
時間:2017-07-26 來源:互聯網 瀏覽量:
如今,計算機視覺領域常見物體的圖像識別和圖像分類對大家來說已不再陌生,但提及精細化物體分類,或許不少人還不太了解。我們先放點圖來一起感受一下精細化物體分類的“威力”~
大家先看看這兩張圖是同一種鳥嗎?

先別急說答案,看了下麵兩張局部高清圖再做決定。

類似的例子還有很多,它們看起來整體外觀十分相似,但細節特征反映了它們的差別。

就在前幾日,最後一屆ImageNet 榜單剛剛公布,最新的模型在圖像分類任務上已經達到了top-5 結果預測錯誤率2.3%的水平。然而盡管分類精度如此之高,但由於類別不夠精細化(注:ImageNet競賽包含常見的1000個物體類別),使得這些模型在實際應用中往往無法滿足用戶的實際需求。
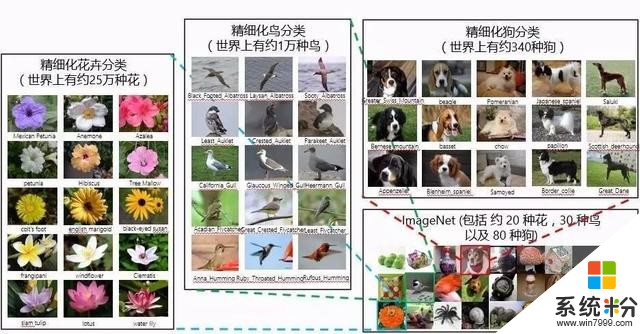
在日常生活中,我們可以很容易地識別出常見物體的類別(比如:計算機、手機、水杯等),但如果進一步去判斷更為精細化的物體分類名稱,比如去公園遊覽所見的各種花卉、樹木,在湖中劃船時遇到的各種鳥類,恐怕是專家也很難做到無所不曉。不過,也可見精細化物體分類所存在的巨大需求和潛在市場。
雖然精細化物體分類擁有廣闊的應用前景,但同時也麵臨著艱巨的挑戰。如下圖所示,每一行的三種動物都屬於不同種類,但其視覺差異卻非常微小。要分辨他們,對於普通人來說絕非易事。

通過觀察我們不難發現,對於精細化物體分類問題,其實形態、輪廓特征顯得不那麼重要,而細節紋理特征則起到了主導作用。目前,精細化分類的方法主要有以下兩類:
基於圖像重要區域定位的方法。該方法集中探討如何利用弱監督的信息自動找到圖像中有判別力的區域,從而達到精細化分類的目的。
基於圖像精細化特征表達的方法。該方法提出使用高維度的圖像特征(如:bilinear vector)對圖像信息進行高階編碼,以達到準確分類的目的。
然而,這兩種方法都有其各自的局限性。最近,微軟亞洲研究院多媒體搜索與挖掘組的研究員們通過大量的實驗觀察以及與相關領域專家的討論,創造性地提出了“將判別力區域的定位和精細化特征的學習聯合進行優化”的構想,從而讓兩者在學習的過程中相互強化,也由此誕生了“Recurrent Attention Convolutional Neural Network”(RA-CNN,基於遞歸注意力模型的卷積神經網絡)網絡結構。這種網絡可以更精準地找到圖像中有判別力的子區域,然後采用高分辨率、精細化特征描述這些區域,進而大大提高精細化物體分類的精度。該項工作已經被CVPR 2017(計算機視覺與模式識別)大會接收,並應邀做了報告分享,請點擊【閱讀原文】查看該論文。

微軟亞洲研究院副研究員傅建龍在CVPR 2017進行報告分享
從開篇的幾張局部高清圖中,我們已經可以感受到有判別力的區域對精細化物體分類的巨大幫助。
其實,這樣的情況在精細化物體分類問題中非常普遍。看似相似的兩張圖片,當我們把有判別力的區域放大後卻發現大相徑庭。而“RA-CNN”網絡則有效地利用了這一特點,通過將不同尺度圖像的重要區域特征融合,以確保重要信息充分發揮作用:有用的信息不丟失,同時噪聲得到抑製。
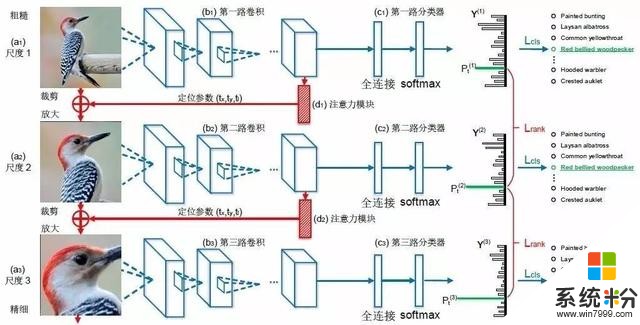
隻需輸入一張圖片,“RA-CNN”便可自動找到不同尺度下的有判別力區域:上圖中藍色部分是分類子網絡,它們將多個尺度的圖片用相應的卷積層提取出特征後送入softmax 分類器,再以類別標簽作為監督對卷積層和分類器參數進行優化,當最終分類時,將各個尺度的特征拚接起來,用全連接層將信息充分融合後進行分類。
上圖中的紅色部分則是定位子網絡,其輸入是一張圖片的卷積層特征,而輸出的是這張圖片有判別力區域的中心坐標值和邊長。定位子網絡以層間的排序損失函數作為監督,優化下一尺度的圖片子區域在正確類別上的預測概率大於本尺度的預測概率,這樣可以促使網絡自動找到最有判別力的區域。有了重要區域的坐標,再對原圖進行裁剪和放大操作便可得到下一尺度的輸入圖片,而為了使網絡可以進行端到端的訓練,研究員們設計了一種對裁剪操作進行近似的可導函數來實現。以下是“RA-CNN”在三個公開數據集上找到的有判別力區域的例子及對應的分類精度:

看到這裏或許你對“RA-CNN”精細化物體分類問題的解決原理及其效果有了一定的了解。若想了解更多技術細節,請點擊【閱讀原文】查看該CVPR 2017論文~ 同時你也可以下載微軟亞洲研究院推出的智能識別應用——微軟識花,親自體驗精細化物體分類技術的獨特魅力哦~
掃描二維碼下載“微軟識花”一鍵體驗
你也許還想看:
,共建交流平台。來稿請寄:msraai@microsoft.com。
 微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。
微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。




















