
時間:2017-07-12 來源:互聯網 瀏覽量:
AI科技評論按:7月7號,全球人工智能和機器人峰會在深圳如期舉辦,由CCF主辦、與香港中文大學(深圳)承辦的這次大會共聚集了來自全球30多位AI領域科學家、近300家AI明星企業。最近將會陸續放出峰會上的精華內容,回饋給長期以來支持的讀者們!
本次介紹的這位嘉賓是微軟亞洲研究院資深研究員梅濤博士,分享主題為「視頻內容的生命周期:創作,處理,消費」。

梅濤博士,微軟亞洲研究院資深研究員,國際模式識別學會會士,美國計算機協會傑出科學家,中國科技大學和中山大學兼職教授博導。主要研究興趣為多媒體分析、計算機視覺和機器學習,發表論文 100餘篇(h-index 42),先後10次榮獲最佳論文獎,擁有40餘項美國和國際專利(18項授權),其研究成果十餘次被成功轉化到微軟的產品和服務中。他的研究團隊目前致力於視頻和圖像的深度理解、分析和應用。他同時擔任 IEEE 和 ACM 多媒體彙刊(IEEE TMM 和 ACM TOMM)以及模式識別(Pattern Recognition)等學術期刊的編委,並且是多個國際多媒體會議(如 ACM Multimedia, IEEE ICME, IEEE MMSP 等)的大會主席和程序委員會主席。他分別於 2001 年和 2006 年在中國科技大學獲學士和博士學位。
為什麼要以「視頻內容」為主題做分享?梅濤博士從三個方麵講了他為什麼想和大家分享「視頻內容」這個話題。首先視頻跟圖像相比信息更豐富,處理起來也更富挑戰性;其次,計算機視覺技術領域,如人臉識別,人體跟蹤等研究的比較多,而互聯網視頻內容相對來說研究的比較少;最後,他說在十年前就開始做視頻方麵的研究,所有人都說視頻是下一個風口,今天看來這個說法也是對的。
在傳統的視覺理解(2012年以前)的方法裏,要做視覺問題基本上分三個步驟:
第一,理解一個物體,比如說識別一個桌子,首先要檢測一個關鍵點(比如角、邊、麵等);
第二,人為設計一些特征來描述這些點的視覺屬性;
第三,采用一些分類器將這些人為設計的特征作為輸入進行分類和識別。
而現在的深度學習,尤其是在2012年開始以後:
“圖像理解的錯誤率在不斷降低,深度神經網絡也從最早的8層到20多層,到現在能達到152層。我們最新的工作也表明,視頻理解的深度神經網絡也可以從2015年3D CNN的11層做到現在的199層。”
梅濤博士也在演講中表示,視頻內容的生命周期大致可以分為三個部分,即視頻的創作、處理和消費。
Creation(創作)關於怎麼去創造一個視頻,梅濤博士給了一個基本概念。“Video的產生是先把Video切成一個一個的鏡頭,可以看成是一個一個斷碼,然後每一個鏡頭再組合編成一個故事或場景,每一個鏡頭還可以再細成子鏡頭,每個子鏡頭可以用一個關鍵幀來代表。通過這種分層式結構可以把一段非線性的視頻流像切分文章一樣進行結構化,這種結構化是後麵做視頻處理和分析的基礎。通過這種結構化將視頻分解成不同的單元,就可以做視頻的自動摘要,即將一段長視頻自動剪輯為精彩的短視頻,或將一段長視頻用一些具有高度視覺代表性的關鍵幀表示。這些摘要使得用戶對長視頻的非線性快速瀏覽成為可能。”
梅濤博士表示,微軟目前將視頻摘要的技術用在了Bing的視頻搜索裏,現在全世界有八百萬的Bing用戶通過一種叫multi-thumb的技術,可以快速預覽每一個視頻搜索結果。
