
時間:2017-07-17 來源:互聯網 瀏覽量:

近日,卡內基梅隆大學(CMU)計算機學院院長Andrew W. Moore和副院長Philip L. Lehman來到微軟亞洲研究院,與研究員們分享了過去兩年中人工智能領域的一些技術突破,並從業界和學界兩個角度,探討了他們對於人工智能接下來發展方向的看法。
今天,我們就在這裏與大家分享此次演講~以下為Andrew W. Moore演講的精簡版文字整理。
2005到2015年間,我們見證了數據科學在學術界和商業界的發展,學會了如何正確地使用分布式計算、GPU,如何很快的建立抽象模型等等。仿佛AI完全轉化成了機器學習,每個人都在處理數據、基於數據為複雜的世界建模……
大約2014年,許多人開始意識到這些工作還遠遠不夠,它們僅能實現改變世界藍圖的一半,而另一半則是被我們視為數據科學最頂層的決策係統。上世紀90年代,我們對所建立的係統都十分樂觀。但漸漸地,我們發現,這些係統在應用到實際生活中時並沒有效果,比如在優化城市交通數據時,一個完美的優化算法並沒有幫助,因為那時我們沒有任何關於城市交通的數據。所以現在,我們嚴肅認真地考慮重新回到基於數據科學的大規模優化和決策上。
而在大學裏,我們會思考更多的可能性。有些教授認為自主性(autonomy)是最重要的,是AI的真正目標,對此觀點我們十分尊重。它在很多方麵,比如深空探索或需要快速決策的情況下,都將有重要的應用。當然,自主性不是AI最終唯一的目標。它還包括其他方麵,例如增強人類(augmented humans)等等,在我看來這和微軟的核心任務,如何更好地幫助人類工作、生活,有著很大的重合度。我們需要幫助人類更好地工作、生活,同時也需要自主性。
在數據科學方麵,我們需要關注三個部分。首先是人工智能的基礎建設,包括大型優化策略,它需要我們擅長大規模線性規劃問題和隨機梯度下降等問題。其次,是自主性(autonomy),最後是增強人類(augmented humans)。
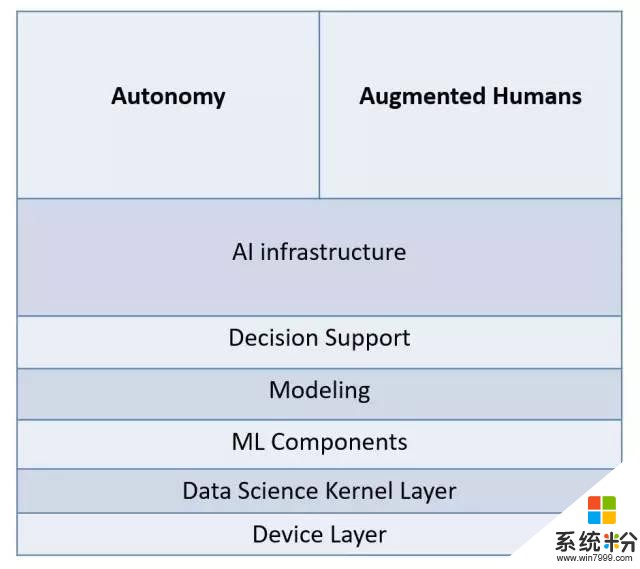
接下來,我將會談到四個主題:
1
大型網絡公司的視角
首先,談談我在工業界和學術界所見的不同之處。在工業界,我們會非常關注機器學習模型的高效性。雖然一個高效的機器學習模型很好,但仍需要做到每秒鍾完成數百萬的預測量。所以,即使我們的算法能夠高效的完成訓練,然而在實際應用時,花費依舊很大。尤其是當你想在本地設備上使用它而不是通過雲端時,這仍然是個問題。
2
過去24個月,機器學習領域的最大變化
對於許多大型搜索引擎公司來說,機器學習超過百分之五十的工作在於測試和驗證。因此,我對未來穩定、可靠且經過長期驗證的機器學習模型充滿期待,以及如何確保深度學習算法不會在運行幾個月後走向奇怪的方向。對於機器學習算法,會有工具幫助快速診斷目前正在發生什麼以及如何解決。例如,你有一些係統問題導致了隨機梯度下降的更新,並帶來了額外的延遲等,而對於這些問題你都可以很快地理解,並改進。但在我的學術生涯中,還沒有看到過類似的技術,所以我希望接下來的幾年,我們的機器學習模型可以在穩定性、安全性和長時間的可靠性上有更大的突破。
在這裏我想展示一下我們一位同事最近的研究成果。他研究的是針對如飛機和汽車動力係統的操縱係統前期和後期條件類型分析,這曾經被認為是最重要的證明軟件正確性的方法之一。我的這位同事采用老式方法將係統與控製係統中的統計和數值方法結合,來證明如果有一個機器人控製算法,即使是一個非線性的算法,它也會按照所說的來做。現在,美國許多的自動駕駛係統研究在提高係統安全的問題上停滯不前,因此,這項工作將非常具有實用意義。
在軍事方麵,使用自動駕駛技術可以避免很多不必要的犧牲,僅僅使用一輛車就可以帶動其餘的自動駕駛車輛。雖然聽起來很簡單,但這項應用實現的最大阻礙還是證明我們所使用的機器學習係統和這些自主駕駛場景的可靠性。所以,當我們在新的研究領域找尋策略時,自適應算法的安全性驗證相比於增加現有算法速度的準確性,可能會更重要。
此外,我還想和大家分享一些有趣的研究。如今,人類生物識別也已成為一個科學研究方向。與從演講錄音中提取演講內容相反,我的一位同事,Rita嚐試了從中提取其他的聲音信號,進而得到關於演講者的信息。我們可以從低分辨率的數據中準確的預測出人的氣管形狀和大小,同時,這些信息與人的身高、體重等其他身體特征也密切相關。簡而言之,她可以在一場演講錄音中了解演講者的身高、體重、成長地等等。這也是機器學習新應用的一個例子。
