
時間:2017-07-04 來源:互聯網 瀏覽量:
商業計算、可選研究、以及4K多屏遊戲等需求,不斷推升著對現代GPU的性能需求。 根據一份近期的研究報告,NVIDIA認為正在迅速接近當前GPU架構模型的極限,因此需要尋找新的方法去攻堅。 當前這個想法仍處於模擬階段,但文中提到的“多芯片模塊GPU”(MCM-GPU)的概念,有望最終將多顆GPU模塊整合到一處。

在意識到NVIDIA將很快難以通過當前架構榨取GPU性能之後,亞利桑那州立大學、英偉達、德州大學奧斯汀分校、以及巴塞羅那超算中心攜手展開了研究。
此前,廠商還可以通過在每次製程迭代時堆積更多的流處理器來提升GPU性能。但遺憾的是,在單一模塊中塞入更多晶體管的方法,已經變得越來越困難。
以NVIDIA V100 GPU為例,其已經需要代工廠商(台積電)將製程推到 12nm 的極限。此外,製造規模越來越大的模塊,其成本和相關問題也不可忽視(比如因製造錯誤遇到的數量減少)。
雖然NVIDIA可以通過將多顆GPU裝在一塊 PCB 上的方式來提升顯卡性能(比如Tesla K10 和 K80),但當前仍有一些未能解決的問題 —— 比如跨多GPU的任務分配就需要編程來提升硬件效率。
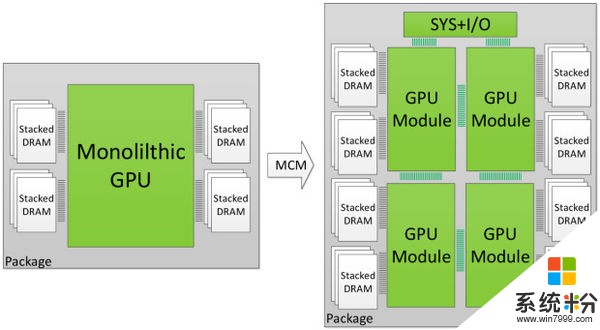
於是研究人員們另辟蹊徑,決定在封裝技術上尋找新方法,讓 NVIDIA 可以將多個GPU模塊(GPMs)封裝到一塊。這些 GPMs 比當代GPU要小一些,製造起來也更容易和便宜。
盡管人們對其性能仍有疑問,但研究人員聲稱近期基板技術的發展(PDF)已經能夠幫助其部署一種快速、強健的模塊通信互聯架構。從理論上來講,其帶寬可達數 TB/s 。
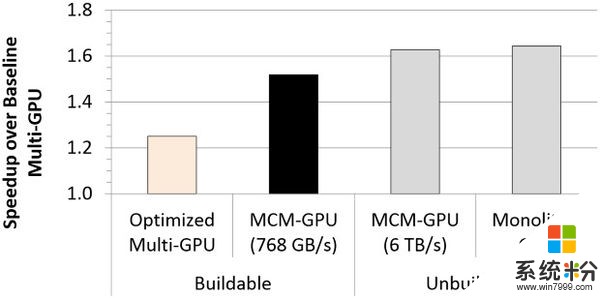
在NVIDIA內部GPU模擬中,研究團隊將 MCM-GPU 堆到了256組 SMs,而Pascal架構僅為56組SMs 。然後團隊基於當前架構進行了預測,結果顯示 MCM-GPU 可提速 45.5% 。
此外,在同一板子上進行的多GPU性能對比表明,MCM-GPU有26.8%的領先優勢。最後,有消息稱AMD公司也有類似的點子(基於Navi GPU)。




