Curation(處理)當用戶有了視頻之後,研究者要做的事情是給視頻片段打上標簽,這樣後麵的搜索就可以基於標簽搜到視頻的內容裏麵去。“我們最近的工作可以對視頻內容打上1000多個靜態標簽和超過500個以上的動作標簽。我們設計的P3D(pseudo 3D resent)是專門為視頻內容理解而精心設計的3D殘差網絡。”
做圖像分析目前最好的深度神經網絡是微軟亞洲研究院在2015年提出的152層的殘差網絡(ResNet),目前最深可以做到1000層。但是在視頻領域,專門為視頻設計的最有效的3D CNN目前才11層。
為了解決這一問題,梅濤博士表示,團隊最近借用ResNet的思想,將3D CNN的層數做到了199,識別率能在UCF 101數據集上比之前的3D CNN提高6到7個百分點。這一對視頻進行自動標簽的技術,將會被用在微軟的Azure雲服務中。
實現了視頻自動標簽技術外,梅濤博士還闡述了團隊“更進一步”的研究工作:用一段連貫通順的自然語言,而不是孤立的單個標簽,來描述一段視頻內容。
“比如給定這段視頻,我們能不能生成一句話來描述這個Video?以前我們說這個Video是一個舞蹈,現在可以告訴你這是一群人在跳一段什麼舞蹈,這個技術就叫Video Captioning(視頻說明)。這個技術使得自動生成視頻的標題成為可能。”
微軟亞洲研究院目前把這個技術用在了聊天機器人的自動評價功能裏,例如微軟小冰,當用戶上傳視頻給小冰,它會誇讚對方。在這個技術上線一個月後,小冰在某視頻網站上的粉絲數漲了60%。當然,小冰現在還可以根據圖片內容寫現代詩,將來我們希望小冰能夠根據視頻來寫詩。
“我們也可以將Video進行編輯,加上濾鏡,或是做風格的轉換,把自然的Video變得非常卡通。視頻中的人物分割出來可以放到另外一個虛擬的場景裏麵去。你可以想象,當兩個人在異地談戀愛的時候,我們能夠給他一個房間,讓他們在同一個房間裏、在星空下、在安靜湖麵上的一艘小船上進行聊天。另外,我們也可以提供storytelling的服務,讓原始的、沒有經過任何編輯和處理的image、video集合變成一段非常吸引人的、有一定設計感和視覺感的故事,這段視頻demo就是機器自動產生的效果。加上人工的處理,視頻就可以變得更加時尚。”
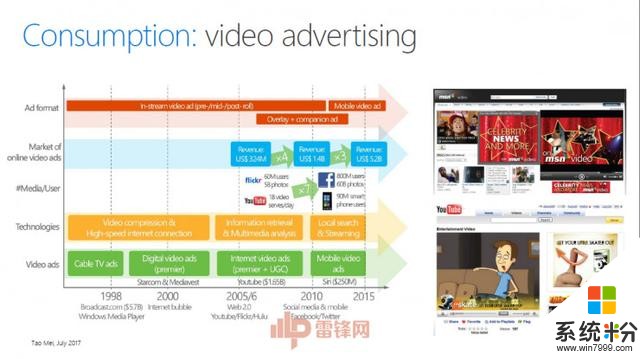
Consumption(消費)視頻的消費往往和廣告緊密相關。梅濤提到,做視頻廣告有兩個問題需要解決:第一個問題是廣告到底放在視頻的什麼位置;第二個問題是選什麼樣的廣告,這個廣告跟你插入點的信息是不是相關,使得用戶接受度更加好。
他們的解決方案是將視頻進行分解,並計算出兩種度量,一個是discontinuity(不連續),衡量一個廣告插入點的故事情節是否連續;另一個是attractiveness(吸引力),衡量一段原始視頻的內容是否精彩。對這兩種度量進行不同的組合就可以滿足符合廣告商(advertiser)或用戶(viewer)的需求。
最後梅濤總結道,在做科研的人看來,AI也好,深度學習也好,落地都有很長的路要走。“雖然計算機視覺已經發展了50多年,雖然現在AI炒的很火熱,但做科研和技術的,還是要腳踏實地去解決一個個的場景和一個個底層的基礎難題。”
以下是梅濤博士的現場分享實錄,做了不改動原意的整理和編輯
很高興跟大家聊一下視頻內容領域。為什麼講視頻內容呢?有三個原因:第一個原因是視頻跟圖像相比更加深入,視頻是信息領域的東西,研究視頻是一個非常大的挑戰。第二是大家在很多專場看到視覺領域,人臉、安防方麵的進展,視頻領域對大家來說是相對比較嶄新的東西。第三是我本人在十年前做視頻方麵的研究,所有人都說視頻是下一個風口,今天看來這個說法也是對的。