還有一個例子,是一台特殊的相機,它可以根據紅外光譜在20米內聚焦。它的特別之處在於移動快速、準確,可以在三十分之一秒內停在目標地點。同時,基於它的高分辨率,我們可以準確地完成生物識別,識別每個人。這一技術,將來或許可以應用在商店購物,我們不再需要收銀員,當你從貨架上去拿商品時,付款就已經通過你的虹膜支付完成了。其實,這類應用從技術上是可行的,但它究竟是好事還是壞事,我們還不得而知。
此外,一個研究的重要領域是逆向強化學習(Inverse Reinforcement learning)。眾所周知,在強化學習中,我們會定義一個獎勵函數(reward function),然後嚐試尋找最大化獎勵函數長期結果的策略。而在逆向強化學習中,我們則是嚐試根據其他個體選擇的行為來推斷它們的獎勵函數。
比如,根據車流和行人已有的移動軌跡我們可以預測每個人、每輛車的移動可能。所以,當我們把目光投向計算機視覺的未來時,實際上我們已經將重心從觀測即時信息,轉向了預測將來15秒的狀態信息。這對於自動駕駛和人群的安全都將有重大意義。
我們關注的另一個領域是,自主平台在機器人相關方麵的成熟應用。預測空間的3D模型在機器人技術進步的基礎上,也已經非常成熟了,而這也是將來機器人發展的基礎。如果你熟悉這一成熟技術背後的計算模型,從獲取數據到傳送到雲端,它使用了大量的EM 算法以加速前後的推理。而我的一位同事的研究突破在於使算法有了一個非常準確的增量,不再需要上傳數據到雲端。通過簡潔的代數技巧(algebra trick),我們可以模擬整個EM算法的運行。更有意義的是,低功耗的遠程設備就可以完成。

Andrew W. Moore 卡內基梅隆大學計算機學院院長
3
接下來的24個月,機器學習領域將可能有哪些重大突破
情緒壓力測試是一個快速成長的領域,微軟是這方麵的專家。在匹茲堡,我們也對這一領域充滿興趣。這裏有一個重要的應用,我們可以通過觀察人們說話時的麵部特征,評估他們對於某件事情情緒波動的程度。舉個例子,當用於醫療時,我們可以通過觀察病人的反應,判斷治療是否有效。一年前,我們曾有實驗表明,在醫生可以判斷病人生理特征表現的六周前,我們就成功判斷了治療的效果,通過對麵部肌肉的檢測我們可以獲得許多情緒信息。因此,未來我們或許可以更快捷、有效地幫助患有精神疾病的病人。
同時,對於大家關注的用戶和電腦間的對話係統,我們的兩位同事發現,對於複雜對話,病人談論到一些疾病症狀,或者學習上有疑問想獲得反饋的孩子們,機器能夠對對話產生更快、更成功的結果,因為機器可以根據用戶情緒調整反饋結果。
所以,通過這些客觀證據我們可以看出,如果想建立一個優秀的對話係統,則需要考慮到實際情緒的相互作用。現在在CMU,我們有計算機視覺實驗室,有對於語言技術的研究,我相信在不久的將來,情緒認知也會是我們的研究重心。
接下來,我想談談知識圖譜。在美國,許多企業和大學包括微軟,以及一些政府機構經過一係列的會議討論一致認為,我們需要分享構建的大型知識圖譜。因為對於對像阿裏巴巴、亞馬遜這樣的零售公司來說,為各種產品構建單獨的知識圖譜是非常困難的,同樣的,對於做地圖的公司來說,為城市地標構建單獨的知識圖譜也非常困難。
患者想要討論醫療健康問題、學生想討論關於學習的問題等等,在未來,商業領域之外的對話係統構建方麵,我們還有很多工作可以做。醫療、教育、政府等,如果每個公司都單獨構建知識圖譜,那麼這將消耗大量資金,同時,不同的語言也會帶來很多不必要的資源浪費。因此,我們強烈認為,合作將是未來工作的基礎,我們將一起構造開放的知識網絡。
首先,我們可以將各種實體作為知識圖譜的節點,這些實體可以是埃菲爾鐵塔、CMU音樂學院、甚至可以是一個投影儀等等。對於這些數以萬億的實體,目前我們有很多類型的實體工具,它們各有利弊。成本高、針對性強的圖譜難以大範圍應用,通用的圖譜又過於耗時。例如GIS係統雖然已經很完善但仍難以應用到其他領域。所以,將來我們在構建和存儲實體時,需要在數據庫中為他們和其他實體建立對話聯係。
