匹配85.297%的成績,位列世界第一。
如何奪取全球第一
在SQuAD官網的成績榜單上,可以看到科大訊飛與哈工大聯合實驗室提交的模型名為“Interactive AoA Reader”,這是訊飛經過不斷摸索之後提出的“基於交互式層疊注意力模型”(Interactive Attention-over-Attention Model)。正是這個與眾不同的模型,讓科大訊飛在全球自然語言理解研究領域脫穎而出躍居頭名。

要解決機器閱讀理解的問題,傳統的自然語言處理(NLP)方式是采用分拆任務的方法將其分成問題分析、篇章分析、關鍵句抽取等一些步驟,隻是這種方法容易造成級聯誤差的積累,很難得到很好的效果。
為了解決這種誤差,科學家們又提出了完全端到端的神經網絡建模。采用神經網絡的方法能夠,消除了分步驟產生的級聯誤差;通過大量的訓練數據學習到泛化的知識表示,對篇章和問題從語義層麵上高度抽象化。
科大訊飛此次提交給SQuAD的模型,也采用了端到端的神經網絡模型,但把精力更多放在如何能夠模擬人類在做閱讀理解問題時的一些方法。
訊飛提出的基於交互式層疊注意力模型,主要思想是根據給定的問題對篇章進行多次的過濾,同時根據已經被過濾的文章進一步篩選出問題中的關鍵提問點。這樣“交互式”地逐步精確答案的範圍,與其他參賽者的做法不太相同,最終收獲了令人矚目的成績。
王士進告訴澎湃新聞,實際上在此次挑戰賽之前,哈工大訊飛實驗室在Google Deepmind、Facebook等閱讀理解測試集上都取得過最好成績。但應用SQuAD公開測試集上表現並不理想,於是他們在原創技術上根據要求進行了大幅改進。
“因為SQuAD測試是通過眾包的方式構建了一個大規模的機器閱讀理解數據集,答案並不隻是單個詞,因此直接應用我們在完形填空式問題上使用的AoA Reader等原創技術效果並不理想。後來我們針對此類問題對AoA Reader做了大幅的改進,主要思想是根據給定的問題對篇章進行多次的過濾,同時根據已經被過濾的文章進一步篩選出問題中的關鍵提問點,同時我們利用了多個不同類型的模型進行融合,最終在效果上有了明顯的提升。”王士進說。
機器學會閱讀理解的意義
科大訊飛認為,人工智能的發展主要分為運算智能、感知智能和認知智能。機器在運算智能上有極大的優勢,在感知智能上也已經取得了很大的進展,例如語音識別、語音合成、圖像識別、機器翻譯等。而在認知智能方麵,自然語言處理一直是實現人機交互、人工智能的重要技術基石,機器閱讀理解正是這一領域的一個研究焦點。同樣,讓機器實現“能聽會說”到“能理解會思考”,也一直是科大訊飛所肩負的使命和方向。
早在2014年,科大訊飛與哈爾濱工業大學就聯合成立了聯合實驗室,作為“訊飛超腦”計劃的核心研發團隊之一,聯合實驗室致力於在語言認知計算領域進行長期、深入的技術創新,重點突破深層語義理解、邏輯推理決策、自主學習進化等認知智能關鍵技術,並圍繞教育學習、人機語音交互、信息安全等領域實現科研成果的規模化應用。
據科大訊飛介紹,哈工大訊飛聯合實驗室不僅能讓機器在閱讀理解比賽中“考出高分”,還能讓機器給考卷的主觀題評分。以語文考試的作文為例,在閱卷之前老師們先置一套通用的打分標準,包括字跡工整度、詞彙豐富性、句子通順度、文采、篇章結構、立意等多個層次,研究人員讓機器來學習這套方案後進行閱卷。這每一項標準背後都需要精密複雜的技術支持,比如手寫識別、主題模型、人工神經網絡等。
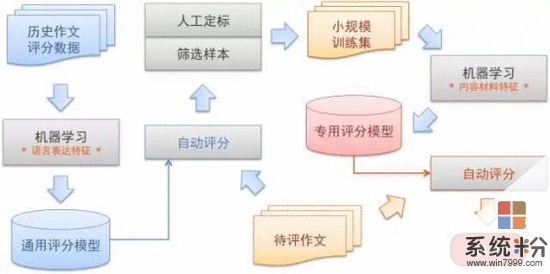
目前,科大訊飛的全學科閱卷技術在四六級、部分省份的高考、中考等大規模考試中進行了試點驗證,驗證結果表明計算機評分結果已經達到了現場閱卷老師的水平,滿足大規模考試的需要。這項技術應用到正式考試中,可以輔助人工閱卷,減少人員投入,降低人工閱卷中疲勞、情緒等因素的影響,進一步提升閱卷效率和準確性。
此前,哈工大訊飛聯合實驗室曾先後在Google DeepMind閱讀理解公開數據測試集、Facebook閱讀理解公開數據測試集取得世界最好成績,本次在SQuAD測試集再獲全球最佳,包攬了機器閱讀理解權威測試集的“大滿貫”。
機器閱讀理解技術擁有廣闊的應用場景,例如在產品的精準問答、開放域的問答上都會起到有力的支撐作用,訊飛也在不斷探索機器閱讀理解技術的應用落地。
但對於機器閱讀理解的“能理解會思考”的終極目標來說,現在還隻是萬裏長征的開始,對自然語言的更深層次的歸納、總結、推理,一定是未來機器閱讀理解不可缺少的部分。
而自2014年以來,科大訊飛就提出了“訊飛超腦”計劃,其中的目標之一就是要讓機器人考上重點大學。這次獲得成績也是為推進這一計劃的努力之一。