計算機視覺(CV)可以認為是人工智能的一個分支,1960年代CV的創始人之一Marvin Minsky說,“給計算機接上一個相機,計算機可以理解相機所看到的世界。”這是做CV人的一個夢想。到最近的50年,CV領域發展有很多成果,如果來總結一下,從視覺理解角度來看,要做視覺問題基本上分三個步驟:首先,理解一個東西,比如說識別一個桌子,我們要檢測一些線條,一些拐角。第二,人為設計一些特征來描述所檢測的特征。第三,設計一些分類器。這是我們2012年以前大家做CV的三個步驟。

大家可以從這個圖中看到CV的一些進展,舉幾個例子,比如說這篇論文SIFT(Scaled Invariant Feature Transform)文,已經被引用55000次了。另外,如果大家做人臉識別就會知道,需要定位人臉的區域。我們2001年有一個方法是Boosting +Cascade,做快速的人臉定位。到今天為止,雖然大家知道做人臉定位有很多深度學習的方法,但是這個方法依然是最先的必經的步驟之一。這個論文到目前為止已被引用了30000次,在學術界有一篇論文被引用超過10000次已經是相當了不起了。到了2012年以後,基本上所有人都在用深度學習,從Hinton的學生用AlexNet在ImageNet上麵能得到近乎15%的錯誤率,從那開始,所有視覺的東西都在用CNN,代表性的有GoogLeNet,AlexNet等等,我們的任務也會越來越多,越來越有挑戰,比如現在正在做的從圖片中生成語言,不僅要在圖片或視頻中打上一些標簽,還要把這些標簽變成能用自然語言描述的一句話。
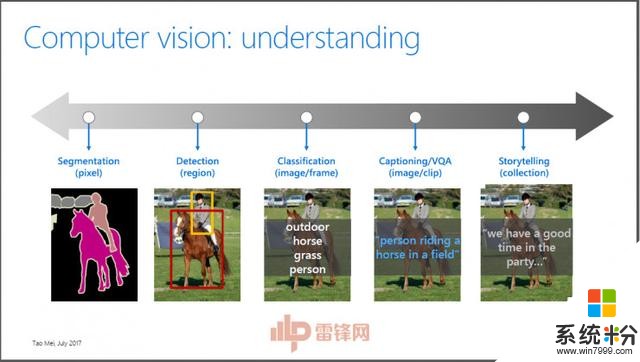
我們今天講的是視頻理解,如果從理解一個像素或理解一個圖片或視頻來說,可以把這個理解問題分成幾個層次。最難的是需要理解圖片或視頻裏麵每個像素代表什麼標簽。再往上是我們關心每一個物體在什麼位置、屬於什麼類別。第三部分是不關心這個物體在什麼地方,你給我一圖片或者視頻,我就知道這個圖片或者視頻裏麵有什麼標簽。再往前走一步,比如說我給你一個圖片,要求不僅要生成單獨的標簽,還要看你能不能生成一個非常自然的語言來描述這個圖片。再往上,我給你一個圖片,能不能給我一個故事,比如說現在機器能不能產生這樣一個故事。

大家看一下這個圖(見PPT),Image Classification(圖像分類)從最早8層到20多層,到現在我們的152層。我們在微軟做了很多工作,image裏麵有很多image recognition computational style transfer(圖像識別計算的風格轉換)等等。微軟跟這個相關的產品有很多,比如說小冰不僅可以跟你用文字聊天,還可以通過圖片和視頻跟你交流。
從圖像到視頻,理解一個視頻必須理解每一個幀裏麵的運動。為什麼今天要談論視頻呢?

