
時間:2017-07-27 來源:互聯網 瀏覽量:
李根 編譯整理
量子位 出品 | 公眾號 QbitAI
我們先把“機器滅絕人類”的探討放一放,因為還有很多“看起來簡單做起來難”的問題未得到解決,比如閱讀理解。
對於人類來說,閱讀理解是一項最基本的認知技能,並且人類很小的時候,就能在閱讀完某一篇文章後,回答其中心思想和關鍵細節。
但這對AI並不簡單。目前讓機器實現完全的閱讀理解,仍舊是一個不小的挑戰,不過這又是打造通用AI而必須完成的目標。
實際上,機器閱讀理解(MRC)對於解決很多現實問題和場景,都是非常有幫助的。比如用戶服務、谘詢、建議、問答對話和客戶關係管理等,更具體一點,如果機器閱讀更好用,就能幫助醫生在數以千計的文件中快速找到重要信息——時間的價值想必在救死扶傷的行業中不言自明。
當然,機器閱讀能力的提升,也會影響到每個用戶的日常。
比如在搜索中,如果給出的是一個精確的答案,而不是一個內有答案的長篇網頁的URL,可能用戶體驗會好太多。另外,有一些冷門或特定領域的文章中的特定知識,僅依靠現在算法獲得的搜索數據,或許非常有限——機器閱讀理解能力的提升將為此帶來質的改變。
值得一提的是,如果你是工程師/開發者,現在也能通過最新的研究方法,打造一個機器閱讀理解方麵的AI了。
這一進步得益於微軟AI研究院的最新成果。Po-Sen Huang,Xiaodong He和來自斯坦福大學的David Golub,公布了一種機器閱讀理解解決方案:運用遷移學習算法解決機器閱讀理解中的問題,運用真實數據,解決現實問題——而不是理論意義的算法模型。
說到這,如果你對機器閱讀理解有過嚐試,可能就會眼前一亮了。
因為現在最先進的機器閱讀係統,都基於有監督的訓練數據,用來訓練這些係統的數據樣例,不僅包含文章本身,還有手動標注出來的文章相關問題和答案。深度學習MRC模型通過這些標注數據學習讀懂問題,並進一步基於文章推斷答案,這中間涉及多個推理和推理步驟。
然而,在很多垂直領域,這種監督訓練數據並不存在。比如我們想要通過一個新的機器閱讀係統來幫醫生找關於新疾病的重要信息,可能會有多個文檔可用,但並沒有關於文章的手動標注問題,以及相對應的答案。這不是一個小問題。
如果需要為每一個不同的新疾病建立單獨的MRC係統,而且所有迅速增加的文獻都要納入其中,關於標注和訓練數據帶來的工作量,就會指數級增加。
那是否可以將現有的MRC係統轉移到之前沒有訓練數據的新領域呢?這就是此次微軟AI研究團隊的成果。
微軟AI團隊開發了一種名為“兩階段綜合網絡”的模型,也稱SynNet。這個模型中,SynNet先基於一個領域的可用訓練數據,學會閱讀理解該文章中潛在的知識點。第二階段,SynNet模型在文章中基於上下文,針對第一階段的“知識點”形成自然語言問題。
於是一旦訓練完成,SynNet就可以應用到新領域,閱讀新文檔,再生成潛在問題和對應文本的答案。然後SynNet就能不斷形成必要的訓練數據,用來訓練該領域的MRC係統。
在這個SynNet模型中,生成問答的過程可以被分解稱兩個步驟:
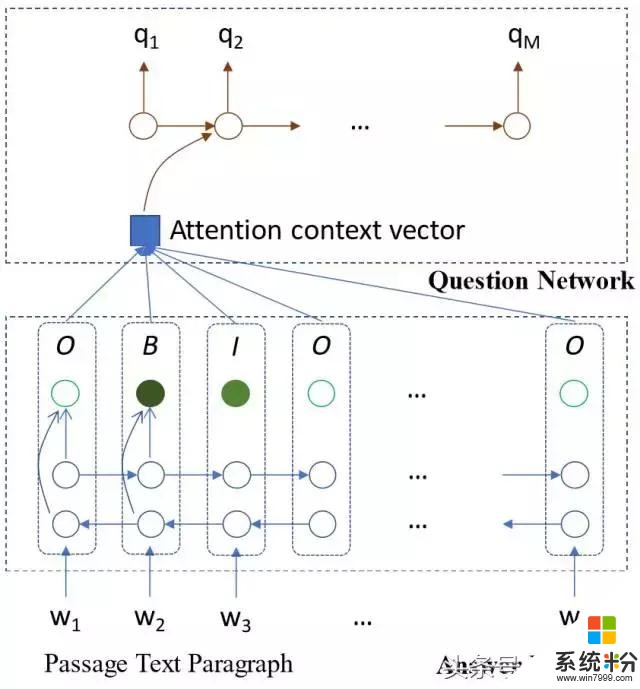
一、以段落為單位,生成答案,背後原理是使用雙向長短期記憶(LSTM)來預測輸入段落的內外起始點(inside-outside beginning, IOB)標簽,找到潛在的關鍵語義概念;
二、生成問題,使用單向LSTM來產生問題,同時參與段落中的單詞和IOB ID的嵌入。
有兩個利用這種方法生成的問題和答案的例子:


最後,可能你會關注使用SynNet實際應用的效果。微軟AI研究團隊先用SQuAD(維基百科文章)訓練SynNet,然後把它應用到NewsQA(新聞文章)上,發現它的效果與直接在NewsQA上訓練的網絡相差無幾。
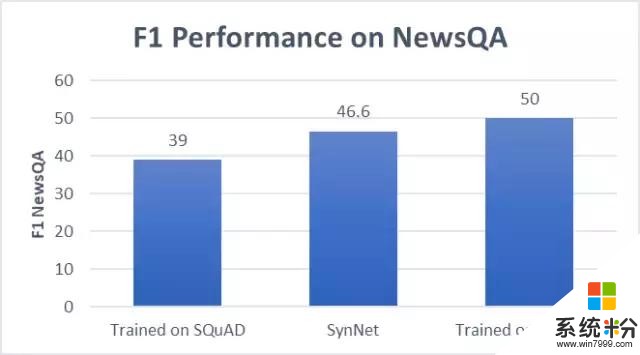
也就是說,通過使用SynNet,可以開始在無需額外標注、訓練數據的基礎上,在新領域打造一個完全監督的MRC係統。
相關論文:
https://www.microsoft.com/en-us/research/publication/two-stage-synthesis-networks-transfer-learning-machine-comprehension/
【完】




