然後,我們要匹配引擎(matching engine)。這與搜索引擎非常相似,同樣需要快速的深度學習能力。匹配引擎從演講、文本、可視範圍中選取內容,以構建知識圖譜中實體的概率分布,這對於構建一個準確的匹配非常重要。所以,對基於知識圖譜實現具體應用的人們來說,他們需要處理概率集合以形成總體結論。
大家都知道,現在大部分的知識圖譜是基於三元組的,三元組是一種原始的表達事實的方式。除了科學實驗,它還出現在一些與科學相關的領域,如經濟、金融等。專家們發現,因為缺乏統一的數據模式,即使有很好的數據集,它們還是很難在數據間建立連接。這也是我們希望通過構建全局知識圖譜來幫助我們的地方。
有趣的是,在構建全局知識圖譜中,我們還有很多機器學習的問題需要解決,比如合並指向同一實體的不同對象或者區分相像但不同的對象等。雖然我們有很不錯的概率模型,但是在公共領域之外,它們無法像成熟的算法一樣處理數萬億的內容(mentions)以建造理想的對話係統。發現問題,解決問題,這是一件非常令人興奮的事情。
4
一些近期機器學習不那麼顯著的應用
我還想談談我們另一位同事的工作,這可能是一個大多數人都沒有想過的領域。一個大型代碼庫,不論開源還是公司內部的代碼庫,都是非常豐富的數據資源,你可以獲得大約千萬到數十億行的代碼量用以統計分析。你會有一個關於代碼庫的完整的曆史記錄表,換句話說,我們實際上有一個關於人們何時做決定,出於什麼原因作出改變的日誌。現在大多數的代碼庫中,這些記錄裏有30%都是關於錯誤修改的,而不是重構或改進的。這是一個很好的機器學習任務,如果你擁有這些訓練數據,那是否可以再次預測出代碼庫中的錯誤出現在哪裏?哪部分數據是最有可能被修改的?
目前,這項研究進行的十分順利,預測效果也比較理想。我們可以拓展一下應用場景,你可以將它用於錯誤預測。從修改日誌中,可以預測自己的代碼有哪些是可能需要改變的。更有意思的是,我們可以將這一在自然語言中有重大突破的技術應用於自我重寫的代碼。
最後我想回到低功耗設備的自主性上,它仍是一個種重要的主題。它與不依靠雲的單一低功耗平台的視覺處理有關。考慮到計算代價和延遲等因素,我們通常不將雲與計算機視覺等研究結合。現在我展示的是一個無人機上的單個攝像機,它能在飛行時及時推斷樹木的位置,並計算飛行路線。這是一個很好的關於實時係統的例子,係統工作中不允許有停止和延遲。我們成功地將傳統計算機視覺算法運用在了低功耗的設備上。
最後一個問題,我稱之為皇冠上的珠寶,誰將為自主性(autonomy)編寫操作係統?CMU是世界最先進的機器人研發基地之一,我們有超過3000個已經投入使用的機器人平台。有了這些經驗,每當有人需要我們做一種新的機器人時,我們都能很快的完成。但目前我們仍舊是根據經驗在做,沒有人真正建立一個實際操作軟件工具的操作係統。本世紀的前半葉,誰將為自主性(autonomy)編寫所有的操作係統?
希望我的分享對接下來二十年學術界可以專注的AI發展方向有所幫助。
Andrew W. Moore個人介紹

Andrew W. Moore是卡內基梅隆大學(CMU)計算機學院的第十五位院長。他的研究領域主要有統計機器學習、人工智能、機器人技術以及大數據統計計算。他曾在機器人控製、製造、強化學習、天體物理算法、電子商務領域都有所建樹。他的數據挖掘教程下載量已達100多萬。他建立了Auton Lab研究組,該研究組設計了有效的關於大型統計操作的新方法,並在多種情況下都實現了幾個數量級的加速效果。Auton研究組的成員與許多科學家、政府機構、技術公司都有著密切的合作,旨在不斷尋求在計算、統計數據挖掘、機器學習和人工智能領域中最函待解決的問題。2006年,Andrew加入穀歌,參與Google Pittsburgh的建立。同時,他也參與了包括Google Sky和Android SkyMap的相關事宜。2014年8月,Andrew重返卡內基梅隆大學(CMU),繼續擔任計算機學院院長。
你也許還想看:
,共建交流平台。來稿請寄:msraai@microsoft.com。
 微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。
微軟小冰進駐微軟研究院微信啦!快去主頁和她聊聊天吧。




