全世界現在每天有超過50%的人在線看視頻,每天在Facebook上會觀看37億個視頻,YouTube上每天會觀看5億小時時長的視頻。我們做視頻,大家首先想到的就是做廣告,視頻上麵的廣告每年都是30%的速度遞增的,在YouTube上麵也是每年30%的增長態勢。人們在視頻上花的時間是圖片上的2.6倍。視頻的生成比文字和圖片要多1200%。2016年中國視頻用戶超過7億。
今天從另外一個角度來看視頻內容的產生、編輯、管理會經曆哪些過程,有哪些技術來支撐,我們從Creation(創作)到Curation(處理)、到Consumption(消費)的順序來講。
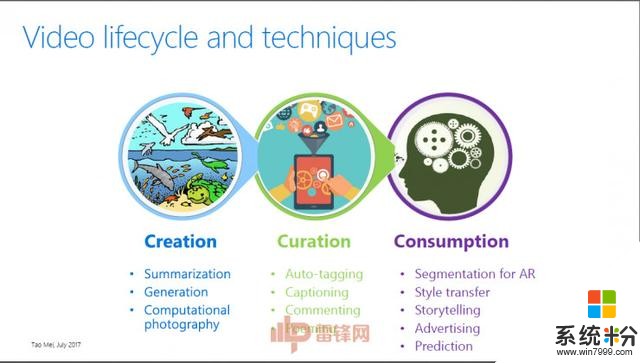
怎麼去創作一個視頻?這裏麵有一個基本概念,視頻的產生是先把視頻切成一個一個的鏡頭,你可以看成是一個一個斷碼,然後每一個鏡頭再編成一個故事,每幾個語言可以放成一個故事。每一個鏡頭可以分成子鏡頭,然後有一個數據,這是我們做視頻的前提。
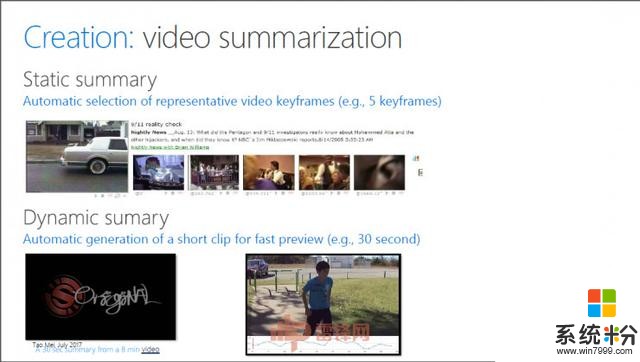
今天一個視頻,可能15分鍾,可能是1個小時,能不能給你5個關鍵幀你就知道這個鏡頭。一個8分鍾的視頻能不能生成30秒的內容,比如說來了一個運動視頻,通過智能分析知道這個運動視頻裏麵哪個部分最應該看,這是它的重點。
另一個話題是視頻生成,今天我給你一段文字,你給我生成一個新的視頻,這個事情聽起來天方夜譚,但是值得挑戰。我告訴你生成一個視頻,也就是一個數字8在上麵不停的遊動。另外給你數字6和0,能不能讓數字6和0在這裏麵遊動,這個事情是非常難的。最近我們做了研究,發現可以做一些簡單的事情,比如說一個人在烤牛肉。實際上這還是很難的,因為我們生成的視頻準確性非常低,所以這是非常難的事情。

當有了視頻之後要做的事情是給視頻打標簽,至今為止可以打上1000個的靜態標簽,你有了這些靜態的標簽就可以設置到內容裏麵去。比如說視頻裏麵出現一個橋,這個橋的位置在哪裏。比如說一些運動,這是我們能夠識別出來的運動,左邊都是運動的視頻,右邊是我們日常生活中的一些行為。有兩個動作最難識別,一個是跳躍,一個是三級跳,但是我們現在已經可以區分出這些非常細微的差別。

這是我們今天講的唯一的一個技術性的部分。我們最近做的一個非常好的工作,就是可以做深層次的網絡,我們可以通過一些方式使得深層次的網絡是可行的。比如說這個到現在可以做到152層,也可以做到1001層,性能超過了任何網絡。我們能不能從這個網站的圖片擴展到視頻?我把二維的卷積盒變成三維的,當它卷積的時候是沿著X、Y和T這個方向卷積的。C3D模型是可以做到13層,它非常複雜。我們有一個想法,把它進行分解,一個是可以找出這個物體的數量,使的這個過程可行,另外還可以在圖像上進行處理。我們做了很多工作,比如說這個視頻是一個太極的動作,我們通過P3D可以找出來4個點,這個已經非常了不起了。

我們可以很精確的告訴你這個視頻中每一個關節是怎麼運動的(見PPT),比如說我今天做一個智能的健身教練,可以把你的動作進行分解,告訴你哪個動作是不準確的。
還有一個是Video captioning(視頻說明),給你一個視頻,能不能生成一句話來描述這個視頻。以前我們說這個視頻是一個舞蹈,現在可以告訴你說這是一個什麼舞蹈。

這是我們生成的一個視頻(見PPT)。小冰能夠做auto-commenting(自動評論),不僅告訴你很美,還能告訴你美在什麼地方。後麵是一個小孩子,它說你的女兒很漂亮、很時尚。基本上它可以給自拍的視頻做評論,給小孩的視頻做評論,也可以給寵物視頻做評論。

小冰還可以寫詩,最近我們發表了一個小冰詩集。小冰說:“看那星,閃爍的幾顆星,西山上的太陽,青蛙兒正在遠遠的淺水,她嫁給了人間許多的顏色”。

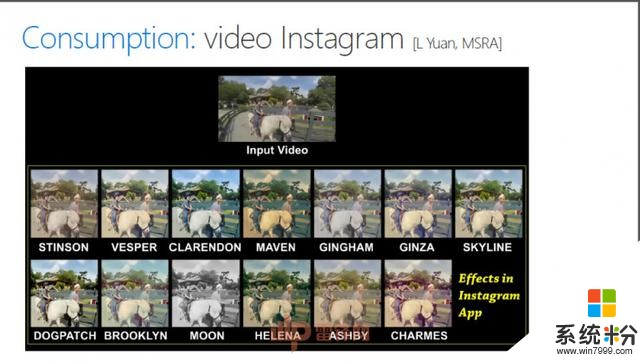
我們另外還做style transfer(風格轉移),給你一個油畫或者卡通,能不能把這個風格轉移到視頻中,可以把這個水的波紋表達出來。

下麵這幅圖是某個娛樂節目,我們可以把這個人物分割出來放到另外一個虛擬的場景裏麵去。你可以想象,當兩個人在異地談戀愛的時候,我們能夠給他一個房間,讓他們在房間裏麵進行聊天。
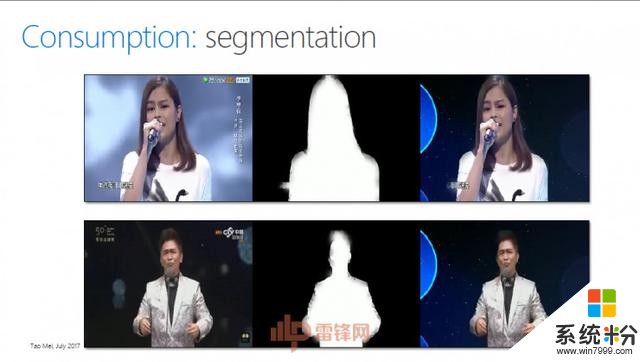
還有Storytelling(講故事),我能不能給你提供服務,讓你的圖片、視頻變得更好,這都是機器產生的效果(見PPT)。這個風格叫Fashion,我們隻要加上人工的處理,視頻就可以讓你的圖片變得更加時尚。這很容易用在一些to C(針對消費者的市場)的場景裏麵。
講一下最後一個題目,這個廣告是我十幾年前加入微軟的項目。那時候我們做的視頻廣告有兩個問題需要解決:第一個問題是廣告到底放在視頻的什麼位置;第二個問題是選什麼樣的廣告,這個廣告跟你插入點的信息是不是相關,使得用戶接受度更加好。這兩個問題怎麼解決?當時我們提出一個方案,我來了一個視頻,把這個視頻分解,我們有幾個值,第一個是discontinuity(不連續),看每一段是不是可以做廣告,它的間斷點使得用戶的接受度更好。還有就是在是激動人心的階段放廣告。另外一個是Attractiveness(吸引力),讓它變得可計算,當時我們有兩個曲線,這兩個曲線有不同的方式,第一種方式是要符合廣告商的需求。

這個視頻裏麵,當出現車子爆炸的鏡頭,我們可以識別出來這個內容,可以在這裏放廣告,使得廣告和內容無縫連接在一起。我們也可以在故事需要的地方放廣告。
剛才講了很多場景和技術,但是在做科研的人看來,AI也好,深度學習也好,落地有很長的路要走,我們要腳踏實地的一個一個的去實現。
這就是我今天的演講,謝謝大家!
整理編輯




















